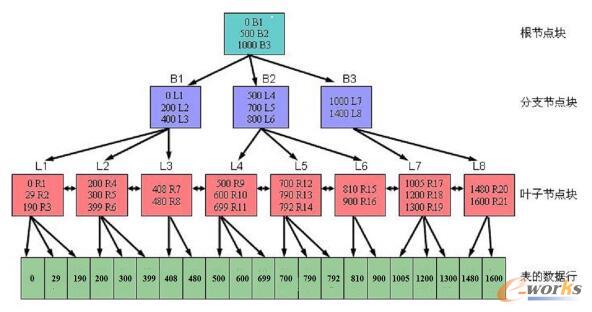
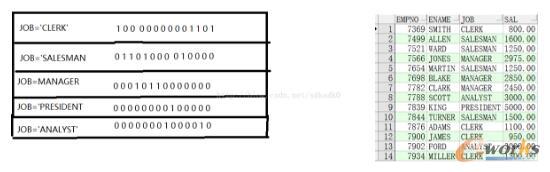
SQLā×(y©Łu)╗»╩ŪöĄ(sh©┤)ō■(j©┤)ā×(y©Łu)╗»Ą─ųžę¬ĘĮ├µŻ¼▒Š╬─īóĘų╬÷Oracleūį╔ĒĄ─CBOā×(y©Łu)╗»Ż¼╝┤╗∙ė┌│╔▒ŠĄ─ā×(y©Łu)╗»ĘĮĘ©ĪŻOracle×ķ┴╦ūįäė(d©░ng)Ą─ā×(y©Łu)╗»sqlšZ(y©│)ŠõąĶę¬Ė„ĘNĮy(t©»ng)ėŗ(j©¼)öĄ(sh©┤)ō■(j©┤)ū„×ķā×(y©Łu)╗»╗∙ĄA(ch©│)ĪŻ═Ō├µĢ■(hu©¼)═©▀^(gu©░)sqlĄ─ūĘ█ÖüĒ(l©ói)Ęų╬÷sqlĄ─ł╠(zh©¬)ąą▀^(gu©░)│╠Ż¼Ž¹║─Ą─┘Yį┤ą┼ŽóĪŻī”(du©¼)ė┌öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─ąį─▄å¢(w©©n)Ņ}═∙═∙╩Ūį┌ŽĄĮy(t©»ng)▓┐╩ę╗Č╬Ģr(sh©¬)ķgų«║¾│÷¼F(xi©żn)Ą─Ż¼╝┤┤¾┴┐ė├æ¶(h©┤)ķ_(k©Īi)╩╝╩╣ė├įōŽĄĮy(t©»ng)Ż¼ŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)╠Ä└Ē┴┐║═Ė„ĘNėŗ(j©¼)╦ŃÅ═(f©┤)ļsąįį÷╝ėĄ─Ģr(sh©¬)║“Ż¼▀@éĆ(g©©)Ģr(sh©¬)║“═∙═∙Ģ■(hu©¼)ūĘ╦▌ĄĮŽĄĮy(t©»ng)Ą─│§╩╝įO(sh©©)ėŗ(j©¼)ļAČ╬Ż¼╦∙ęį╬ęéā▀Ć╩Ūę¬į┌ŠÄ┤aļAČ╬Š═ŠÄīæ(xi©¦)Ė▀ą¦Ą─sqlšZ(y©│)ŠõĪŻ╬ęį┌ŠW(w©Żng)╔Ž┐┤ĄĮ┴╦║▄ČÓĻP(gu©Īn)ė┌sqlā×(y©Łu)╗»Ą─╬─š┬Ż¼Ą½╩Ū▓╗▒M╚╦ęŌŻ¼ėąĄ─║▄╗\Įy(t©»ng)Ą─├Ķ╩÷ėąĄ─Ė∙▒Š▀Ć╩ŪÕe(cu©░)š`Ą─ĘĮĘ©Ż¼╦∙ęį╬ęųžą┬īó╬ęĄ─īW(xu©”)┴Ģ(x©¬)▀^(gu©░)│╠ĘųŽĒ│÷üĒ(l©ói)ĪŻ
ę╗ĪóSQL▓ķįā(x©▓n)╠Ä└Ē▀^(gu©░)│╠įöĮŌ
▓ķįā(x©▓n)╠Ä└Ē┼c▓ķįā(x©▓n)ā×(y©Łu)╗»╩Ūā╔éĆ(g©©)ŽÓĻP(gu©Īn)┬ō(li©ón)Ą─Ė┼─ŅŻ¼▓ķįā(x©▓n)╠Ä└ĒĢr(sh©¬)ł╠(zh©¬)ąąSQLšZ(y©│)Šõ½@╚ĪöĄ(sh©┤)ō■(j©┤)Ą─▀^(gu©░)│╠Ż¼Č°▓ķįā(x©▓n)ā×(y©Łu)╗»╩Ū═©▀^(gu©░)Ęų╬÷SQLšZ(y©│)Šõęį╝░Ųõ╦¹┘Yį┤½@Ą├ūŅ╝čł╠(zh©¬)ąąėŗ(j©¼)äØĄ─▀^(gu©░)│╠ĪŻį┌▀@└’ūŅ╝čĄ─ł╠(zh©¬)ąąėŗ(j©¼)äØĪŻ╬ęųĖĄ─╩ŪŽ¹║─┘Yį┤ūŅ╔┘Ą─ėŗ(j©¼)äØŻ¼└²╚ń░³║¼ėąöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ę■äš(w©┤)Ų„Ą─CPU║═ŽĄĮy(t©»ng)I/OĪŻę╗ŚlSQL Ą─ł╠(zh©¬)ąąĘų×ķ3éĆ(g©©)ļAČ╬Ż║šZ(y©│)Ę©Ęų╬÷ļAČ╬ĪóšZ(y©│)Šõā×(y©Łu)╗»ļAČ╬Īó▓ķįā(x©▓n)ł╠(zh©¬)ąąļAČ╬ĪŻ
1.1 šZ(y©│)Ę©Ęų╬÷ļAČ╬
