į┌AIĢr┤·Ż¼╬ęéāŽŻ═¹ėŗ╦ŃÖC─▄ē“ōĒėąęĢėXĪó┬ĀėXĪóąąäėęį╝░šZčįĄ─ųŪ─▄Ż¼Č°ŽÓī”ė┌┬Ā║═┐┤ęį╝░ąąäėŻ¼šZčį╩Ū╬ęéā╚╦ŅÉģ^äeė┌Ųõ╦¹äė╬’Ą─ūŅųžę¬╠žš„ų«ę╗ĪŻšZčį╩Ū╬ęéā╦╝ŠSĄ─▌d¾wŻ¼ę▓ę“┤╦╬ęéāī”ė┌šZčįĄ─└ĒĮŌ║═╠Ä└ĒŻ¼ūāĄ├ė╚×ķųžę¬ĪŻČ°į┌ėŗ╦ŃÖCŅIė“Ż¼ūį╚╗šZčį╠Ä└ĒŻ©NLP, Natural Language ProcessingŻ®Š═╩Ū蹊┐╚ń║╬ūīėŗ╦ŃÖC└ĒĮŌ▓ó╔·│╔╚╦ŅÉĄ─šZčįŻ¼Å─Č°║═╚╦ŅÉŲĮĄ╚┴„Ģ│Ąž£Ž═©Į╗┴„ĪŻūį╚╗šZčį╠Ä└Ē╝╝ąg į┌░┘Č╚ęčĮøėąėŲŠ├Ą─Üv╩ĘŻ¼įńį┌░┘Č╚šQ╔·ų«ĢrŠ═│╔×ķ╦č╦„╝╝ągĄ─ųžę¬ĮM│╔▓┐ĘųŻ¼ę╗ų▒░ķļSų°░┘Č╚Ą─░lš╣Č°▀M▓ĮĪŻÅ─ųą╬─Ęųį~Īóį~ąįĘų╬÷ĪóĖ─īæŻ¼ĄĮÖCŲ„ĘŁūgĪóŲ¬š┬Ęų╬÷ĪóšZ┴x└ĒĮŌĪóī”įÆŽĄĮyĄ╚Ą╚Ż¼NLP╝╝ągęč│╔╣”æ¬ė├į┌░┘Č╚Ė„ŅÉ«aŲĘųąĪŻ
Į³Ų┌ė╔░┘Č╚ķ_░lš▀ųąą─ų„▐kĪóśO┐═░Ņ┐Ų╝╝│ą▐kĄ─75Ų┌░┘Č╚╝╝ąg╔│²ł╔ŽŻ¼░┘Č╚NLP║═AIķ_Ę┼ŲĮ┼_Ą─ČÓ╬╗┘Y╔Ņ╣ż│╠Ĥ║═«aŲĘĮø└ĒŻ¼ßśī”ķ_░lš▀╚ń║╬└¹ė├░┘Č╚NLP╝╝ągĖ³║├ĮŌøQīŹļHæ¬ė├å¢Ņ}Ż¼▀Mąą┴╦Š▀¾wĘųŽĒĪŻ░┘Č╚AI╝╝ąg╔·æB▓┐Ė▀╝ē▀\ĀIŅÖå¢ÅłōPŻ¼═©▀^Š▀¾wæ¬ė├░Ė└²Ż¼ūī┤¾╝ęī”░┘Č╚NLPķ_Ę┼Ą─║╦ą─╝╝ągėąę╗éĆĖąąįĄ─šJų¬Ż╗ūį╚╗šZčį╠Ä└Ē▓┐ų„╚╬╝▄śŗĤīOėŅŻ¼ßśī”NLPšZ┴xėŗ╦Ń╝╝ągĄ─Š▀¾wå¢Ņ}╔Ņ╚ļĘų╬÷Ż╗ūį╚╗šZčį╠Ä└Ē▓┐┘Y╔Ņčą░l╣ż│╠Ĥ║╬▓«└┌Ż¼ė├┤¾┴┐ł÷Š░įö╝ÜĮŌßī┴╦ŪķĖąĘų╬÷ŅIė“Ą─╝╝ągæ¬ė├Ż╗ūį╚╗šZčį╠Ä└Ē▓┐┘Y╔Ņčą░l╣ż│╠ĤĮ¬ĄŽŻ¼įö╝ÜĻU╩÷┴╦Ė┼┬╩łD─Żą═╝╝ąg╚ń║╬æ¬ė├Ż╗░┘Č╚AI╝╝ąg╔·æB▓┐┘Y╔Ņ«aŲĘĮø└ĒÅłŠ¦Š¦Ż¼×ķ┤¾╝ę¼Fł÷ųĖī¦░┘Č╚AIķ_Ę┼ŲĮ┼_Ą─╩╣ė├ĘĮĘ©ĪŻ
NLP╩Ū╩▓├┤Ż┐
NLP╩Ūėŗ╦ŃÖC┐ŲīWŅIė“┼c╚╦╣żųŪ─▄ŅIė“ųąĄ─ę╗éĆųžę¬ĘĮŽ“ĪŻ╦³čąŠ┐─▄īŹ¼F╚╦┼cėŗ╦ŃÖCų«ķgė├ūį╚╗šZčį▀Mąąėąą¦═©ą┼Ą─Ė„ĘN└Ēšō║═ĘĮĘ©ĪŻūį╚╗šZčį╠Ä└Ē╩Ūę╗ķT╚┌šZčįīWĪóėŗ╦ŃÖC┐ŲīWĪóöĄīWė┌ę╗¾wĄ─īW┐ŲĪŻNLPė╔ā╔éĆų„ꬥ─╝╝ągŅIė“śŗ│╔Ż║ūį╚╗šZčį└ĒĮŌ║═ūį╚╗šZčį╔·│╔ĪŻ
