ĪĪĪĪī”(du©¼)ė┌CRMČ°čįŻ¼öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀Ż║
ĪĪĪĪ1. ø](m©”i)ėąūŅ║├Ą─╣żŠ▀;Ė³┤_ŪąĄžšf(shu©Ł)Ż¼ø](m©”i)ėą▀m║Ž╦∙ėą╚╦Ą─ūŅ║├Ą─╣żŠ▀ĪŻ
ĪĪĪĪ2. ūŅėąė├Ą─╣żŠ▀Ż¼╩Ū─Ūą®─▄ē“ØMūŃ─Ń╦∙ąĶꬥ─Į^┤¾ČÓöĄ(sh©┤)öĄ(sh©┤)ō■(j©┤)═┌Š“╚╬äš(w©┤)Ą─╣żŠ▀ĪŻ
ĪĪĪĪų„ꬥ─öĄ(sh©┤)ō■(j©┤)═┌Š“╚╬äš(w©┤)
ĪĪĪĪ▀^(gu©░)╚źŻ¼öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀Ą─ķ_(k©Īi)░l(f©Ī)ų„ę¬é╚(c©©)ųžė┌╠ß╣®ÅŖ(qi©óng)┤¾Ą─Ęų╬÷╦ŃĘ©╔ŽĪŻ Ą½╩ŪŻ¼Ęų╬÷“ę²Ūµ”ų╗─▄═Ļ│╔öĄ(sh©┤)ō■(j©┤)═┌Š“ĒŚ(xi©żng)─┐ųąĄ─ę╗ąĪ▓┐Ęų╚╬äš(w©┤)ĪŻ
ĪĪĪĪ┤¾ČÓöĄ(sh©┤)öĄ(sh©┤)ō■(j©┤)═┌Š“╚╦åTČ╝├„░ūŻ¼öĄ(sh©┤)ō■(j©┤)═┌Š“ĒŚ(xi©żng)─┐ųą70%ĄĮ90%Ą─╣żū„╩Ūū÷öĄ(sh©┤)ō■(j©┤)£╩(zh©│n)éõĪŻ į┌öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀Ą─č▌▀M(j©¼n)▀^(gu©░)│╠ųąŻ¼öĄ(sh©┤)ō■(j©┤)£╩(zh©│n)éõ╣”─▄Ą─ķ_(k©Īi)░l(f©Ī)ę╗ų▒▒╗Ę┼į┌┤╬ę¬╬╗ų├╔ŽĪŻ ūŅ║¾Ż¼─Ńę¬─▄ē“?q©▒)”─Żą═£?zh©│n)┤_įu(p©¬ng)╣└Ż¼▓┼─▄▒╚▌^ČÓéĆ(g©©)─Żą═Ż¼▓óīó╦³éā═Ų╦]Įo╩ął÷(ch©Żng)╚╦åTĪŻ
ĪĪĪĪöĄ(sh©┤)ō■(j©┤)£╩(zh©│n)éõ╚╬äš(w©┤)
ĪĪĪĪ│ŻęŖ(ji©żn)Ą─öĄ(sh©┤)ō■(j©┤)£╩(zh©│n)éõ╚╬äš(w©┤)░³└©Ż║
ĪĪĪĪ▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)įu(p©¬ng)╣└Ż¼ęį┼ąäe│÷Ż║
ĪĪĪĪ╚▒╩¦ųĄ(┐šūųĘ¹┤«Īó┐šĖ±Īó┐šųĄ)
ĪĪĪĪ╣┬┴ó³c(di©Żn)
ĪĪĪĪ╣▓ŠĆąįįu(p©¬ng)╣└(ūįūā┴┐ų«ķgĄ─ŽÓĻP(gu©Īn)ąį)
ĪĪĪĪĮoČ©ūā┴┐ČÓéĆ(g©©)ŠÄ┤aĄ─│÷¼F(xi©żn)Ņl┬╩
ĪĪĪĪ║Ž▓óČÓéĆ(g©©)öĄ(sh©┤)ō■(j©┤)╝»;
ĪĪĪĪÅ─▓╗═¼▌ö╚ļĖ±╩ĮĄĮ═©ė├Ęų╬÷Ė±╩ĮĄ─į¬öĄ(sh©┤)ō■(j©┤)(ūųČ╬Ą─├¹ĘQ║═ŅÉą═)ė│╔õ;
ĪĪĪĪīóŅÉ╦Ųūā┴┐Ą─ųĄūāōQ×ķ═©ė├Ė±╩Į;
ĪĪĪĪ─│ą®╦ŃĘ©ī”(du©¼)▌ö╚ļūā┴┐ėą╠ž╩Ōę¬Ū¾Ż¼ąĶę¬īóöĄ(sh©┤)ųĄą═ūā┴┐ūāōQ×ķŅÉäeą═(═©▀^(gu©░)öĄ(sh©┤)ō■(j©┤)ĘųŽõ║═ĘųŅÉ)Ż¼╗“š▀īóŅÉäeą═ūāōQ×ķöĄ(sh©┤)ųĄą═;
ĪĪĪĪīóūā┴┐ųĄŪąĘų×ķČÓéĆ(g©©)ūųČ╬Ż¼╗“?q©▒)óČÓéĆ(g©©)ūųČ╬║Ž▓ó×ķę╗éĆ(g©©)ūųČ╬;
ĪĪĪĪÅ─¼F(xi©żn)ėąūā┴┐ųą┼╔╔·ą┬ūā┴┐ĪŻ┤¾ČÓöĄ(sh©┤)öĄ(sh©┤)ō■(j©┤)═┌Š“╚╦åT░l(f©Ī)¼F(xi©żn)Ż¼ėąą®ūŅŠ▀ėąŅA(y©┤)£y(c©©)─▄┴”Ą─ūā┴┐Ż¼š²╩Ū┼╔╔·│÷üĒ(l©ói)Ą─ūā┴┐ĪŻ