šZ(y©│)Ę©Ęų╬÷╩Ūį┌SGAųą═Ļ│╔Ą─Ż¼Ż©SGA╩ŪųĖŽĄĮy(t©»ng)╚½Šųģ^(q©▒)Ż¼░³└©öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŠÅø_ģ^(q©▒)Īóųžū÷╚šųŠŠÅø_ģ^(q©▒)Īó╣▓ŽĒ│žĪójava│žĪó┤¾│žĪó┴„│žŻ®Ż¼į┌▀@└’īósqlšZ(y©│)ŠõĘųĮŌ×ķĻP(gu©Īn)ŽĄ┤·öĄ(sh©┤)▓ķįā(x©▓n)Ż¼ę▓Š═╩Ū═©▀^(gu©░)▀@ą®ĻP(gu©Īn)ŽĄ┤·öĄ(sh©┤)▓ķįā(x©▓n)üĒ(l©ói)“×(y©żn)ūC▀@éĆ(g©©)sqlĄ─šZ(y©│)Ę©ėąø](m©”i)ėąīæ(xi©¦)Õe(cu©░)Ż¼ĻP(gu©Īn)µIūų╩Ūʱš²┤_Ą╚ĪŻ
1.2 šZ(y©│)Šõā×(y©Łu)╗»ļAČ╬
▀@╩Ū▀@3éĆ(g©©)▓Į¾EųąūŅĻP(gu©Īn)µIĄ─ę╗éĆ(g©©)ĄžĘĮ┴╦Ż¼oracle─¼šJ(r©©n)╩╣ė├Ą─╩Ū╗∙ė┌CBOüĒ(l©ói)▀xō±ūŅ║├Ą─ł╠(zh©¬)ąąėŗ(j©¼)äØŻ¼─Ń┐╔─▄Ģ■(hu©¼)å¢(w©©n)Ż¼╔Č╩ŪCBOŻ┐Ż¼║├░╔ŻĪCBOŲõīŹ(sh©¬)Š═╩Ū╗∙ė┌│╔▒ŠĄ─ā×(y©Łu)╗»│╠ą“Ż¼ę▓Š═╩ŪĢ■(hu©¼)īóī”(du©¼)│╔▒ŠŽ¹║─įu(p©¬ng)╣└Ż¼īóŽ¹║─Ą─cpuł╠(zh©¬)ąąų▄Ų┌Īóā╚(n©©i)┤µĪóI/O╦┘┬╩Ą╚┘Yį┤▐D(zhu©Żn)ōQ×ķĢr(sh©¬)ķg│╔▒ŠĪŻĢr(sh©¬)ķgūŅ╔┘Ą─«ö(d©Īng)╚╗Š═╩ŪūŅ║├Ą─┴╦ĪŻ└²╚ńOracleĄ─ĮŌ╬÷ę▓Ęų×ķė▓ĮŌ╬÷║═▄øĮŌ╬÷Ż¼ ī”(du©¼)ė┌▓╗═¼Ą─oracle░µ▒ŠŻ¼ė▓ĮŌ╬÷Ą─┤╬öĄ(sh©┤)ę▓▓╗═¼Ż¼į┌oracle12ųąŻ¼ė▓ĮŌ╬÷Ą─┤╬öĄ(sh©┤)×ķ19┤╬Ż¼į┌oracle11gųąė▓ĮŌ╬÷Ą─┤╬öĄ(sh©┤)×ķ59┤╬ĪŻ
į┌ū÷▀@éĆ(g©©)ļAČ╬Ż¼OracleĢ■(hu©¼)īóšZ(y©│)Ę©Ęų╬÷śõ(sh©┤)▐D(zhu©Żn)ōQ×ķę╗éĆ(g©©)▀ē▌ŗ▓ķįā(x©▓n)Ż¼╚╗║¾īó▀ē▌ŗ▓ķįā(x©▓n)▐D(zhu©Żn)ōQ×ķ╬’└Ē▓ķįā(x©▓n)ėŗ(j©¼)äØĪŻČ°Ūę▀@éĆ(g©©)╬’└Ē▓ķįā(x©▓n)ėŗ(j©¼)äØ▀Ć▓╗ų╣ę╗ĘNŻ¼ę“?y©żn)ķā?y©Łu)╗»Ų„═∙═∙Ģ■(hu©¼)╔·│╔║├ÄūéĆ(g©©)ėąą¦Ą─▓ķįā(x©▓n)ėŗ(j©¼)äØŻ¼╚╗║¾Ģ■(hu©¼)Ė∙ō■(j©┤)▀@ą®ėŗ(j©¼)äØüĒ(l©ói)ū÷│÷│╔▒ŠŽ¹║─įu(p©¬ng)╣└ĪŻūóęŌŻ¼▀@└’ų╗╩Ūū÷┴x╣żįu(p©¬ng)╣└Ż¼▓óø](m©”i)ėą░č├┐ę╗ĘNėŗ(j©¼)äØČ╝╚źł╠(zh©¬)ąąę╗▒ķĪŻ─Ū├┤oracle╩Ūę└ō■(j©┤)╩▓├┤üĒ(l©ói)įu(p©¬ng)╣└Ą──žŻ┐ę╗░ŃĢ■(hu©¼)░┤šš╚ńŽ┬ę“╦ž▀M(j©¼n)ąąįu(p©¬ng)╣└Ż║aĪó▓ķįā(x©▓n)ųą╔µ╝░Ą─▀BĮė▓┘ū„ęį╝░▀BĮėĒśą“ bĪó▓┘ū„ł╠(zh©¬)ąąĄ─╦ŃĘ© cĪóöĄ(sh©┤)ō■(j©┤)ūx╚ĪĄ─ĘĮ╩ĮŻ¼└²╚ńūxā╚(n©©i)┤µ▀Ć╩Ū┤┼▒P(p©ón) dĪó▓ķįā(x©▓n)Ė„▓┘ū„ų«ķgĄ─öĄ(sh©┤)ō■(j©┤)é„▀fĘĮ╩ĮĪŻ