- ūį╚╗šZčį└ĒĮŌĘĮŽ“Ż¼ų„ę¬─┐ś╦╩ŪÄ═ų·ÖCŲ„Ė³║├└ĒĮŌ╚╦Ą─šZčįŻ¼░³└©╗∙ĄAĄ─į~Ę©ĪóŠõĘ©Ą╚šZ┴x└ĒĮŌŻ¼ęį╝░ąĶŪ¾ĪóŲ¬š┬ĪóŪķĖąīė├µĄ─Ė▀īė└ĒĮŌĪŻ
- ūį╚╗šZčį╔·│╔ĘĮŽ“Ż¼ų„ę¬─┐ś╦╩ŪÄ═ų·ÖCŲ„╔·│╔╚╦─▄ē“└ĒĮŌĄ─šZčįŻ¼▒╚╚ń╬─▒Š╔·│╔Īóūįäė╬─š¬Ą╚ĪŻ
NLP╝╝ąg╗∙ė┌┤¾öĄō■Īóų¬ūRłDūVĪóÖCŲ„īW┴ĢĪóšZčįīWĄ╚╝╝ąg║═┘Yį┤Ż¼▓ó┐╔ęįą╬│╔ÖCŲ„ĘŁūgĪó╔ŅČ╚å¢┤Īóī”įÆŽĄĮyĄ─Š▀¾wæ¬ė├ŽĄĮyŻ¼▀MČ°Ę■äšė┌Ė„ŅÉīŹļHśIäš║═«aŲĘĪŻ
╬ęéā×ķ╩▓├┤ąĶę¬NLPŻ┐
į┌č▌ųvųąŻ¼×ķ┴╦ūī┤¾╝ęėąĖ³ų▒ė^Ą─Ėą╩▄Ż¼ÅłōP╩ūŽ╚┼e┴╦éĆ╔·╗ŅųąĄ─└²ūėŻ║╚╦éāį┌ė├░┘Č╚╦č╦„ę╗éĆ╔·Ų¦ūųĢrŻ¼▓╗ų¬Ą└Ų┤궥─ŪķørŽ┬Ģ■╦č╦„Ż║“4éĆėų─Ņ╩▓├┤Ż┐”Ż¼╬ęéā░l¼FŻ¼╦č╦„ĮY╣¹ę╗Č©╩ŪĖµįV─Ń▀@éĆ“ģ¼”ūų─Ņ╩▓├┤Ż¼Č°▓╗╩Ū“4éĆėų─Ņ╩▓├┤”Ą─▀@ÄūéĆį~▒Ē├µĄ─Ųź┼õĮY╣¹Ż¼▀@ŲõųąęčĮøė├ĄĮūį╚╗šZčį└ĒĮŌĄ──▄┴”┴╦Ż¼╦³Ä═ų·╦č╦„ę²Ūµ└ĒĮŌė├æ¶ąĶę¬╦čĄ─╩Ū“ė╔4éĆėųĮM│╔Ą─ūų”Ż¼Č°▓╗╩Ū“4éĆėų╩Ū╩▓├┤”▀@ÄūéĆ╣┬┴Ń┴ŃĄ─į~ĪŻė╔┤╦┐╔ęŖŻ¼NLP╝╝ągšµš²─▄ē“ų¬Ą└─Ń╦∙šfĄ─įÆĄ─╔ŅīėšZ┴x╩Ū╩▓├┤Ż¼▀@ĒŚ╝╝ągę▓░č╚╦╣żųŪ─▄═ŲŽ“┴╦ę╗éĆą┬Ą─Ė▀Č╚ĪŻ
─Ū├┤NLPŠ┐Š╣─▄─▄ē“Ė╔╩▓├┤Ż┐╚ń║╬Ä═ų·śIäšīŹ¼FŻ¼ÅłōP└^└mĮķĮB┴╦░┘Č╚NLPķ_Ę┼Ą─ÄūĒŚĄõą═╝╝ągŻ║
ŪķĖąāAŽ“Ęų╬÷
ßśī”Ħėąų„ė^├Ķ╩÷Ą─ųą╬─╬─▒ŠŻ¼┐╔ūįäė┼ąöÓįō╬─▒ŠĄ─ŪķĖąśOąįŅÉäe▓óĮo│÷ŽÓæ¬Ą─ų├ą┼Č╚ĪŻŪķĖąśOąįĘų×ķĘeśOĪóŽ¹śOĪóųąąįĪŻŪķĖąāAŽ“Ęų╬÷─▄Ä═ų·Ų¾śI└ĒĮŌė├涎¹┘M┴ĢæTĪóĘų╬÷¤ß³cįÆŅ}║═╬ŻÖC▌øŪķ▒O┐žŻ¼×ķŲ¾śI╠ß╣®ėą┴”Ą─øQ▓▀ų¦│ųĪŻ

įušōė^³c│ķ╚Ī
ūįäėĘų╬÷įušōĻPūó³c║═įušōė^³cŻ¼▓ó▌ö│÷įušōė^³cś╦║×╝░įušōė^³cśOąįĪŻ─┐Ū░ų¦│ų13ŅÉ«aŲĘė├æ¶įušōĄ─ė^³c│ķ╚ĪŻ¼░³└©├└╩│ĪóŠŲĄĻĪóŲ¹▄ćĪóŠ░³cĄ╚Ż¼┐╔Ä═ų·╔╠╝ę▀Mąą«aŲĘĘų╬÷Ż¼▌oų·ė├æ¶▀MąąŽ¹┘MøQ▓▀ĪŻ

į~┴xŽÓ╦ŲČ╚ėŗ╦Ń