ĪĪĪĪ┤¾ČÓöĄ(sh©┤)öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀Ģ■(hu©¼)░č▀@ą®öĄ(sh©┤)ō■(j©┤)═┌Š“╣”─▄Ę┼į┌┤╬ꬥ─Ąž╬╗Ż¼ ▒Š╬─ätĢ■(hu©¼)é╚(c©©)ųžįu(p©¬ng)╣└│ŻęŖ(ji©żn)öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀╠Ä└Ē▀@ą®╚╬äš(w©┤)Ą──▄┴”ĪŻ
ĪĪĪĪ│²┴╦─▄ų¦│ųęį╔ŽĄ─öĄ(sh©┤)ō■(j©┤)£╩(zh©│n)éõ╚╬äš(w©┤)Ż¼ę╗éĆ(g©©)║├Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀▀Ćæ¬(y©®ng)įō░³║¼─Żą═įu(p©¬ng)╣└Ą─╣”─▄Ż¼ęį▒Ń▒╚▌^Į©─Ż▀^(gu©░)│╠ųą«a(ch©Żn)╔·Ą─ČÓéĆ(g©©)─Żą═Ż¼▓óė├ė┌ų¦│ųų▒ą¦ĀI(y©¬ng)õN(direct marketing)ĪŻ
ĪĪĪĪ─Żą═įu(p©¬ng)╣└╣żŠ▀
ĪĪĪĪį┌Ęų╬÷└ĒšōųąŻ¼ūŅ║├Ą──Żą═╩ŪŠ▀ėąūŅ╝čŠ½Č╚Ą──Żą═Ż¼┐╔ęį£╩(zh©│n)┤_ŅA(y©┤)£y(c©©)│÷─┐ś╦(bi©Īo)ūā┴┐Ą─ŅÉäeŻ¼═¼Ģr(sh©¬)į┌“×(y©żn)ūCöĄ(sh©┤)ō■(j©┤)╝»╔Žę▓─▄▒Ē¼F(xi©żn)ĘĆ(w©¦n)Č©ĪŻ ▀@Š═╩Ūšf(shu©Ł)Ż¼į┌ŅA(y©┤)£y(c©©)ųą╬ęéāę¬┐╝æ]Ēææ¬(y©®ng)─┐ś╦(bi©Īo)║═ĘŪĒææ¬(y©®ng)─┐ś╦(bi©Īo)Ą─ĮM║ŽŠ½Č╚ĪŻ ▀@ĘNĘĮĘ©ĘQ×ķ╚½ŠųŠ½Č╚ĘĮĘ©(Global Accuracy method)ĪŻ ┤¾ČÓöĄ(sh©┤)öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀╩╣ė├▀@ĘNĘĮĘ©üĒ(l©ói)┤_Č©“ūŅ╝č”─Żą═ĪŻ Ą½╩ŪŻ¼╦³ę▓ėą├└ųą▓╗ūŃĪŻ ╚½ŠųŠ½Č╚įu(p©¬ng)╣└ĘĮĘ©Ą─▒│║¾ėąę╗éĆ(g©©)Ū░╠ß╝┘įO(sh©©)Ż¼Š═╩ŪĖ„ĘNĘųŅÉÕe(cu©░)š`Ą─┤·ār(ji©ż)╩ŪŽÓ═¼Ą─ĪŻ ▀@ĘNĘĮĘ©į┌šn╠├╔Ž▒Ē¼F(xi©żn)▓╗Õe(cu©░)Ż¼Ą½į┌īŹ(sh©¬)ļHĄ─CRMöĄ(sh©┤)ō■(j©┤)═┌Š“æ¬(y©®ng)ė├╔Žät┐╔─▄┤µį┌å¢(w©©n)Ņ}Ż¼╠žäe╩Ūį┌─Ūą®ė├ė┌ų▒Ó]ĀI(y©¬ng)õNĄ─æ¬(y©®ng)ė├╔ŽĪŻ īŹ(sh©¬)ļH╔ŽŻ¼▀@ę▓╩Ū▀^(gu©░)╚ź║▄ČÓė├CRMüĒ(l©ói)ų¦│ųų▒Ó]ĀI(y©¬ng)õNČ°╬┤─▄«a(ch©Żn)╔·├„’@╔╠śI(y©©)ār(ji©ż)ųĄĄ─ę╗éĆ(g©©)ų„ę¬įŁę“ĪŻ ī”(du©¼)─Żą═Ą─įu(p©¬ng)╣└ėąę╗ą®ų„ę¬įŁätŻ¼Č°Ųõųąų╗ėąę╗▓┐Ęų╩ŪĀI(y©¬ng)õN▓┐ķT(m©”n)šµš²ĻP(gu©Īn)ą─Ą─Ż║ ūŅ┤¾╗»─┐ś╦(bi©Īo)┐═æ¶Ą─Ēææ¬(y©®ng)┬╩Ż¼ūŅąĪ╗»╦∙ąĶ│╔▒ŠĪŻ ┤¾ČÓöĄ(sh©┤)öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀Č╝░čūóęŌ┴”╝»ųąį┌ŅA(y©┤)£y(c©©)Ą─ĮM║ŽŠ½Č╚╔ŽŻ¼ģs═Ļ╚½║÷┬į┴╦│╔▒ŠĄ─ę“╦žĪŻ