ę╗ŚlsqlšZ(y©│)Šõ▀M(j©¼n)üĒ(l©ói)Ż¼ĄĮūŅĮKī”(du©¼)sqlšZ(y©│)Šõ╔·│╔ł╠(zh©¬)ąąėŗ(j©¼)äØų«Ū░Ż¼ąĶę¬Įø(j©®ng)Üvę╗éĆ(g©©)▀^(gu©░)│╠Ż¼╚ńŽ┬łD╦∙╩ŠŻ©Ó╦čĮŻ¼ļS╩ų«ŗ(hu©ż)Ą─łDŻ¼ «ŗ(hu©ż)Ą├▒╚▌^│¾čĮŻĪŻ®

1.3 ▓ķįā(x©▓n)ł╠(zh©¬)ąą
▓ķįā(x©▓n)ł╠(zh©¬)ąąĢr(sh©¬)ūŅ║å(ji©Żn)å╬Ą─ę╗éĆ(g©©)▓Į¾E┴╦Ż¼ų╗ąĶę¬īóäé▓┼▓Į¾E2Ą─╬’└Ē▓ķįā(x©▓n)ėŗ(j©¼)äØ▀M(j©¼n)ąął╠(zh©¬)ąą╝┤┐╔Ż¼╚╗║¾īó╠Ä└ĒĄ─öĄ(sh©┤)ō■(j©┤)ĘĄ╗žĮoė├æ¶(h©┤)ĪŻ
Č■Īó╗∙ė┌│╔▒ŠĄ─ā×(y©Łu)╗»
2.1 ā×(y©Łu)╗»ĘĮ╩Į
ā×(y©Łu)╗»ĘĮ╩ĮĄ─║¼┴x╩Ū×ķØM(m©Żn)ūŃSQLā×(y©Łu)╗»Ą──┐ś╦(bi©Īo)Č°▀xō±Ą─ā×(y©Łu)╗»ĘĮ╩ĮŻ¼į┌─¼šJ(r©©n)ŪķørŽ┬Ż¼╩ŪęįSQLšZ(y©│)ŠõĄ─═╠═┬┴┐ū„×ķā×(y©Łu)╗»Ą──┐ś╦(bi©Īo)ĪŻ
Ž┬├µ╠ß╣®╚²ĘNā×(y©Łu)╗»ĘĮ╩ĮüĒ(l©ói)ØM(m©Żn)ūŃ▓╗═¼Ą─▓ķįā(x©▓n)ąĶŪ¾Ż║
1ĪóAll_RowsŻ║─¼šJ(r©©n)ĘĮ╩ĮŻ¼ā×(y©Łu)╗»Ą──┐ś╦(bi©Īo)╩ŪīŹ(sh©¬)¼F(xi©żn)▓ķįā(x©▓n)Ą─ūŅ┤¾═╠═┬┴┐
2ĪóFIRST_ROWS_nŻ║ā×(y©Łu)╗»▌ö│÷▓ķįā(x©▓n)Ą─Ū░nąąöĄ(sh©┤)ō■(j©┤)Ż¼─┐ś╦(bi©Īo)╩ŪØM(m©Żn)ūŃ┐ņ╦┘Ą─Ēææ¬(y©®ng)ąĶŪ¾
3ĪóFIRST_ROWSŻ║╩╣ė├CBOĄ─│╔▒Šā×(y©Łu)╗»▒M┐ņ▌ö│÷▓ķįā(x©▓n)Ą─Ū░ÄūąąöĄ(sh©┤)ō■(j©┤)Ż¼ØM(m©Żn)ūŃūŅąĪĒææ¬(y©®ng)Ģr(sh©¬)ķgĄ─ąĶŪ¾
oracle╠ß╣®┴╦╚²ĘN╝ē(j©¬)äe╔ŽĄ─ā×(y©Łu)╗»Ż║īŹ(sh©¬)└²╝ē(j©¬)ĪóĢ■(hu©¼)įÆ(hu©ż)╝ē(j©¬)ĪóšZ(y©│)Šõ╝ē(j©¬)ĪŻ
▓ķįā(x©▓n)«ö(d©Īng)Ū░öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─CBOā×(y©Łu)╗»ĘĮ╩ĮŻ║

┐╔ęį┐┤│÷╬ę«ö(d©Īng)Ū░Ą─öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─ā×(y©Łu)╗»ĘĮ╩Į╩ŪīŹ(sh©¬)¼F(xi©żn)▓ķįā(x©▓n)Ą─ūŅ┤¾═╠═┬┴┐ĪŻ
2.2 ā×(y©Łu)╗»Ų„╣żū„▀^(gu©░)│╠
CBO═©▀^(gu©░)4éĆ(g©©)▓Į¾E▓Į¾E═Ļ│╔SQLĄ─ā×(y©Łu)╗»