ė├ė┌ėŗ╦Ńā╔éĆĮoČ©į~šZĄ─šZ┴xŽÓ╦ŲČ╚Ż¼╗∙ė┌ūį╚╗šZčįųąĄ─Ęų▓╝╝┘įOŻ¼╝┤įĮ╩ŪĮø│Ż╣▓═¼│÷¼FĄ─į~ų«ķgĄ─ŽÓ╦ŲČ╚įĮĖ▀ĪŻį~┴xŽÓ╦ŲČ╚╩Ūūį╚╗šZčį╠Ä└ĒųąĄ─ųžę¬╗∙ĄA╝╝ągŻ¼╩ŪīŻ├¹═┌Š“ĪóqueryĖ─īæĪóį~ąįś╦ūóĄ╚│Żė├╝╝ągĄ─╗∙ĄAų«ę╗ĪŻ
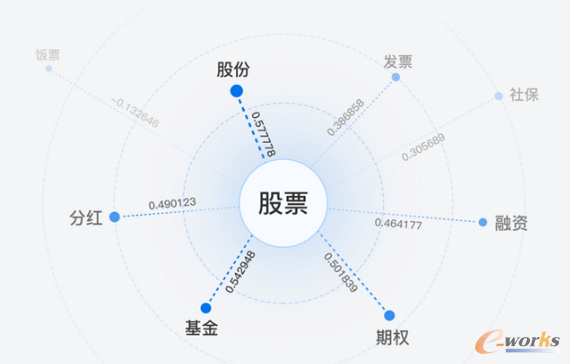
į~Ę©Ęų╬÷
░┘Č╚į~Ę©Ęų╬÷Ž“ė├æ¶╠ß╣®Ęųį~Īóį~ąįś╦ūóĪó├³├¹īŹ¾wūRäe╚²┤¾╣”─▄ĪŻįōĘ■äš─▄ē“ūRäe│÷╬─▒Š┤«ųąĄ─╗∙▒Šį~ģRś╦ūó║═į~ģRĄ─į~ąįŻ¼▓ó▀Mę╗▓ĮūRäe│÷├³├¹īŹ¾wŻ¼░┘Č╚į~Ę©Ęų╬÷Ą─╦ŃĘ©ą¦╣¹┤¾Ę∙ŅIŽ╚ęč╣½ķ_Ą─ų„┴„ųą╬─į~Ę©Ęų╬÷─Żą═ĪŻ

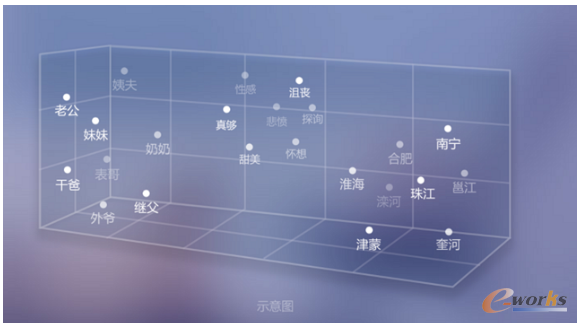
Č╠╬─▒ŠŽÓ╦ŲČ╚
─▄ē“╠ß╣®▓╗═¼Č╠╬─▒Šų«ķgŽÓ╦ŲČ╚Ą─ėŗ╦ŃŻ¼▌ö│÷Ą─ŽÓ╦ŲČ╚╩Ūę╗éĆĮķė┌-1ĄĮ1ų«ķgĄ─īŹöĄųĄŻ¼įĮĮėĮ³1ätŽÓ╦ŲČ╚įĮĖ▀ĪŻ▀@éĆŽÓ╦ŲČ╚ųĄ┐╔ęįų▒Įėė├ė┌ĮY╣¹┼┼ą“Ż¼ę▓┐╔ęįū„×ķę╗ŠS╗∙ĄA╠žš„ū„ė├ė┌Ė³Å═ļsĄ─ŽĄĮyĪŻ
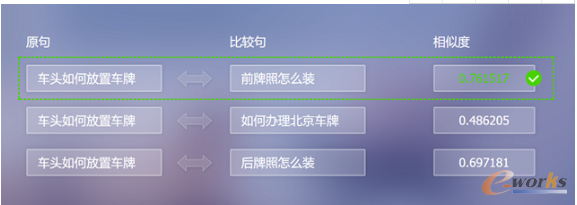
DNNšZčį─Żą═
šZčį─Żą═╩Ū═©▀^ėŗ╦ŃĮoČ©į~ĮM│╔Ą─ŠõūėĄ─Ė┼┬╩Ż¼Å─Č°┼ąöÓ╦∙ĮM│╔Ą─Šõūė╩ŪĘ±Ę¹║Ž┐═ė^šZčį▒Ē▀_┴ĢæTĪŻį┌ÖCŲ„ĘŁūgĪóŲ┤īæ╝mÕeĪóšZę¶ūRäeĪóå¢┤ŽĄĮyĪóį~ąįś╦ūóĪóŠõĘ©Ęų╬÷║═ą┼ŽóÖz╦„Ą╚ŽĄĮyųąČ╝ėąÅVĘ║æ¬ė├ĪŻ

į~Ž“┴┐▒Ē╩Š
į~Ž“┴┐▒Ē╩Š▒Ē╩Š╩Ū═©▀^ė¢ŠÜĄ─ĘĮĘ©Ż¼īóšZčįį~▒ĒųąĄ─į~ė│╔õ│╔ę╗éĆķLČ╚╣╠Č©Ą─Ž“┴┐ĪŻį~▒Ēųą╦∙ėąĄ─į~Ž“┴┐śŗ│╔ę╗éĆŽ“┴┐┐šķgŻ¼├┐ę╗éĆį~Č╝╩Ū▀@éĆį~Ž“┴┐┐šķgųąĄ─ę╗éĆ³cŻ¼└¹ė├▀@ĘNĘĮĘ©Ż¼īŹ¼F╬─▒ŠĄ─┐╔ėŗ╦ŃĪŻ
ę└┤µŠõĘ©Ęų╬÷
└¹ė├Šõūėųąį~┼cį~ų«ķgĄ─ę└┤µĻPŽĄüĒ▒Ē╩Šį~šZĄ─ŠõĘ©ĮYśŗą┼Žó(╚ńų„ų^Īóäė┘eĪóČ©ųąĄ╚ĮYśŗĻPŽĄ)
▓óė├śõĀŅĮYśŗüĒ▒Ē╩Šš¹ŠõĄ─Ą─ĮYśŗ(╚ńų„ų^┘eĪóČ©ĀŅčaĄ╚)ĪŻ
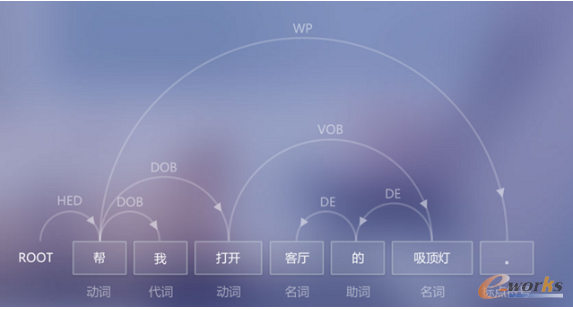
░┘Č╚šZ┴xėŗ╦Ń╝╝ąg╩Ū╚ń║╬īŹ¼FĄ─Ż┐