ĪĪĪĪį┌ų▒ą¦ĀI(y©¬ng)õN╗Ņäė(d©░ng)ųąŻ¼Ž“╬┤Ēææ¬(y©®ng)Ą─Øōį┌┐═æ¶(ĘQ×ķ“Õe(cu©░)š`┐ŽČ©”Õe(cu©░)š`Ż¼false-positive)░l(f©Ī)╦═Ó]╝■Ą─│╔▒Š╩ŪŽÓ«ö(d©Īng)?sh©┤)═Ą?Č°╚ń╣¹ę╗éĆ(g©©)Øōį┌┐═æ¶┐╔─▄Ģ■(hu©¼)Ēææ¬(y©®ng)(ĘQ×ķ“Õe(cu©░)š`ʱȩ”Õe(cu©░)š`Ż¼false-negative)Ż¼─Ńģsø](m©”i)ėąŽ“╦¹░l(f©Ī)╦═Ó]╝■Ż¼─Ū├┤▀@éĆ(g©©)┤·ār(ji©ż)Š═ŽÓ«ö(d©Īng)┤¾┴╦(ę“?y©żn)ķø](m©”i)ėą░č╦¹░l(f©Ī)š╣×ķ┐═æ¶Ż¼─·Ģ■(hu©¼)ōp╩¦╦¹╦∙└U╝{Ą─Ģ■(hu©¼)åT┘M(f©©i)Ż¼Č°Ūę╦¹ę▓▓╗┐╔─▄┘Å(g©░u)┘I─·Ą─Ųõ╦³Ę■äš(w©┤))ĪŻ ę“┤╦į┌ų▒õNĀI(y©¬ng)õN─Żą═Ą─įu(p©¬ng)╣└ųąŻ¼Š═æ¬(y©®ng)įō▒M┴┐ūŅąĪ╗»Õe(cu©░)š`ʱȩĄ─Õe(cu©░)š`Ż¼Č°▓╗╩ŪÕe(cu©░)š`┐ŽČ©ĪŻ ę“?y©żn)ķĀI(y©¬ng)õN▓┐ķT(m©”n)ų╗ĻP(gu©Īn)ūóĒææ¬(y©®ng)┬╩║═│╔▒ŠŻ¼╚ń╣¹Ū░30%Ą─┐═æ¶├¹å╬ųą░³║¼┴╦╚½¾wĒææ¬(y©®ng)š▀Ą─60%Ż¼Š═┐╔ęįØMūŃ╦¹éāĄ─ąĶŪ¾ĪŻ ī”(du©¼)ė┌ų▒õNĀI(y©¬ng)õNüĒ(l©ói)šf(shu©Ł)Ż¼▒M╣▄Ū░30%Ą─┐═æ¶╚įĢ■(hu©¼)ėą▓┐Ęų╚╦▓╗Ģ■(hu©¼)Ēææ¬(y©®ng)(Õe(cu©░)š`┐ŽČ©Õe(cu©░)š`)Ż¼Ž“╦¹éā░l(f©Ī)╦═Ó]╝■ę└╚╗╩ŪųĄĄ├Ą─ĪŻ─Ū╩Ūę“?y©żn)ķ╬ęéāęčĮ?j©®ng)┬ō(li©ón)ŽĄ┴╦╚½¾wĒææ¬(y©®ng)š▀ųąĄ─60%ĪŻ ┤╦Ģr(sh©¬)Š═▒╚ļSÖC(j©®)░l(f©Ī)Ó]╝■Ą─ėąą¦ąį╠ßĖ▀┴╦ę╗▒ČŻ¼ę▓Š═Ė³╝ė║Ž╦ŃĪŻ
ĪĪĪĪ┤¾ČÓöĄ(sh©┤)öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀Č╝╩╣ė├╚½ŠųŠ½Č╚ĘĮĘ©üĒ(l©ói)▀M(j©¼n)ąą─Żą═įu(p©¬ng)╣└ĪŻ ╦³éā┐╔─▄Ģ■(hu©¼)ę¬Ū¾─Ń╩╣ė├▀@ĘNĘĮĘ©Ż¼═©▀^(gu©░)╣żŠ▀Ą─ł¾(b©żo)▒Ē╣”─▄üĒ(l©ói)ūR(sh©¬)äe│÷“ūŅ╝č”─Żą═ĪŻ ▓╗═¼╦ŃĘ©Ģ■(hu©¼)«a(ch©Żn)╔·ČÓéĆ(g©©)─Żą═Ż¼╬ęéā▓╗æ¬(y©®ng)įōų╗╩Ū▓ķ┐┤╣żŠ▀╠ß╣®Ą─Š½Č╚ł¾(b©żo)ĖµŻ¼║å(ji©Żn)å╬▒╚▌^║¾Š═┼ąäe──éĆ(g©©)╩ŪūŅ╝čĄ──Żą═ĪŻ īŹ(sh©¬)ļH╔ŽŻ¼Ė³║Ž▀mĄ─įu(p©¬ng)╣└æ¬(y©®ng)įōĖ∙ō■(j©┤)╚ńŽ┬Śl╝■üĒ(l©ói)ū÷│÷Ż║░┤ššŅA(y©┤)£y(c©©)Ė┼┬╩ųĄĒśą“┼┼┴ą─Żą═ĮY(ji©”)╣¹Ż¼╔·│╔įu(p©¬ng)Ęų┴ą▒ĒŻ¼╚╗║¾┐┤šµš²Ą─Ēææ¬(y©®ng)š▀╩Ūʱ▒╗Ę┼į┌ūŅŪ░├µĄ─ĘųČ╬ųąĪŻ ▒M╣▄ĘųŅÉ╦ŃĘ©┐╔ęį▌ö│÷ĘųŅÉĖ┼┬╩Ż¼ īŹ(sh©¬)ļHĄ─ŅÉäe(└²╚ńŻ¼0╗“1)▀Ć╩Ūī”(du©¼)ĘųŅÉĖ┼┬╩Ą─▀M(j©¼n)ę╗▓ĮÜw╝{(└²╚ńŻ¼<0.5 = 0; ≥ 0.5 = 1)ĪŻ ┤¾┴┐šµš²Ą─“ĮēK”ļ[▓žį┌öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀Ą─╣”─▄─ŻēKų«ųąĪŻ │§╝ē(j©¬)Ą─CRM═┌Š“╚╦åTĢ■(hu©¼)░čūóęŌ┴”Ę┼į┌ĘųŅÉ║═Š½Č╚╔Ž├µŻ¼Ą½šµš²Ą─“ĮēK”æ¬(y©®ng)įō╩Ū┐═æ¶▒Ż│ųĪó┘Å(g©░u)┘IāAŽ“ęį╝░ą┬┐═涽@╚ĪĄ─Ė┼┬╩ųĄĪŻ