1ĪóĖ∙ō■(j©┤)Įy(t©»ng)ėŗ(j©¼)öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ōQSQLšZ(y©│)Šõ Ż║ ę▓Š═╩ŪųĖCBOšJ(r©©n)×ķ▐D(zhu©Żn)ōQ║¾Ą─šZ(y©│)Šõ▓ķįā(x©▓n)Ģ■(hu©¼)Ė³Ė▀ą¦Ż¼╦∙ęįīó─ŃĄ─sqlšZ(y©│)Šõ▐D(zhu©Żn)ōQ×ķ┴Ē═Ōę╗ĘNą╬╩ĮŻ¼└²╚ń─Ńīæ(xi©¦)Ą─OR▐D(zhu©Żn)ōQ×ķ UNION ALLŻ¼īóbetween▐D(zhu©Żn)ōQ×ķ>=║═<=Ą╚ĪŻ
2ĪóĖ∙ō■(j©┤)┘Yį┤Ūķør▀xįL(f©Żng)å¢(w©©n)┬ĘÅĮŻ║ųĖįL(f©Żng)å¢(w©©n)─│éĆ(g©©)┬ĘÅĮĄ─öĄ(sh©┤)ō■(j©┤)╦∙Ž¹║─Ą─┘Yį┤ĪŻ
3ĪóĖ∙ō■(j©┤)Įy(t©»ng)ėŗ(j©¼)öĄ(sh©┤)ō■(j©┤)▀xō±▀BĮėĘĮĘ©Ż║ ╚ń╣¹╔µ╝░ČÓéĆ(g©©)▒ĒŻ¼CBOĢ■(hu©¼)Ė∙ō■(j©┤)Įy(t©»ng)ėŗ(j©¼)öĄ(sh©┤)ō■(j©┤)ęį╝░▒ĒĄ─µIĄ─ą┼ŽóüĒ(l©ói)▀xō±▀BĮėĄ─ĘĮĘ©Ż¼į┌ČÓéĆ(g©©)▀BĮėĘĮĘ©ųą▀xō±ėŗ(j©¼)╦Ń│╔▒ŠūŅĄ═Ą─ę╗éĆ(g©©)ū„×ķūŅ╝č▀BĮėĘĮĘ©ĪŻ
4Īó┤_Č©▀BĮė┤╬ą“Ż║ųĖ╔µ╝░Ą─öĄ(sh©┤)ō■(j©┤)ąąĄ─öĄ(sh©┤)─┐üĒ(l©ói)┤_Č©ūŅ║├Ą─▀BĮė┤╬ą“ĪŻ
2.3 Įy(t©»ng)ėŗ(j©¼)öĄ(sh©┤)ō■(j©┤)
--▓ķ┐┤gather_stats_jobĄ─«ö(d©Īng)Ū░▀\(y©┤n)ąąĀŅæB(t©żi)

--▓ķįā(x©▓n)ė├æ¶(h©┤)scottōĒėą▒ĒĄ─Įy(t©»ng)ėŗ(j©¼)Ęų╬÷ŪķørŻ║sample_size▒Ē╩Š▓╔śėąąöĄ(sh©┤)
select last_analyzedŻ¼table_nameŻ¼ownerŻ¼num_rowsŻ¼sample_size from dba_tables where owner='SCOTT'Ż╗
--×ķ─Ż╩ĮscottĄ─╦∙ėą▒ĒĮy(t©»ng)ėŗ(j©¼)öĄ(sh©┤)ō■(j©┤)(╩ų╣ż╩š╝»)
execute dbms_stats.gather_schema_stats(ownname => 'scott')Ż╗
╚²Īóų„äė(d©░ng)ā×(y©Łu)╗»SQLšZ(y©│)Šõ
3.1 ā×(y©Łu)╗»▓ķįā(x©▓n)
1Īóā×(y©Łu)╗»▓ķįā(x©▓n)Ż║explainŻ¼ī”(du©¼)ė┌╩╣ė├╦„ę²▓ķįā(x©▓n)Ż¼╩╣ė├likeĄ─Ģr(sh©¬)║“ų╗ėą%▓╗į┌Ą┌ę╗éĆ(g©©)╬╗ų├▓┼Ģ■(hu©¼)ėąą¦Ż¼╩╣ė├ČÓ┴ą▓ķįā(x©▓n)Ą─Ģr(sh©¬)║“Ż¼ų╗ėą▓ķįā(x©▓n)Śl╝■ųą╩╣ė├┴╦▀@ą®ūųČ╬ųąĄ─Ą┌ę╗éĆ(g©©)ūųČ╬Ģr(sh©¬)Ż¼╦„ę²▓┼Ģ■(hu©¼)▒╗ę²ė├Ż¼or▓ķįā(x©▓n)Śl╝■Ģr(sh©¬)Ż¼Ū░║¾ā╔éĆ(g©©)Śl╝■ųąĄ─┴ąČ╝╩Ū╦„ę²Ģr(sh©¬)Ż¼▓ķįā(x©▓n)ųą▓┼Ģ■(hu©¼)╩╣ė├╦„ę²ĪŻ
2Īóā×(y©Łu)╗»öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ĮY(ji©”)śŗ(g©░u)Ż¼īóūųČ╬║▄ČÓĄ─▒ĒĘųĮŌ×ķČÓéĆ(g©©)▒ĒŻ¼į÷╝ėųąķg▒ĒŻ¼į÷╝ė╚▀ėÓūųČ╬Ż¼ā×(y©Łu)╗»▓Õ╚ļ╦┘Č╚Ż¼Į¹ė├╬©ę╗ąįÖz▓ķŻ¼╩╣ė├┼·┴┐▓Õ╚ļŻ¼Į¹ų╣═ŌµIÖz▓ķŻ¼Į¹ų╣ūįäė(d©░ng)╠ßĮ╗Ż¼ā×(y©Łu)╗»▒Ēoptimize