į┌Ė„éĆNLPķ_Ę┼Įė┐┌ų«ųąŻ¼šZ┴xėŗ╦Ń╩Ūę╗éĆĘŪ│Ż╗∙ĄAĄ─╝╝ągĪŻ░┘Č╚NLP▓┐ķTĄ─ų„╚╬╝▄śŗĤīOėŅų„ę¬ć·└@NLPšZ┴xėŗ╦Ńš¹¾w╝╝ąg┐“╝▄š╣ķ_Ęų╬÷Ż¼║╦ą─ĮķĮB┴╦šZ┴x▒Ē╩Š╝╝ąg║═šZ┴xŲź┼õ╝╝ągĪŻ░┘Č╚NLPšZ┴xėŗ╦Ńš¹¾w┐“╝▄ų„ę¬Ęų╚²┤¾▓┐ĘųŻ©╚ńŽ┬łDŻ®Ż¼ūŅĄūīėę└═ąė┌┤¾öĄō■ĪóŠWĒōöĄō■║═ė├æ¶ąą×ķöĄō■Ż¼ęį╝░Ė▀ąį─▄╝»╚║Ż©GPUĪóCPU║═FPGAŻ®Ż¼┤“įņ┴╦╗∙ė┌DNN║═Ė┼┬╩łD─Żą═Ą─šZ┴xėŗ╦Ńę²ŪµŻ¼═©▀^╬─▒Š▌ö╚ļĄĮšZ┴xėŗ╦Ńę²Ūµ«öųąŻ¼┐╔ęįĄ├ĄĮ╬─▒ŠĄ─šZ┴x▒Ē╩ŠŻ¼▀MČ°╗∙ė┌▀@éĆšZ┴x▒Ē╩ŠŻ¼▀MąąšZ┴xīė├µĄ─ėŗ╦ŃŻ¼░³└©šZ┴xŲź┼õĪóšZ┴xÖz╦„Īó╬─▒ŠĘųŅÉĪóą“┴ą╔·│╔ęį╝░ą“┴ąś╦ūóĪŻ
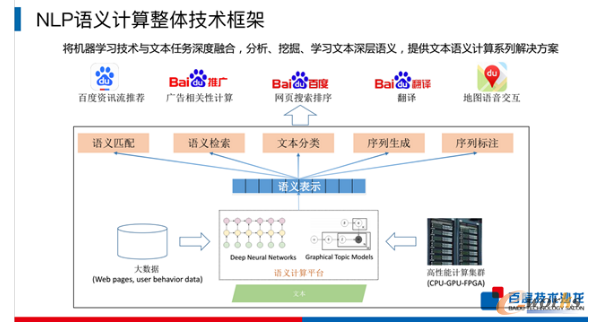
─┐Ū░Ż¼░┘Č╚į┌šZ┴xĘĮ├µķ_Ę┼┴╦╦─éĆ╝╝ągŻ¼─ę└©┴╦į~ģR║═Šõūėā╔éĆīė├µĄ─šZ┴x╝╝ągĪŻį~ģRīė├µ░³└©┴╦į~šZ┴xŽ“┴┐▒Ē╩ŠŻ¼į~┴xŽÓ╦ŲČ╚ėŗ╦ŃŻ╗Šõūėīė├µĄ─░³└©Č╠╬─▒ŠšZ┴xŽÓ╦ŲČ╚ėŗ╦Ń║═DNNšZčį─Żą═ĪŻīOėŅī”▀@ą®╝╝ąg▒│║¾Ą─įŁ└Ē▀Mąą┴╦įö╝ÜĄ─ĮķĮBĪŻ
šZ┴x▒Ē╩Š╝╝ągśIĮń║▄įńŠ═ķ_╩╝蹊┐Ż¼ų„ę¬ėąā╔ĘN┴„┼╔Ż¼ę╗éĆ╩Ūą╬╩Į╗»Ą─ĘĮĘ©Ż¼ę╗éĆ╩Ū╗∙ė┌ĮyėŗĄ─ĘĮĘ©ĪŻĻPė┌╗∙ė┌ą╬╩Į╗»Ą─ĘĮĘ©Ż¼į┌╔Ž╩└╝o░╦╩«─Ļ┤·Ųš┴ų╦╣ŅDėą┐ŲīW╝ę╠ß│÷Ż║╗∙ė┌šZčįīWų¬ūRśŗĮ©ę╗éĆį~łDŻ¼░čų¬ūR═©▀^į~┼cį~ų«ķgĄ─ĻPŽĄśŗĮ©ĄĮ▀@éĆłD└’ĪŻŠ┼╩«─Ļ┤·ėųėą╚╦╠ß│÷Ż¼īóūį╚╗šZčį▒Ē╩Š│╔ę╗ĘN▀ē▌ŗĄ─▒Ē▀_╩ĮŻ¼┐╔ęįų▒Įėė├ė┌ėŗ╦ŃÖCėŗ╦Ń║═ł╠ąąĪŻĄ½▀@ā╔éĆ╝╝ągČ╝┤µį┌ę╗éĆå¢Ņ}Ż║ūįäė╗»│╠Č╚▓╗Ė▀Ż¼▀mė├ąį▌^▓ŅŻ¼ę“┤╦Ż¼░┘Č╚NLPų„ę¬▓╔ė├╗∙ė┌ĮyėŗĄ─ĘĮĘ©ĪŻ
Č╠╬─▒ŠšZ┴xŽÓ╦ŲČ╚ėŗ╦Ń╩Ū╦¹éāųž³c┤“įņĪóæ¬ė├ÅVĘ║Ą─╝╝ągĪŻŲõųąĄ─║╦ą──Żą═╩Ū└¹ė├╦¹éā2013─Ļķ_╩╝čą░lĄ─SimNetšZ┴xŲź┼õ┐“╝▄Ż¼į┌Ū¦ā|╝ēäešµīŹ³cō¶öĄō■ė¢ŠÜĄ├ĄĮĪŻįō┐“╝▄Ą─╗∙ĄAŲź┼õ╦ŃĘ©╔Ž░³║¼ā╔ĘNŲź┼õĘČ╩ĮŻ¼ę╗ĘNé╚ųžė┌▒Ē╩ŠīėĮ©─ŻŻ¼┴Ē═Ōę╗ĘNätĖ³é╚ųžė┌Ųź┼õīėĮ©─ŻĪŻ▀@ā╔ĘN─Żą═Ė„ėąā×ä▌Ż¼┐╔ĮŌøQ▓╗═¼å¢Ņ}ĪŻ┴Ē═ŌŻ¼ßśī”▓╗═¼æ¬ė├ł÷Š░╦¹éā▀ĆöUš╣čą░l┴╦╗∙ė┌ūųĘ¹╝ēäeŲź┼õ║═ČÓęĢĮŪŲź┼õ╝╝ągŻ¼▀@ą®╝╝ągČ╝ÅVĘ║æ¬ė├ė┌░┘Č╚ā╚▓┐Ė„«aŲĘųąĪŻ