ĪĪĪĪ╬ęéāæ¬(y©®ng)įō▓ķ┐┤└█Ęe╠ß╔²▒Ē(cumulative lift table;└²╚ń▒Ē1)Ż¼üĒ(l©ói)┼ąäe─Żą═╩Ūʱšµš²ėąą¦Ąž░čš²┤_┐ŽČ©(true-positives)Ę┼į┌┴╦┐┐Ū░Ą─ĘųĮM└’ĪŻ └█Ęe╠ß╔²▒Ē┐╔ęį═©▀^(gu©░)ęįŽ┬ĘĮ╩Įäō(chu©żng)Į©Ż║
ĪĪĪĪ1ĪóŅA(y©┤)£y(c©©)Ė┼┬╩ųĄ░┤ĮĄą“ĘĮ╩Į┤µā”(ch©│)×ķėąą“┴ą▒Ē
ĪĪĪĪ2Īó░č▀@éĆ(g©©)ėąą“┴ą▒ĒäØĘų×ķ10Č╬(ĘųĮM)
ĪĪĪĪ3Īóėŗ(j©¼)╦Ń├┐ĮMųąĄ─īŹ(sh©¬)ļH├³ųąöĄ(sh©┤)(actual hitsŻ¼īŹ(sh©¬)ļHĄ─Ēææ¬(y©®ng)öĄ(sh©┤))
ĪĪĪĪ4Īóėŗ(j©¼)╦Ń├┐éĆ(g©©)ĘųĮMĄ─ļSÖC(j©®)Ų┌═¹ųĄ(random expectation)Ż¼įōŲ┌═¹ųĄĄ╚ė┌īŹ(sh©¬)ļHĒææ¬(y©®ng)┐éöĄ(sh©┤)│²ęį10ĪŻę▓Š═╩Ūšf(shu©Ł)Ż¼į┌├┐éĆ(g©©)ĘųĮMųą╬ęéāŲ┌═¹Ģ■(hu©¼)ėąīŹ(sh©¬)ļHĒææ¬(y©®ng)┐éöĄ(sh©┤)Ą─10%Ģ■(hu©¼)Ēææ¬(y©®ng)ĪŻ ╚ń╣¹├³ųą┬╩│¼▀^(gu©░)┴╦ļSÖC(j©®)Ų┌═¹ųĄŻ¼Š═ęŌ╬Čų°─Żą═×ķįōĘųĮMĦüĒ(l©ói)┴╦╠ß╔²
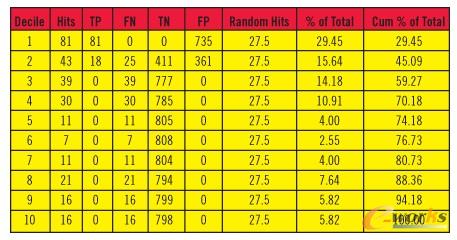
▒Ē1Ż║ ╠ß╔²▒Ē
ĪĪĪĪūgš▀ūóŻ║
ĪĪĪĪDecile-ĘųĮMą“╠¢(h©żo);Hits-├³ųąöĄ(sh©┤)Ż¼╝┤├┐ĮMā╚(n©©i)░³║¼Ą─īŹ(sh©¬)ļHĒææ¬(y©®ng)öĄ(sh©┤)Ż¼Ą╚ė┌TP+FN;
ĪĪ
ĪĪĪĪTP-š²┤_┐ŽČ©;FN-Õe(cu©░)š`ʱȩ;TN-š²┤_ʱȩ;FP-Õe(cu©░)š`┐ŽČ©;
ĪĪĪĪ(TP║═FNī”(du©¼)æ¬(y©®ng)ė┌īŹ(sh©¬)ļHĄ─Ēææ¬(y©®ng)Ż¼TN║═FPī”(du©¼)æ¬(y©®ng)ė┌īŹ(sh©¬)ļHĄ─ĘŪĒææ¬(y©®ng))
ĪĪĪĪRandom Hits-ļSÖC(j©®)├³ųąöĄ(sh©┤)Ż¼╝┤ļSÖC(j©®)Ų┌═¹ųĄŻ¼Ą╚ė┌SUM(TP+FN)/10;
ĪĪĪĪ% of Total-š┘╗ž┬╩Ż¼Ą╚ė┌Hits/SUM(Hits)*100;
ĪĪĪĪCum % of Total-└█Ęeš┘╗ž┬╩Ż¼╩Ū% of TotalĄ─└█ĘeųĄĪŻ
ĪĪĪĪę╗╣▓äØĘų┴╦10éĆ(g©©)ĘųĮMŻ¼īŹ(sh©¬)ļHĄ─┐éĒææ¬(y©®ng)öĄ(sh©┤)×ķSUM(Hits)=275Ż¼ę“┤╦├┐ĮMĄ─ļSÖC(j©®)Ų┌═¹ųĄ×ķ275/10=27.5ĪŻĄ┌ę╗ĮMĄ─├³ųąöĄ(sh©┤)×ķ81Ż¼├„’@│¼▀^(gu©░)┴╦ļSÖC(j©®)Ų┌═¹ųĄŻ¼Ųõš┘╗ž┬╩=81/275=29.45%ĪŻĄ┌Č■ĮMĄ─├³ųąöĄ(sh©┤)×ķ43Ż¼ę▓│¼▀^(gu©░)┴╦ļSÖC(j©®)Ų┌═¹ųĄŻ¼Ųõš┘╗ž┬╩×ķ43/275=15.64%Ż¼└█Ęeš┘╗ž┬╩Ą╚ė┌Ą┌Č■ĮMĄ─š┘╗ž┬╩╝ė╔ŽŪ░├µ╦∙ėąĮM(╝┤Ą┌ę╗ĮM)Ą─š┘╗ž┬╩Ż¼Ą╚ė┌15.64%+29.45%=45.09%ĪŻ
ĪĪĪĪÅ─╔Ž▒Ēųą┐╔ęį┐┤│÷Ż¼įō─Żą═äØĘų┐ŽČ©║═ʱȩĄ─ķōųĄæ¬(y©®ng)įō╩Ūį┌Ą┌Č■éĆ(g©©)ĘųĮMųąŻ¼▀@śė▓┼│÷¼F(xi©żn)┴╦Ą┌ę╗ĮMČ╝▒╗ŅA(y©┤)£y(c©©)×ķ┐ŽČ©Ż¼Ą½Ųõųąėą81éĆ(g©©)╩Ūš²┤_Ą─┐ŽČ©(TP)Ż¼Č°735éĆ(g©©)╩ŪÕe(cu©░)š`Ą─┐ŽČ©(FP);Ą┌Č■ĮMųąät═¼Ģr(sh©¬)░³║¼┴╦TPĪóFNĪóTN║═FP;Å─Ą┌╚²ĮMų«║¾ätČ╝▒╗ŅA(y©┤)£y(c©©)×ķʱȩ(ę“?y©żn)ķ╬╗ė┌ķōųĄų«Ž?Ż¼ę“┤╦░³║¼┴╦FN║═TNĪŻ