3Īóā×(y©Łu)╗»öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─Ę■äš(w©┤)Ų„Ż¼ė▓╝■Ż║ā╚(n©©i)┤µŻ¼ioŻ¼ ā×(y©Łu)╗»ģóöĄ(sh©┤)ĪŻ
4Īó╩╣ė├ĮēČ©ūā┴┐Ż║╬ęéāČ╝ų¬Ą└Ż¼į┌Oracleųą╩ŪĘų×ķ┴╦ė▓ĮŌ╬÷║═▄øĮŌ╬÷Ą─Ż¼į┌SGAųąŻ¼╣▓ŽĒ│žŠ═╩Ū┤µĘ┼ĮŌ╬÷║¾Ą─SQLšZ(y©│)ŠõŻ¼┤╦Ģr(sh©¬)Ą─╣▓ŽĒ│ž░³║¼SQLšZ(y©│)ŠõĄ─ūŅĮKł╠(zh©¬)ąąėŗ(j©¼)äØĪŻ╚ń╣¹ėąŽÓ═¼Ą─╩ŪSQL▓ķįā(x©▓n)šZ(y©│)ŠõŻ¼Š═▓╗ąĶę¬į┘┤╬ĮŌ╬÷SQLšZ(y©│)Šõ┴╦Ż¼Č°╩Ūų▒ĮėÅ─╣▓ŽĒ│žųął╠(zh©¬)ąąSQLšZ(y©│)ŠõĄ─ł╠(zh©¬)ąąėŗ(j©¼)äØĪŻ╩╣ė├╣▓ŽĒ│žŠ═╩Ū×ķ┴╦▒▄├Ōė▓ĮŌ╬÷Ą─░l(f©Ī)╔·Ż¼ę“?y©żn)ķ├┐┤╬╚ź▀M(j©¼n)ąąė▓ĮŌ╬÷Ą─Ģr(sh©¬)║“Č╝ąĶę¬ųžą┬╚źĘų╬÷šZ(y©│)ŠõĄ─šZ(y©│)Ę©šZ(y©│)┴xŻ¼╚╗║¾═©▀^(gu©░)CBOā×(y©Łu)╗»╔·│╔Ą─ūŅĮKł╠(zh©¬)ąąėŗ(j©¼)äØŻ¼▀@śėŠ═║▄Ž¹║─CPUĄ─┘Yį┤ĪŻ╩╣ė├ĮēČ©ūā┴┐Ż¼ę▓Š═╩Ū╬ęéā?c©©)┌javaķ_(k©Īi)░l(f©Ī)ųą│ŻęŖ(ji©żn)Ą─Įoę╗éĆ(g©©)sqlšZ(y©│)Šõ╝ėę╗éĆ(g©©)Ż┐üĒ(l©ói)ł╠(zh©¬)ąąŻ¼╚╗║¾į┘é„╚ļ?y©▓n)óö?sh©┤)ĪŻ
└²╚ńŻ║ select enameŻ¼jobŻ¼sal from scott.emp where deptno=Ż┐
╚╗║¾╬ęéā?c©©)┘░čģóö?sh©┤)é„╚ļŻ¼▀@śė▓╗āH┐╔ęįĘ└ų╣SQLūó╚ļŻ¼Č°Ūę┐╔ęįī”(du©¼)SQL▀M(j©¼n)ąąā×(y©Łu)╗»ĪŻ
5ĪóŽ¹│²ūė▓ķįā(x©▓n)Ż║ī”(du©¼)ė┌ę╗ą®ŪČ╠ūĄ─ūė▓ķįā(x©▓n)Ż¼īóŪČ╠ūĄ─sqlšZ(y©│)ŠõŻ¼└²╚ńŻ║

▀@śėĄ─ę╗ŚlsqlšZ(y©│)Šõ├┐┤╬ąĶꬳ╠(zh©¬)ąąN*M┤╬▓┘ū„Ż¼Š▀¾wöĄ(sh©┤)ųĄ─Ń┐╔ęį╩╣ė├Ž┬╬─ųą╩ŪsqlĖ·█Ö▀M(j©¼n)ąąąį─▄Ęų╬÷ĪŻ
ā×(y©Łu)╗»║¾Ą─šZ(y©│)Šõ×ķŻ║

ā×(y©Łu)╗»║¾Ą─▀@Ślsqlų╗ąĶę¬▀M(j©¼n)ąąN+M┤╦▓┘ū„╝┤┐╔Ż¼Ųõ╔ņ┐sąįĖ³ÅŖ(qi©óng)Ż¼ėŗ(j©¼)╦ŃĮY(ji©”)╣¹ę▓▓╗Ģ■(hu©¼)│╩ųĖöĄ(sh©┤)į÷ķL(zh©Żng)ĪŻļm╚╗│§▓Į┐┤ŲüĒ(l©ói)ā×(y©Łu)╗»║¾Ą─sqlšZ(y©│)Šõ╦Ų║§Ė³ķL(zh©Żng)ę╗³c(di©Żn)Ż¼╚ń╣¹─Ńį┌┘|(zh©¼)ę╔ĄĮĄūī”(du©¼)▓╗ī”(du©¼)Ż¼─Ń┐╔ęį╩╣ė├╬ęéāĮėŽ┬üĒ(l©ói)ųvĄĮĄ─SQLšZ(y©│)ŠõĘų╬÷╣żŠ▀üĒ(l©ói)▀M(j©¼n)ąąī”(du©¼)▒╚Ż¼┤¾╝ę┐╔ęį═©▀^(gu©░)Ųõł╠(zh©¬)ąąėŗ(j©¼)äØüĒ(l©ói)“×(y©żn)ūCĪŻ