░┘Č╚ūį╚╗šZčį╠Ä└Ēį┌ŪķĖąĘų╬÷ŅIė“ėą──ą®╝╝ąg║═æ¬ė├Ż┐
į┌č▌ųvųąŻ¼║╬▓«└┌ų„ę¬ßśī”ė├æ¶╚š│ŻĄ─╩╣ė├ł÷Š░Ż¼Ęų╬÷┴╦ŪķĖąĘų╬÷╝╝ągĄ─įŁ└Ē║═īŹļHæ¬ė├ĪŻ░┘Č╚ŪķĖąĘų╬÷╝╝ągę└═ąė┌įušō┤¾öĄō■Īó╔ŅČ╚īW┴ĢĪóšZ┴x└ĒĮŌĄ╚╗∙ĄA╝╝ągŻ¼Į©┴ó┴╦ę╗╠ū═Ļš¹ŪķĖąĘųŅÉ┼cė^³c═┌Š“Ą─║╦ą─╝╝ągĪŻį┌ŪķĖąĘųŅÉĘĮ├µŻ¼╬ęéāčą░l┴╦ŪķĖąāAŽ“ąįĘų╬÷ĪóŪķĖąĄ─ŪķŠwĘų╬÷Ż¼ŪķĖąī”Ž¾ūRäeęį╝░ŠõūėĄ─ų„┐═ė^Ą─Ęų╬÷ĪŻį┌ė^³c═┌Š“ĘĮ├µŻ¼╬ęéā═©▀^ŪķĖą┤Ņ┼õų¬ūRūįäėśŗĮ©║═ė^³cėŗ╦Ń╝╝ągŻ¼╬ęéā─▄ėąą¦Ą─▀Mąą╬─▒ŠöĄō■Ą─ė^³c│ķ╚ĪĪŻ░┘Č╚ę└═ą▀@ą®║╦ą─Ą─╝╝ągŻ¼▀Mąąė├涫aŲĘķ_░lĪŻ
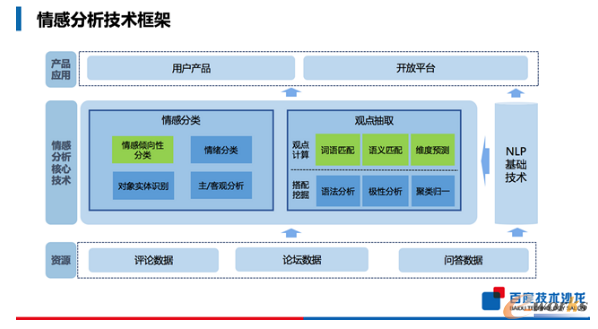
▀@└’ųž³cĮķĮBā╔ŅÉ║╦ą─╝╝ągŻ║
ŪķĖąāAŽ“ąįĘų╬÷
ŪķĖąāAŽ“Ęų╬÷╚╬äš─┐ś╦╩Ū─▄ē“┼ąöÓė├æ¶╬─▒Š╩ŪĘeśOĪóŽ¹śO╗“╩ŪųąąįĄ─ŪķĖąĪŻé„ĮyĘĮĘ©ėąā╔ŅÉŻ║ę╗ŅÉ└¹ė├ŪķĖąį~Ąõ▀MąąęÄätŲź┼õĄ─ĘĮĘ©▀Mąą┼ąöÓŻ¼┴Ē═Ōę╗ŅÉ╗∙ė┌ŪķĖąį~Ąõ║═╬─▒Š╠žš„Į©┴óę╗éĆ2ĘųŅÉ╚╬䚥─ĘĮĘ© ĪŻ░┘Č╚ŪķĖąāAŽ“ąįĘų╬÷╗∙ė┌╔ŅČ╚īW┴ĢĄ─ĘĮĘ©Ż¼ĘųäeĮ©┴ó┴╦Šõūė╝ēĪóīŹ¾w╝ēĪóŲ¬š┬╝ēČÓ┴ŻČ╚═Ļš¹Ą─Ęų╬÷╚╬äšĪŻŠõūė╝ē┴ŻČ╚╔ŽŻ¼═©▀^╗∙ė┌Bi-LSTMĘųŅÉĘĮĘ©Ż¼ŽĄĮyĖ³║├Ą─▓ČūĮ┴╦ŪķĖąśOąįį┌Ū░║¾╬─▒Ē▀_Ą─ą┼ŽóŻ¼ą¦╣¹╔ŽŽÓī”ė┌é„ĮyĄ─ĘĮĘ©ėą┴╦║▄┤¾Ą─╠ß╔²ĪŻīŹ¾w╝ē┴ŻČ╚Ą─╚╬äšĖ┼─Ņ╔įėą╗▐ØŁŻ¼┼eéĆ└²ūėŻ║ĪČ│╔²łī”æ└Ū2Ą─┐┤Ę©ĪĘę╗Ų¬╬─š┬┐╔─▄ėąČÓéĆų„Ņ}Ż¼▀@éĆ╚╬䚊═╩ŪŽŻ═¹─▄ē“░č▀@Ų¬╬─š┬ī”ė┌“ģŪŠ®”Ą─æBČ╚Ęų╬÷│÷üĒĪŻį┌▀@éĆ╚╬äšųąŻ¼╬ęéā═©▀^Į©┴óīė┤╬╗»Ą─šZ┴x▒Ē▀_ĘĮĘ©Ż¼ūīš¹éĆŽĄĮyĖ³╝ėŠ½£╩Ą─▀MąąĘų╬÷║═┼ąöÓĪŻ
įušōė^³c│ķ╚ĪĄ─╝╝ąg