ĪĪĪĪš²┤_┐ŽČ©(True-PositivesŻ¼TP)Ż║ īŹ(sh©¬)ļHĄ─Ēææ¬(y©®ng)ųąŻ¼▒╗š²┤_ŅA(y©┤)£y(c©©)×ķĒææ¬(y©®ng)Ą─éĆ(g©©)öĄ(sh©┤)
ĪĪĪĪÕe(cu©░)š`ʱȩ(False-NegativesŻ¼F(xi©żn)N)Ż║ īŹ(sh©¬)ļHĄ─Ēææ¬(y©®ng)ųąŻ¼▒╗Õe(cu©░)š`ŅA(y©┤)£y(c©©)×ķĘŪĒææ¬(y©®ng)Ą─éĆ(g©©)öĄ(sh©┤)
ĪĪĪĪš²┤_ʱȩ(True-NegativesŻ¼TN)Ż║ īŹ(sh©¬)ļHĄ─ĘŪĒææ¬(y©®ng)ųąŻ¼▒╗š²┤_ŅA(y©┤)£y(c©©)×ķĘŪĒææ¬(y©®ng)Ą─éĆ(g©©)öĄ(sh©┤)
ĪĪ
ĪĪĪĪÕe(cu©░)š`┐ŽČ©(False-PositivesŻ¼F(xi©żn)P)Ż║ īŹ(sh©¬)ļHĄ─ĘŪĒææ¬(y©®ng)ųąŻ¼▒╗Õe(cu©░)š`ŅA(y©┤)£y(c©©)×ķĒææ¬(y©®ng)Ą─éĆ(g©©)öĄ(sh©┤)
ĪĪĪĪ═©▀^(gu©░)ī”(du©¼)╠ß╔²▒ĒĄ─Ęų╬÷┐╔ęį┐┤ĄĮŻ¼į┌Ą┌╦─éĆ(g©©)ĘųČ╬ų«║¾Ż¼į÷┴┐╠ß╔²(incremental liftŻ¼Ą┌8┴ąųąĄ─”% of Total”)Ž┬ĮĄĄĮļSÖC(j©®)Ų┌═¹(├┐éĆ(g©©)ĘųČ╬×ķ10%)ų«Ž┬Ż¼Č°Ū░╦─éĆ(g©©)ĘųČ╬░³║¼┴╦│¼▀^(gu©░)70%Ą─Ēææ¬(y©®ng)ĪŻ Å─Ž┬├µĄ─į÷┴┐╠ß╔²Ū·ŠĆ(łD1)ųą┐╔ęį├„’@┐┤│÷į÷┴┐╠ß╔²║═ļSÖC(j©®)Ų┌═¹Ą─Į╗▓µ³c(di©Żn)ĪŻ
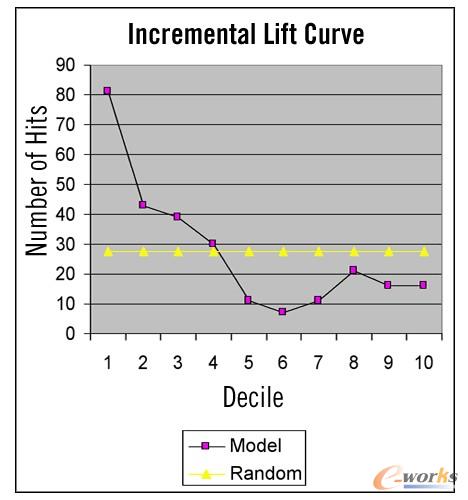
ĪĪĪĪłD1Ż║ į÷┴┐╠ß╔²łD╩Š└²
ĪĪĪĪį┌į÷┴┐╠ß╔²Ū·ŠĆųąś╦(bi©Īo)╩Š┴╦Ė„éĆ(g©©)ĘųČ╬Ą─├³ųąöĄ(sh©┤)ĪŻ į┌łD1ųą┐╔ęį┐┤ĄĮŻ¼į÷┴┐╠ß╔²Ū·ŠĆį┌Ą┌4éĆ(g©©)ĘųČ╬║¾║═ļSÖC(j©®)Ų┌═¹ŠĆ(275éĆ(g©©)Ēææ¬(y©®ng)Ą─10%Ż¼╝┤ŲĮŠ∙├┐éĆ(g©©)ĘųČ╬27.5éĆ(g©©)Ēææ¬(y©®ng))Į╗▓µĪŻ ▓╗╣▄ĀI(y©¬ng)õNĮø(j©®ng)└Ēį§├┤╚ź┐┤Ż¼╔Ž╩÷Ą─▒ĒĖ±║═łDą╬Č╝┐╔ęį░č▒žę¬Ą─ą┼Žóé„▀fĮo╦¹éāĪŻ ĀI(y©¬ng)õN╚╦åT┐╔ęįĮĶų·─Żą═įu(p©¬ng)╣└╣żŠ▀Ż¼üĒ(l©ói)įO(sh©©)Č©ę¬ĮoČÓ╔┘éĆ(g©©)┐═æ¶░l(f©Ī)Ó]╝■ĪŻ ęį▒Ē1×ķ└²Ż¼ĀI(y©¬ng)õN╚╦åT┐╔ęįŽ“Ū░╦─éĆ(g©©)ĘųČ╬Ą─┐═æ¶(š╝š¹éĆ(g©©)įu(p©¬ng)Ęų├¹å╬Ą─40%)░l(f©Ī)Ó]╝■Ż¼▓óŅA(y©┤)Ų┌┐╔ęį├³ųą70%Ą─Øōį┌Ēææ¬(y©®ng)┐═æ¶ĪŻ
ĪĪĪĪ╬ęéā¼F(xi©żn)į┌ęčĮø(j©®ng)┴╦ĮŌįō╚ń║╬įu(p©¬ng)╣└öĄ(sh©┤)ō■(j©┤)═┌Š“─Żą═Ż¼ĮėŽ┬üĒ(l©ói)Š═┐╔ęį╔Ņ╚ļĘų╬÷║═š{(di©żo)š¹śI(y©©)äš(w©┤)┴„│╠Ż¼ĮĶų·─Żą═Ą─ĮY(ji©”)╣¹üĒ(l©ói)╠ßĖ▀Ų¾śI(y©©)Ą─ė»└¹ĪŻ śI(y©©)äš(w©┤)┴„│╠░³└©Ż║
ĪĪĪĪ1ĪóöĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠
ĪĪĪĪ2Īóų¬ūR(sh©¬)░l(f©Ī)¼F(xi©żn)▀^(gu©░)│╠
ĪĪĪĪ3ĪóśI(y©©)äš(w©┤)┴„│╠╣▄└Ē(BPM)▄ø╝■