3.2 SQLšZ(y©│)Šõā×(y©Łu)╗»╣żŠ▀
╩╣ė├explain plan for ųĖ┴ŅüĒ(l©ói)½@Ą├SQLšZ(y©│)ŠõĄ─ł╠(zh©¬)ąąėŗ(j©¼)äØŻ¼╦∙ęį╬ęéāŽ╚üĒ(l©ói)äō(chu©żng)Į©ę╗éĆ(g©©)ł╠(zh©¬)ąą▀@éĆ(g©©)ųĖ┴Ņ╦∙ąĶꬥ─▒ĒŻ¼į┌oracleĄ─░▓čb─┐õøųąŻ¼╬ęéāąĶ꬚ęĄĮutlxplan.sql▀@éĆ(g©©)╬─╝■Ż¼╚╗║¾ł╠(zh©¬)ąąĪŻ╬ę▀@└’Ą─▀@éĆ(g©©)╬─╝■Ą─┬ĘÅĮ╬╗ė┌EŻ║\oracle\app\product\11.2.0\dbhome_1\RDBMS\ADMIN\utlxplan.sqlŻ¼ł╠(zh©¬)ąą├³┴Ņ╚ńŽ┬Ż║
▒Ēęčäō(chu©żng)Į©
▓ķ┐┤▀@éĆ(g©©)▒ĒĮY(ji©”)śŗ(g©░u)Ż║
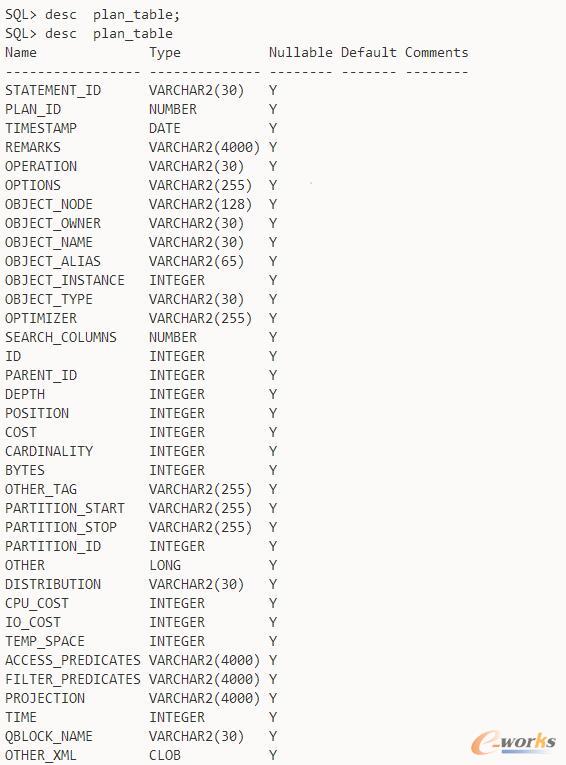
╚╗║¾╬ęéā═©▀^(gu©░)▀@éĆ(g©©)├³┴ŅüĒ(l©ói)Ęų╬÷SQLšZ(y©│)ŠõĄ─ł╠(zh©¬)ąąŻ║
SQL> explain plan for
2 select count(*) from scott.empŻ╗
Explained
╬ęéāüĒ(l©ói)▓ķ┐┤ę╗Ž┬plan_table▒ĒųąĄ─sqlšZ(y©│)Šõł╠(zh©¬)ąąėŗ(j©¼)äØą┼ŽóŻ║
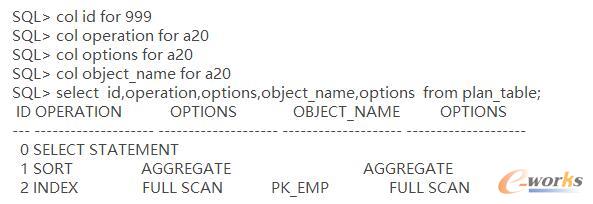
╬ęéā┐╔ęį┐┤ĄĮŻ¼▀@╩Ūę╗éĆ(g©©)╚½▒ĒÆ▀├ĶĄ─Ż¼▒Ē├„╩ŪempĪŻ
╚ń╣¹╬ęéāŽļę¬Ė³╔Ņ╚ļĄ─ī”(du©¼)▀@Ślsql▀M(j©¼n)ąąĘų╬÷į§├┤▐kŻ¼└²╚ńŽļę¬ų¬Ą└▀@éĆ(g©©)Ą─įL(f©Żng)å¢(w©©n)ī”(du©¼)Ž¾ĪóŽ¹║─Ą─CPUĄ╚ą┼ŽóĪŻ─Ū├┤╬ęéā┐╔ęįåóė├SQLūĘ█ÖĪŻ
1Īó╩╣ė├autotraceųĖ┴Ņ
╩╣ė├įōųĖ┴Ņ┐╔ęįĖ·█ÖSQLšZ(y©│)Šõ▓óĘų╬÷Ųõł╠(zh©¬)ąą▓Į¾EŻ¼Įy(t©»ng)ėŗ(j©¼)ą┼Žó╚ń╬’└ĒūxöĄ(sh©┤)ō■(j©┤)┴┐Īó┤┼▒P(p©ón)║═ā╚(n©©i)┤µ┼┼ą“öĄ(sh©┤)ō■(j©┤)┴┐ĪŻ
Š▀¾wĄ─▓┘ū„├³┴Ņ╚ńŽ┬Ż║

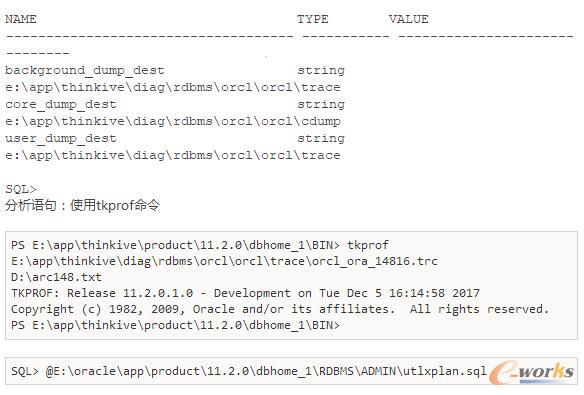
üĒ(l©ói)┐┤ę╗Ž┬▀@éĆ(g©©)╔·│╔║├Ą─╬─╝■Ż©▓┐Ęųā╚(n©©i)╚▌Ż¼ę“?y©żn)ķ╔·│╔Ą─ā?n©©i)╚▌▒╚▌^ČÓŻ¼╦∙ęį▀@└’▓╗═Ļ╚½┘N╔ŽüĒ(l©ói)Ż¼ąĶę¬▓ķ┐┤Ą─┼¾ėč┐╔ęįūį╝║╚źł╠(zh©¬)ąąę╗éĆ(g©©)sqlūĘ█Ö╚╗║¾▓ķ┐┤Ż®Ż║
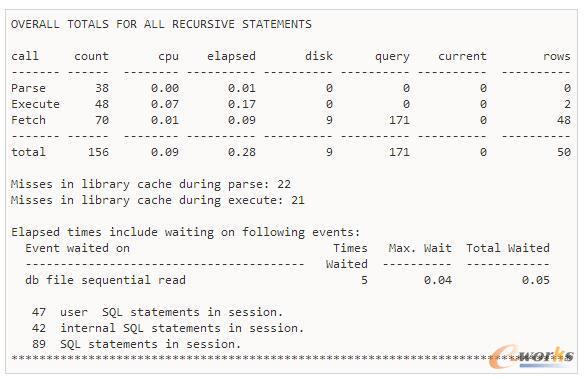