įušōė^³c│ķ╚Ī─┐ś╦Ż║ĮoČ©ę╗éĆ╬─▒ŠŻ¼░čŲõųą▒Ē▀_ė^³cĄ─ą┼Žó│ķ╚Ī│÷üĒĪŻ┼eéĆ└²ūėŻ¼ė├æ¶Ą─įušōŻ║“▀@╝ę┬├ĄĻĄ─Ę■äš▀Ć▓╗ÕeŻ¼Ą½╩ŪĘ┐ķg▒╚▌^║å┬¬”Ż¼╬ęéā─┐ś╦░č“Ę■äš▓╗ÕeĪóĘ┐ķg║å┬¬”▀@śėĄ─ĻPµIė^³cą┼Žó│ķ╚Ī│÷üĒĪŻįušōė^³c│ķ╚Ī╝╝ągį┌«öŪ░╗ź┬ōŠW«aŲĘųąæ¬ė├╩«ĘųÅVĘ║Ż¼Ą½╩Ūš┘╗ž┬╩ę╗ų▒▓╗Ė▀Ż¼░┘Č╚Ą─įušōė^³c│ķ╚Ī╝╝ągīó╚╬äšÅ─æ¬ė├ąĶŪ¾▀Mąą╝Üų┬Ęų╬÷▓ĮŌŻ¼═©▀^╗∙ė┌ŪķĖą┤Ņ┼õĄ─ĘĮĘ©Ż¼╗∙ė┌šZ┴xėŗ╦ŃĄ─ĘĮĘ©Ż¼╗∙ė┌ŠSČ╚ŅA£yĄ─ĘĮĘ©Ż¼ęį╝░╗∙ė┌ŠSČ╚ŅA£y╝ėŪķĖąśOąįĘųŅÉĄ─ĘĮĘ©═Ļ├└Ą─ĮŌøQ┴╦æ¬ė├ųąĖ„ĘNĄ─å¢Ņ}Ż¼▀@ę▓╩Ūę╗éĆ╝╝ąg║═æ¬ė├═ĻĮY║ŽĮøĄõ░Ė└²ĪŻ
Ė┼┬╩łD─Żą═╝╝ąg╚ń║╬æ¬ė├Ż┐
Į¬ĄŽĘųŽĒĄ─ų„Ņ}╩ŪĪČFamilia┐╔┼õų├Ą─ų„Ņ}─Żą═┐“╝▄ĪĘŻ¼Familia╩Ū╝ęūÕĪó╝ę═źĄ─ęŌ╦╝ĪŻŅÖ├¹╦╝┴xŻ¼▀@éĆ┐“╝▄Ą─╠ž³cŠ═╩Ū║Ł╔w┴╦ę╗ūÕŠ▀ėą▌^┤¾Ą─╣żśIārųĄĄ─ų„Ņ}─Żą═Ż¼▀@śėę╗üĒŻ¼ę╗ŠĆĄ─╣ż│╠ĤŠ═ėą║▄ČÓņ`╗ŅąįŻ¼┐╔ęįĖ∙ō■Š▀¾w╚╬䚯¼üĒ▀xō±▀mė├Ą──Żą═ĪŻ
░┘Č╚ėąę╗éĆžÉ╚~╦╣╝╝ąg¾wŽĄĄ─┐“╝▄Ż¼ų„ę¬Ęų╚²┤¾ŅÉŻ║Ą┌ę╗ŅÉ╩Ūų„Ņ}─Żą═Ż¼▀@éĆ┐“╝▄Ą─╠ž³cŠ═╩Ū╦³ėąę╗éĆūį┼õų├Ą─╣”─▄Ż╗Ą┌Č■ŅÉ╩Ū³cō¶─Żą═Ż¼ų„ę¬╩Ūæ¬ė├į┌╦č╦„ę²ŪµĄ─ŅIė“Ż¼üĒ┴┐╗»Ęų╬÷ė├æ¶Ą─╦č╦„ąą×ķęį╝░╦č╦„▓ķįā║═ŠWĒōĄ─ŽÓĻPąįŻ╗Ą┌╚²ŅÉ╩ŪĘųŅÉ─Żą═Ż¼░³║¼ūŅ│ŻęŖĄ─╗∙ė┌žÉ╚~╦╣ŠWĄ─ĘųŅÉŲ„ĪŻ
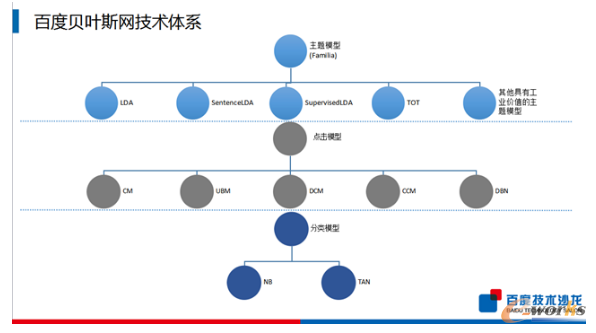
ų„Ņ}─Żą═┐“╝▄ųąėą╩«ÄūéĆų„┴„Ą─ų„Ņ}─Żą═Ż¼Ųõųą░³║¼LDA─Żą═Īóę²╚ļ┴╦ŠõūėĮYśŗĄ─SentenceLDA─Żą═Īóę²╚ļ┴╦▒OČĮą┼╠¢Ą─SupervisedLDAŻ¼ęį╝░Ųõ╦¹Š▀ėą╣żśIārųĄĄ─ų„Ņ}─Żą═Ż¼▓óŪęų¦│ųė├æ¶Ė∙ō■Š▀¾w╚╬äšįOėŗī”æ¬Ą──Żą═ĪŻ