ĪĪĪĪ4Īóų¬ūR(sh©¬)╣▄└ĒŽĄĮy(t©»ng)
ĪĪĪĪ5Īó╔╠śI(y©©)╔·æB(t©żi)ŽĄĮy(t©»ng)╣▄└Ē
ĪĪĪĪöĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠
ĪĪĪĪEric Kingį┌“╚ń║╬į┌öĄ(sh©┤)ō■(j©┤)═┌Š“╔Ž═Č┘YŻ║▒▄├ŌŅA(y©┤)£y(c©©)ą═Ęų╬÷ųą░║┘FĄ─ĒŚ(xi©żng)─┐Ž▌┌ÕĄ─┐“╝▄”ę╗╬─(░l(f©Ī)▒Ēė┌2005─Ļ10į┬Ą─“DM Review”)ųąų„ÅłöĄ(sh©┤)ō■(j©┤)═┌Š“╩Ūę╗Č╬┬├│╠Ż¼Č°ĘŪĮK³c(di©Żn)ĪŻ╦¹░č▀@Č╬┬├│╠Č©┴x×ķöĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠ĪŻ įō▀^(gu©░)│╠░³║¼╚ńŽ┬ę¬╦žŻ║
ĪĪĪĪ1Īóę╗éĆ(g©©)░l(f©Ī)¼F(xi©żn)▀^(gu©░)│╠
ĪĪĪĪ2ĪóŠ▀ėąņ`╗ŅĄ─┐“╝▄
ĪĪĪĪ3Īó░┤ššŪÕ╬·Č©┴xĄ─▓▀┬į▀M(j©¼n)ąą
ĪĪĪĪ4Īó░³║¼ČÓéĆ(g©©)Öz▓ķ³c(di©Żn)
ĪĪĪĪ5ĪóČÓ┤╬Č©Ų┌Ą─įu(p©¬ng)╣└
ĪĪĪĪ6Īóį╩įSį┌Ę┤üŁh(hu©ón)┬Ęųąī”(du©¼)║»öĄ(sh©┤)▀M(j©¼n)ąąš{(di©żo)š¹
ĪĪĪĪ7ĪóĮM┐Ś×ķ»B┤·╩ĮĄ─╝▄śŗ(g©░u)
ĪĪĪĪ▀^(gu©░)│╠─Żą═
ĪĪĪĪ║▄ČÓöĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀Ą─ÅS╔╠Č╝ī”(du©¼)▀@éĆ(g©©)▀^(gu©░)│╠▀M(j©¼n)ąą┴╦║å(ji©Żn)╗»Ż¼╩╣ų«Ė³╝ėŪÕ╬·ĪŻ SASīóöĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠äØĘų×ķ╬ÕéĆ(g©©)ļAČ╬Ż║ │ķśė(Sample)Ż¼ĮŌßī(Explain)Ż¼╠Ä└Ē(Manipulate)Ż¼Į©─Ż(Model)Ż¼įu(p©¬ng)╣└(Assess)ĪŻ ▀^(gu©░)╚ź╚╦éā│Żė├裣h(hu©ón)╩ĮĄ─’ŗ╦«Ų„üĒ(l©ói)▒╚ė„öĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠ĪŻ ╦«(öĄ(sh©┤)ō■(j©┤))╩ūŽ╚ė┐╔ŽĄ┌ę╗īė(Ęų╬÷ļAČ╬)Ż¼ą╬│╔õ÷£u(Š½¤Æ║═Ę┤ü)Ż¼Ą╚ĄĮŠ█Ęe┴╦ūŃē“ČÓ“ęčĮø(j©®ng)╠Ä└Ē▀^(gu©░)”Ą─╦«ų«║¾Ż¼Š═ęń│÷üĒ(l©ói)┴„ĄĮŽ┬ę╗éĆ(g©©)Ė³Ą═Ą─īėųąĪŻ ▓╗öÓĄž▀M(j©¼n)ąą▀@ĘN“╠Ä└Ē”Ż¼ų▒ĄĮ╦«┴„ĄĮūŅĄ═īėĪŻį┌─Ū└’╦³▒╗│ķ╗žĒöīėŻ¼ķ_(k©Īi)╩╝ą┬ę╗▌åĄ─“╠Ä└Ē”ĪŻ öĄ(sh©┤)ō■(j©┤)═┌Š“║═▀@ĘNīė┤╬╩ĮĄ─»B┤·▀^(gu©░)│╠ĘŪ│ŻŽÓŽ±ĪŻ ╔§ų┴į┌║▄ČÓöĄ(sh©┤)ō■(j©┤)═┌Š“╦ŃĘ©Ą─ā╚(n©©i)▓┐╠Ä└Ēę▓╩Ū╚ń┤╦Ż¼▒╚╚ń╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)╦ŃĘ©Ż¼Š═╩Ūį┌öĄ(sh©┤)ō■(j©┤)╝»╔ŽČÓ┤╬▀\(y©┤n)ąą(epochs)Ż¼ų▒ų┴░l(f©Ī)¼F(xi©żn)ūŅā×(y©Łu)ĮŌĪŻ Insightful MineręčĮø(j©®ng)į┌Ųõė├æ¶Įń├µųąā╚(n©©i)Į©┴╦║å(ji©Żn)å╬▀^(gu©░)│╠─Żą═ĪŻ ▀@ĘN╝»│╔┐╔ęįÄ═ų·ė├æ¶░č▒žę¬Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“╚╬äš(w©┤)ĮM┐ŚŲüĒ(l©ói)Ż¼ūī╚╬äš(w©┤)─▄ē“░┤ššš²┤_Ą─Ēśą“üĒ(l©ói)╠Ä└ĒĪŻ