į┌▀@Č╬▌ö│÷ųąŻ¼┐╔ęį┐┤│÷Ż¼SQLšZ(y©│)Šõ▒╗ł╠(zh©¬)ąą┴╦38┤╬Ż¼┐é╣▓║─Ģr(sh©¬)0.01├ļŻ¼šZ(y©│)Šõ▒╗ł╠(zh©¬)ąą┴╦48┤╬Ż¼įÆ(hu©ż)┘M(f©©i)Ģr(sh©¬)ķg╩Ū0.17├ļŻ¼į┌ĮŌ╬÷║═ł╠(zh©¬)ąąŲ┌ķgø](m©”i)ėą┤┼▒P(p©ón)I/O║═ŠÅø_ģ^(q©▒)ūx╚Ī▓┘ū„Ż¼fetch▓┘ū„ł╠(zh©¬)ąą┴╦70┤╬Ż¼║─Ģr(sh©¬)0.09├ļŻ¼╔µ╝░┴╦9┤╬┤┼▒P(p©ón)ūx╚Īęį╝░171┤╬ŠÅø_ģ^(q©▒)ūx╚Ī▓┘ū„Ż¼┐é╣▓ūx╚Ī┴╦0éĆ(g©©)öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ēKŻ¼╔µ╝░50ąąöĄ(sh©┤)ō■(j©┤)ĪŻ
į┌Äņ(k©┤)ŠÅ┤µųąüG╩¦Ą─├³ųą┤╬öĄ(sh©┤)╩Ū22┤╬Ż¼šf(shu©Ł)├„ėą22┤╬ė▓ĮŌ╬÷│÷¼F(xi©żn)ĪŻūŅ║¾šf(shu©Ł)├„╩Ū47éĆ(g©©)ė├æ¶(h©┤)SQLšZ(y©│)ŠõŻ¼42éĆ(g©©)ā╚(n©©i)▓┐SQLšZ(y©│)Šõ┐é╣▓╔µ╝░89éĆ(g©©)SQLšZ(y©│)ŠõĪŻ
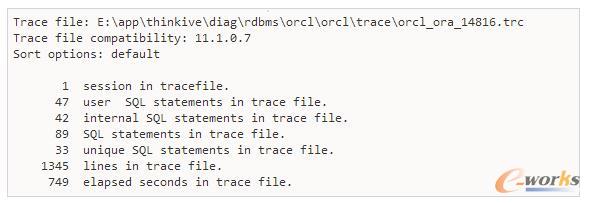
╦─Īó▒╗äė(d©░ng)ā×(y©Łu)╗»SQL
į┌│╠ą“┤“░³║¾Ż¼╗“š▀ŽĄĮy(t©»ng)▀\(y©┤n)ąą║¾╚ń║╬üĒ(l©ói)ā×(y©Łu)╗»SQLšZ(y©│)ŠõŻ¼ę╗░ŃŠ═╩ŪĮ©┴ó╗“äh│²╦„ę²ĪóĮ©┴óĘųģ^(q©▒)▒ĒĄ╚▓┘ū„Ż¼Ž┬├µųĖĮo│÷ę╗ą®╦╝┬ĘŻ¼Š▀¾wĄ─īŹ(sh©¬)¼F(xi©żn)▀Ć╩ŪąĶę¬į┌īŹ(sh©¬)ļH╣żū„ųą▓┼─▄ŅI(l©½ng)Ģ■(hu©¼)ĪŻ
1Īó╩╣ė├Ęųģ^(q©▒)▒Ē
2Īóäō(chu©żng)Į©ē║┐s▒ĒŻ║įŁ└ĒŠ═╩ŪŻ¼īó▒ĒųąųžÅ═(f©┤)Ą─öĄ(sh©┤)ō■(j©┤)╚źĄ¶Ż¼▓╔ė├╦ŃĘ©üĒ(l©ói)╠µōQ▀@ą®ųžÅ═(f©┤)Ą─ųĄŻ¼į┌ąĶꬥ─Ģr(sh©¬)║“Ż¼ė├╦ŃĘ©╚źųžĮ©▀@ą®ųžÅ═(f©┤)Ą─öĄ(sh©┤)ō■(j©┤)Ż¼Å─Č°īŹ(sh©¬)¼F(xi©żn)ī”(du©¼)▒ĒĄ─ē║┐sĪŻ
šZ(y©│)Šõ×ķŻ╗

3Īóäō(chu©żng)Į©ē║┐s╦„ę²Ż║įŁ└Ē═¼ē║┐s▒ĒŻ¼ų„ꬊ═╩Ū╚źĄ¶╦„ę²ųąĄ─ųžÅ═(f©┤)ųĄŻ¼ė╚Ųõī”(du©¼)ė┌┤¾▒ĒŻ¼┐╔ęį£p╔┘┤µā”(ch©│)┐šķg▓óį÷ÅŖ(qi©óng)▓ķįā(x©▓n)ąį─▄ĪŻ
šZ(y©│)Šõ×ķŻ║

4Īó▒Ż│ųCBOĄ─ĘĆ(w©¦n)Č©ąįŻ¼äō(chu©żng)Į©┤µā”(ch©│)┤¾ŠVŻ¼Ęų×ķ╚²ĘNŻ╗ öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╝ē(j©¬)äeĄ─┤µā”(ch©│)┤¾ŠVĪóĢ■(hu©¼)įÆ(hu©ż)╝ē(j©¬)äeĄ─┤µā”(ch©│)┤¾ŠVĪóSQLšZ(y©│)Šõ╝ē(j©¬)äeĄ─┤µā”(ch©│)┤¾ŠV
5Īó╩╣ė├V$SQLęĢłD
└²╚ń┐╔ęį▓ķįā(x©▓n)Ž¹║─┤┼▒P(p©ón)I/OūŅČÓĄ─šZ(y©│)ŠõŻ¼ŠÅø_ģ^(q©▒)ūx╚Ī┤╬öĄ(sh©┤)ūŅČÓĄ─SQLšZ(y©│)ŠõĄ╚ĪŻ
--▓ķįā(x©▓n)ūįīŹ(sh©¬)└²åóäė(d©░ng)ęįüĒ(l©ói)┤┼▒P(p©ón)IOūŅČÓĄ─sqlšZ(y©│)Šõ

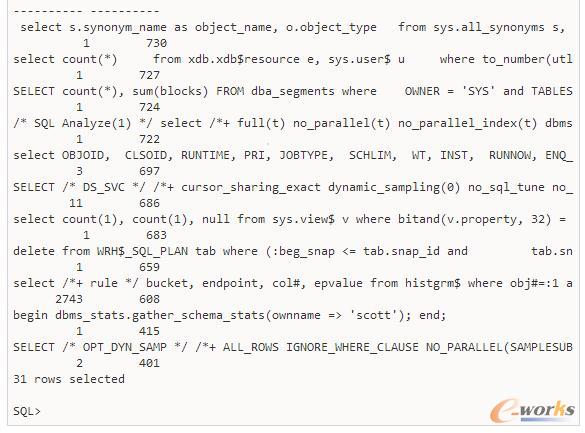