─Ū├┤Ż¼×ķ╩▓├┤ę¬įOėŗFamilia▀@éĆų„Ņ}┐“╝▄Ż┐śIĮń┤¾▓┐Ęųų„Ņ}─Żą═╣żŠ▀ų╗ų¦│ųPLSA║═LDAā╔ĘN─Żą═Ż¼▀@ā╔ĘN─Żą═ĘŪ│ŻŅÉ╦ŲŻ¼╦³éāų╗ų¦│ųę╗ĘNöĄō■╝┘įOŻ¼ę▓Š═╩ŪšfŻ¼╬ęéāų╗─▄ė├ę╗ĘN─Żą═üĒ▀mė├▓╗═¼Ą─ł÷Š░Ż¼▓╗─▄ų¦│ųė├æ¶Ą─Ė∙ō■Š▀¾w╚╬äšūįČ©┴xöUš╣ĪŻ«öė├æ¶Ą─öĄō■▒Š╔Ē║═▀@ā╔éĆ─Żą═Ą─╝┘įOėą▌^┤¾▓Ņ«ÉĢrŻ¼ą¦╣¹┐╔ŽļČ°ų¬ĪŻ┴Ēę╗ĘĮ├µŻ¼«öŪ░Ą─ų„Ņ}─Żą═╣żŠ▀ī”Ž┬ė╬Ą─æ¬ė├▓ó▓╗╠½ėč║├Ż¼▀@ą®╣żū„═∙═∙ų╗ūóųž─Żą═Ą─ė¢ŠÜŻ¼║÷┬į┴╦─Żą═╚ń║╬į┌Š▀¾w╚╬äšųąæ¬ė├ĪŻÅ──Żą═Ą─ė¢ŠÜĄĮæ¬ė├ų«ķgėą║▄ķLĄ─ŠÓļxŻ¼╚ń║╬Ž¹│²▀@éĆŠÓļx╩Ū╬ęéā▀@éĆ╣żū„Ą─ųž³cĪŻFamiliaį┌░┘Č╚Ą─æ¬ė├ł÷Š░ŲõīŹĘŪ│ŻČÓŻ¼░³║¼┴╦┤¾╝ęČ·╩ņ─▄įöĄ─░┘Č╚╦č╦„Īó░┘Č╚ą┬┬äĪó┼┤├ūĪó┘N░╔▀@ą®ŲĮ┼_Ż¼ę▓▓┐╩ĄĮ┴╦░┘Č╚ūį╚╗šZčįĄ─įŲ╠Ä└ĒŲĮ┼_╔ŽŻ¼▀@éĆ╣żŠ▀─┐Ū░├┐╠ņėą3000╚f┤╬Ą─Ēææ¬ąĶŪ¾ĪŻ
Familia┐“╝▄╩Ūį§├┤į┌╣żśIĮńł÷Š░▀Mąąæ¬ė├Ą─Ż┐Ą┌ę╗▓ĮŻ¼öĄō■ŅA╠Ä└ĒŻ¼▀@└’┐╔ęįų¦│ųČÓĘNŅÉą═Ą─öĄō■Ż¼░³└©│ŻęŖĄ─ŠWĒōöĄō■Īóą┬┬äöĄō■║═┼┤├ūöĄō■Ż¼į┌ā╚▓┐īóöĄō■ŅA╠Ä└Ē▓Į¾E║═░┘Č╚Ą─Ęųį~▀Mąą┴╦ę╗éĆ╔ŅČ╚Ą─╚┌║ŽĪŻį┌Ęųį~Ą─Ū░║═║¾╬ęéā▀ĆėąČÓĘNČÓśėĄ─▀^×VŲ„Ż¼ė├æ¶┐╔ęįĖ∙ō■ūį╝║Ą─ąĶŪ¾Ż¼üĒ▀xō±╩▓├┤ą┼Žóę¬▀^×VĄ¶Ż¼╩▓├┤ą┼Žó┐╔ęį▒Ż┴¶ĪŻĄ┌Č■▓ĮŻ¼Ė┼┬╩łD─Żą═┼õų├Ż¼Familiaų¦│ųČÓĘNų„┴„Ą─ęčėąĄ─ų„Ņ}─Żą═Ż¼═¼Ģrė├æ¶ę▓┐╔ęįūįČ©┴xūį╝║Ą─ų„Ņ}─Żą═ĪŻ▀@éĆ▀^│╠╩Ū═©▀^ę╗ĘNöĄō■ĮM┐Ś│ķŽ¾┤µā”ČÓĘNłD─Żą═Ą─ą┼ŽóüĒīŹ¼FĄ─ĪŻĄ┌╚²▓ĮŻ¼▓╔śė╣½╩Įūįäė═Ųī¦Ż¼FamiliaųąĄ─ģóöĄ═Ųī¦ę²Ūµ┐╔ęįūįäė═Ųī¦│÷▓╔śė╣½╩ĮŻ¼ĮĄĄ═┴╦ų„Ņ}─Żą═æ¬ė├Ą─öĄīWķTÖæĪŻĄ┌╦─▓ĮŻ¼─Żą═Ą─║¾Ų┌╠Ä└ĒŻ¼Familia▀Mę╗▓Įī”ė¢ŠÜ║├Ą─ų„Ņ}─Żą═▀Mąąā×╗»║═ē║┐s▓┘ū„ĪŻĄ┌╬Õ▓ĮŻ¼Familia│ķŽ¾┴╦šZ┴x▒Ē╩Š║═šZ┴xŲź┼õā╔éĆæ¬ė├ĘČ╩ĮŻ¼ė├æ¶┐╔ęįĖ∙ō■Š▀¾w╚╬äšüĒ╩╣ė├ī”æ¬Ą─ĘČ╩ĮĪŻ
─┐Ū░FamiliaęčĮøį┌github╔Ž═Ļ│╔ķ_į┤Ż©httpsŻ║//github.com/baidu/familiaŻ®Ż¼Ą┌ę╗Ų┌╠ß╣®ŠWĒōĪóą┬┬äĪóąĪšfĄ╚ČÓéĆ┤╣ŅÉšZ┴Žė¢ŠÜĄ─╣żśI╝ēų„Ņ}─Żą═Ż¼▓ó╠ß╣®šZ┴x▒Ē╩ŠĪóšZ┴xŲź┼õā╔ŅÉæ¬ė├ĘČ╩ĮĄ─┤¾┴┐æ¬ė├ł÷Š░ųĖī¦ĪŻ