ĪĪĪĪĄ½╩╣ė├’ŗ╦«Ų„üĒ(l©ói)▒╚ė„öĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠▀Ć▓╗╦ŃŪĪ«ö(d©Īng)Ż¼ę“?y©żn)ķ╦³ø](m©”i)ėąĘ┤ė││÷Ę┤üŁh(hu©ón)┬ĘŻ¼Č°Ę┤üŁh(hu©ón)┬Ęį┌öĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠ųą╩Ū║▄│ŻęŖ(ji©żn)Ą─ĪŻ └²╚ńŻ¼═©▀^(gu©░)öĄ(sh©┤)ō■(j©┤)įu(p©¬ng)╣└┐╔ęį░l(f©Ī)¼F(xi©żn)«É│ŻĄ─öĄ(sh©┤)ō■(j©┤)Ż¼Å─Č°ę¬Ū¾Å─į┤ŽĄĮy(t©»ng)ųą│ķ╚ĪĖ³ČÓĄ─öĄ(sh©┤)ō■(j©┤)ĪŻ ╗“š▀Ż¼į┌Į©─Żų«║¾Ż¼Ģ■(hu©¼)░l(f©Ī)¼F(xi©żn)ąĶę¬Ė³ČÓĄ─ėøõø▓┼─▄Ę┤ė│┐é¾wĄ─Ęų▓╝ĪŻ
ĪĪĪĪį┌CRISP▀^(gu©░)│╠─Żą═ųą▀M(j©¼n)ąą┴╦ĮŌøQ▀@éĆ(g©©)å¢(w©©n)Ņ}Ą─ćLįćŻ¼įō─Żą═╩Ūė╔Daimler-BenzĪóISL (ClementineĄ─ķ_(k©Īi)░l(f©Ī)š▀)║═NCR╣▓═¼ųŲČ©Ą─ĪŻ CRISP═¼Ģr(sh©¬)ę▓▒╗╝»│╔ĄĮClementine═┌Š“╣żŠ▀(¼F(xi©żn)į┌ī┘ė┌SPSS╣½╦Š)Ą─įO(sh©©)ėŗ(j©¼)ųąĪŻ CRISPÄū║§Ę┤ė│┴╦═Ļš¹Ą─öĄ(sh©┤)ō■(j©┤)═┌Š“Łh(hu©ón)Š│ĪŻ
ĪĪĪĪ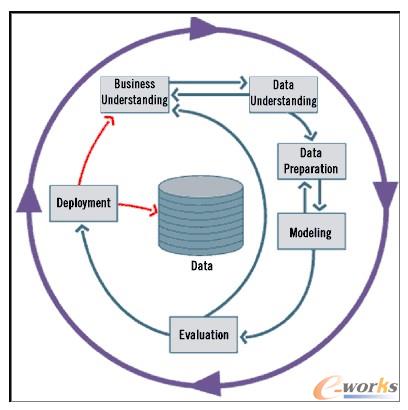
łD2Ż║ CRISPłD└²
ĪĪĪĪ╩╣ė├öĄ(sh©┤)ō■(j©┤)Į©─ŻŲõīŹ(sh©¬)║═ū÷╠š═┴─Żą═╗“š▀┤¾└Ē╩»─Żą═▓Ņ▓╗ČÓĪŻ ╦ćąg(sh©┤)╝ę╩ūŽ╚Å─ę╗┤¾Čč▓─┴Žķ_(k©Īi)╩╝ų°╩ųŻ¼Įø(j©®ng)▀^(gu©░)įSČÓ┤╬Ą─╝ė╣ż║═Öz▓ķŻ¼▓┼šQ╔·┴╦ūŅĮKĄ─╦ćąg(sh©┤)ŲĘĪŻ║▄ČÓ╚╦į┌Į©─Ż▀^(gu©░)│╠ųą│Ż│Żø](m©”i)ėą│õĘų└ĒĮŌĮ©─ŻĄ─▒Š┘|(zh©¼)Ż¼ė╔┤╦ĦüĒ(l©ói)┴╦ę╗ŽĄ┴ąå¢(w©©n)Ņ}Ż¼╩╣Ą├Į©─ŻūāĄ├║▄Å═(f©┤)ļsĪŻ Eric King░l(f©Ī)¼F(xi©żn)öĄ(sh©┤)ō■(j©┤)═┌Š“╩Ūę╗éĆ(g©©)裣h(hu©ón)Ą─▀^(gu©░)│╠(Š═Ž¾╔ŽłDųąĄ─CRISP┴„│╠łD)Ż¼Č°ĘŪŠĆąįĄ─▀^(gu©░)│╠ĪŻ ▀@ĘN裣h(hu©ón)╩ĮĄ─öĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠Ģ■(hu©¼)ūī─·ŽļŲWankel▐D(zhu©Żn)╩ĮŲ¹▄ć░l(f©Ī)äė(d©░ng)ÖC(j©®)ĪŻ ▀@ĘN░l(f©Ī)äė(d©░ng)ÖC(j©®)╩Ūę╗╚”ę╗╚”ą²▐D(zhu©Żn)Ą─(Č°ĘŪ╔ŽŽ┬▀\(y©┤n)äė(d©░ng))Ż¼▓╗öÓ▌ö│÷äė(d©░ng)─▄üĒ(l©ói)“ī(q©▒)äė(d©░ng)Ų¹▄ćĪŻ ┼cų«ŽÓ╦ŲŻ¼öĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠ę▓╩Ū▓╗öÓ裣h(hu©ón)Ż¼«a(ch©Żn)╔·ą┼ŽóüĒ(l©ói)Ä═ų·╬ęéā═Ļ│╔╔╠śI(y©©)─┐ś╦(bi©Īo)ĪŻ ą┼ŽóŠ═╩Ū═Ųäė(d©░ng)╔╠śI(y©©)Ą─“─▄┴┐”ĪŻ į┌═┌Š“▀^(gu©░)│╠ųąĢ■(hu©¼)ėą║▄ČÓī”(du©¼)Ū░ę╗éĆ(g©©)ļAČ╬Ą─Ę┤ü(└²╚ńŻ¼į┌═Ļ│╔│§▓ĮĮ©─Żų«║¾┐╔─▄ąĶę¬½@╚ĪĖ³ČÓĄ─öĄ(sh©┤)ō■(j©┤))ĪŻ