ī”ķ_░lš▀Č°čįŻ¼╚ń║╬Ė³║├Ą─╩╣ė├░┘Č╚AIķ_Ę┼ŲĮ┼_Ż┐
ÅłŠ¦Š¦ų„ꬊ═ūį╚╗šZčį╩╣ė├Ą─ŽÓĻPå¢Ņ}╝░š¹éĆ░┘Č╚AIķ_Ę┼ŲĮ┼_Ą─╩╣ė├ĘĮĘ©▀Mąą┴╦ĮķĮBĪŻ─┐Ū░░┘Č╚ūį╚╗šZčį╠Ä└Ē╝╝ągķ_Ę┼8ĒŚšZčį╠Ä└ĒĄ─╗∙ĄA╝╝ągŻ¼╗∙ė┌▀@ą®╗∙ĄAĄ──▄┴”Ż¼░┘Č╚ī”═Ōķ_Ę┼┴╦║▄ČÓĖąų¬īė║═šJų¬īėĄ─╝╝ągŻ¼į┌╔Ž├µ┤ŅĮ©┴╦╬ęéāę╗éĆķ_Ę┼ŲĮ┼_Ż¼į┌▀@éĆŲĮ┼_╔Ž░┘Č╚░č╬ęéā╦∙ėą│╔╩ņĄ─AI╝╝ągČ╝į┌▀@└’Įyę╗ī”═Ōķ_Ę┼Ż¼╩╣┤¾╝ę─▄ē“═©▀^Įė┐┌Ą─ĘĮ╩ĮŻ¼ų▒Įėš{ė├Īóų▒Įė╩╣ė├Ż¼▒╚╚ńšZę¶ūRäeĪóšZę¶║Ž│╔Īó╬─ūųūRäeĄ─Ė„ĘN─Ż░ÕĪóČ╦┐┌Ż¼╚╦─śūRäeĄ╚ĪŻ┴Ē═ŌŻ¼░┘Č╚ę▓īóķ_Ę┼éĆąį╗»║═Č©ųŲĘ■䚯¼ų„ę¬╩Ūėąį~Ę©Ęų╬÷Īóįušōė^³c│ķ╚Ī║═ŪķĖąāAŽ“Ęų╬÷ĪŻį~Ę©Ęų╬÷Ą─Č©ųŲŻ¼┐╔ęįÄ═ų·╬ęéāĄ─ąąśI┐═æ¶īŹ¼FéĆąį╗»ąĶŪ¾Ż¼╚¶ėąūRäe▓╗┴╦Ą─į~ģRŻ¼┐╔ęį═©▀^╔Žé„į~▒ĒĄ─ĘĮ╩ĮŻ¼üĒ░č─Żą═ė¢ŠÜĄ─Ė³▀m║Žūį╝║ĪŻ

░┘Č╚AIŲĮ┼_×ķķ_░l▀^│╠╠ß╣®┴╦╚²ĘĮ├µĄ─ų¦│ųŻ¼╩ūŽ╚╩Ūķ_░lĮMĮ©Ż¼Ųõ┤╬╩Ū╣▄└Ē╣”─▄║═┼õ╠ū┘Yį┤ĪŻķ_░lĮMĮ©ĘĮ├µŻ¼├┐éĆ╝╝ągŅIė“└’Č╝ęįś╦£╩Ą─ĘĮ╩Į╠ß╣®┴╦API║═SDKŻ¼ėąą®ĘĮŽ“╔Ž▀Ć╠ß╣®┴╦ģó┐╝┤·┤aĪŻėąę╗ą®ąĶꬬÜ┴ó╚ź┼õų├Ą──ŻēKå╬¬Üū÷┴╦┼õų├ŽĄĮyŻ¼ūīķ_░lš▀┐╔ęįŽ╚į┌ŲĮ┼_╔Žū÷║├┼õų├ų«║¾Š═┐╔ęįų▒Įėš{ė├ĪŻį┌║¾┼_╣▄└Ē╔ŽŻ¼ėą╗∙ĄAĄ─æ¬ė├╣▄└ĒŻ¼ę▓ų¦│ų║▄ČÓĖ·Ų¾śIśI䚎ÓĻPĄ─éĆąį╗»Ą─┼õų├Ż¼ļSĢr▓ķ┐┤š{ė├Ą─Įyėŗą┼ŽóĪŻķ_░lš▀▀Ć┐╔ęįį┌«aŲĘ╔Ž╩╣ė├░┘Č╚LOGOŻ¼ś╦ūR│÷░┘Č╚AI╝╝ągĪŻķ_░lš▀╚ń╣¹æ¬ė├░┘Č╚Ą─AI╝╝ągĮŌøQ┴╦ąąśIųąĄ─Ąõą═å¢Ņ}Ż¼░┘Č╚ę▓Ģ■ō·╚╬▓«śĘĄ─ĮŪ╔½Ż¼īóŲõ░Ė└²▀Mąąą¹é„═ŲÅVĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.hanmeixuan.com/
▒Š╬─ś╦Ņ}Ż║ūŅ╚½├µĄ─░┘Č╚NLPūį╚╗šZčį╠Ä└Ē╝╝ągĮŌ╬÷
▒Š╬─ŠWųĘŻ║http://m.hanmeixuan.com/html/support/11121521444.html