ĪĪĪĪ▓╗▀^(gu©░)Ż¼į┌CRISP┴„│╠ųą▀Ć╩Ū▀z┬®┴╦ę╗éĆ(g©©)ę¬╦ž——─ŪŠ═╩Ūī”(du©¼) öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)╗“į┤ŽĄĮy(t©»ng)Ą─Ę┤üĪŻ Ū░ę╗┤╬CRMĀI(y©¬ng)õN╗Ņäė(d©░ng)Ą─ĮY(ji©”)╣¹æ¬(y©®ng)įōī¦(d©Żo)╚ļöĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)Ż¼×ķ║¾└m(x©┤)Ą─Į©─Ż╠ß╣®ųĖī¦(d©Żo)Ż¼▓ó─▄Ė·█ÖĀI(y©¬ng)õN╗Ņäė(d©░ng)ķgĄ─ūā╗»┌ģä▌(sh©¼)ĪŻ ╬ęį┌CRISP┴„│╠łDųą╝ė╚ļ┴╦▀@ą®Ę┤üŻ¼ęį╝tŠĆ▒Ē╩Š(ęŖ(ji©żn)łD2)ĪŻ
ĪĪĪĪ═©▀^(gu©░)öĄ(sh©┤)ō■(j©┤)═┌Š“▀^(gu©░)│╠Ą─ĮY(ji©”)śŗ(g©░u)Ż¼╬ęéā┐╔ęįĄ├ų¬öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀▒žąĶ─▄═Ļ│╔─Ūą®╚╬äš(w©┤)Ż¼Ą½╩Ū╣żŠ▀│Ż│ŻĢ■(hu©¼)╚▒╔┘ī”(du©¼)▓┐Ęų╣”─▄Ą─ų¦│ųĪŻ «ö(d©Īng)«a(ch©Żn)╔·┴╦═┌Š“ĮY(ji©”)╣¹Ģr(sh©¬)Ż¼─ŃĢ■(hu©¼)į§├┤╩╣ė├▀@ą®ĮY(ji©”)╣¹─ž? ┤╦═ŌŻ¼ßśī”(du©¼)═┌Š“ĮY(ji©”)╣¹╦∙▓╔╚ĪĄ─▀@ą®ąąäė(d©░ng)ėųīó╚ń║╬ė░Ēæ║¾└m(x©┤)Ą─═┌Š“? öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀æ¬(y©®ng)įōŠ▀éõĄ─ę╗ą®╣”─▄░³└©Ż║
ĪĪĪĪ1Īóīó─Żą═ī¦(d©Żo)│÷ĄĮČÓĘNöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ĮY(ji©”)śŗ(g©░u)ųą
ĪĪĪĪ2Īó─Żą═Ą─ī¦(d©Żo)│÷Ė±╩ĮŻ¼▀m║Žė┌øQ▓▀ų¦│ų║═╔╠śI(y©©)ąąäė(d©░ng)Ą─æ¬(y©®ng)ė├
ĪĪĪĪ3Īó═┌Š“╦ŃĘ©Ą─▌ö│÷öĄ(sh©┤)ō■(j©┤)Ż¼┐╔ęį×ķ┴Ē═ŌĄ─╦ŃĘ©╦∙ė├
ĪĪĪĪ4Īó─▄ē“▒╚▌^▓╗═¼╦ŃĘ©Ą─ĮY(ji©”)╣¹
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_(t©ói)╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N(y©┤n)║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšł(q©½ng)ūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.hanmeixuan.com/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║öĄ(sh©┤)ō■(j©┤)═┌Š“╣żŠ▀Ż║šl(shu©¬)ūŅ▀m║ŽCRM
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.hanmeixuan.com/html/consultation/10819412587.html



▀xą═ųąą─")
¾w“×(y©żn)ųąą─")
«a(ch©Żn)ŲĘ┘Å(g©░u)┘I")
æ(zh©żn)┬į║Žū„")