╬ÕĪó╦„ę²ŅÉ(l©©i)ą═╝░╩╣ė├Ģr(sh©¬)ÖC(j©®)
šf(shu©Ł)ĄĮöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─ā×(y©Łu)╗»Ż¼▓╗Ą├▓╗╠ߥ─Š═╩Ū╦„ę²┴╦Ż¼Ž┬├µįö╝Ü(x©¼)üĒ(l©ói)ųvĮŌę╗Ž┬oracleĄ─╦„ę²ŅÉ(l©©i)ą═╝░Ųõ╩╣ė├Ģr(sh©¬)ÖC(j©®)ĪŻ
1ĪóB-śõ(sh©┤)╦„ę²
B-śõ(sh©┤)╦„ę²╩ŪOracle─¼šJ(r©©n)Ą─╦„ę²ŅÉ(l©©i)ą═ĪŻ╚~ūė╣Ø(ji©”)³c(di©Żn)░³║¼╦„ę²Ą─īŹ(sh©¬)ļHųĄ║═įō╦„ę²Śl─┐Ą─ąąIDĪŻĘų×ķĖ∙╣Ø(ji©”)³c(di©Żn)ĪóĘųų¦╣Ø(ji©”)³c(di©Żn)Īó╚~ūė╣Ø(ji©”)³c(di©Żn)3éĆ(g©©)▓┐ĘųŻ¼ŲõųąĖ∙╣Ø(ji©”)³c(di©Żn)╬╗ė┌╦„ę²Ą─ūŅĒöČ╦ĪŻį┌╚~ūė╣Ø(ji©”)³c(di©Żn)ųą┤µā”(ch©│)┴╦īŹ(sh©¬)ļHĄ─╦„ę²┴ąĄ─ųĄ║═įō┴ąī”(du©¼)æ¬(y©®ng)Ą─ėøõøĄ─ąąIDŻ¼╦³╩Ū╬©ę╗Ą─OracleųĖßśŻ¼ųĖŽ“įōąąĄ─╬’└Ē╬╗ų├Ż¼╚~ūė╣Ø(ji©”)³c(di©Żn)ŲõīŹ(sh©¬)Š═╩Ūę╗éĆ(g©©)ļpŽ“µ£▒ĒŻ¼├┐éĆ(g©©)╚~ūė╣Ø(ji©”)³c(di©Żn)░³║¼ę╗éĆ(g©©)ųĖŽ“Ž┬ę╗éĆ(g©©)║═╔Žę╗éĆ(g©©)╚~ūė╣Ø(ji©”)³c(di©Żn)Ą─ųĖßśŻ¼▀@śėį┌ę╗Č©ĘČć·ā╚(n©©i)▒Ń└¹ė├╦„ę²ęį╦č╦„ąĶꬥ─ėøõøĪŻ
2Īó╬╗łD╦„ę²
╬╗łD╦„ę²╩╣ė├╬╗łDś╦(bi©Īo)ūR(sh©¬)╦„ę²Ą─┴ąųĄŻ¼╦³▀mė├ė┌ø](m©”i)ėą┤¾┴┐öĄ(sh©┤)ō■(j©┤)Ė³ą┬Īóäh│²║═▓Õ╚ļ▓┘ū„Ą─öĄ(sh©┤)ō■(j©┤)é}(c©Īng)Äņ(k©┤)ĪŻę“?y©żn)ķ╩╣ė├╬╗łD╦„ę²Ģr(sh©¬)Ż¼├┐éĆ(g©©)╬╗łD╦„ę²ĒŚ(xi©żng)┼c▒Ēųą┤¾┴┐Ą─ąąėąĻP(gu©Īn)┬ō(li©ón)Ż¼«ö(d©Īng)▒Ēųąėą┤¾┴┐Ą─į÷ähĖ─▓┘ū„Ą─Ģr(sh©¬)║“Ż¼╬╗łD╦„ę²Ēō(y©©)ąĶꬎÓæ¬(y©®ng)Ą─Ė─ūāŻ¼Č°Ūę╦„ę²Ģ■(hu©¼)š╝ė├ę╗Č©Ą─┤┼▒P(p©ón)┐šķgŻ¼▓óŪę╦„ę²į┌Ė³ą┬Ą─Ģr(sh©¬)║“╩▄ė░ĒæĄ─╦„ę²ąąąĶꬵiČ©ĪŻ
└²╚ń╬ęéāł╠(zh©¬)ąą╚ńŽ┬šZ(y©│)ŠõŻ║
SELECT EMPNOŻ¼ENAMEŻ¼jobŻ¼SAL FROM scott.emp WHERE JOB='SALESMAN'Ż╗
─┐Ą─Š═╩Ūį┌empųą▓ķ│÷┬Ü╬╗×ķsalesmanĄ─åT╣żą┼ŽóŻ¼▀@└’╬ęéā?y©Łu)ķŲõĮ©┴ó╬╗łD╦„ę²Ż¼ĮY(ji©”)śŗ(g©░u)╚ńŽ┬łD╦∙╩ŠŻ©╝ā╩ų╣ż└LłDŻ®Ż║
äō(chu©żng)Į©╬╗łD╦„ę²Ą─šZ(y©│)Šõ×ķŻ║
create bitmap index emp_job_bitmap_idx on emp(job)Ż╗
3ĪóĘ┤Ž“µI╦„ę²
╩ŪųĄį┌äō(chu©żng)Į©╦„ę²▀^(gu©░)│╠ųąī”(du©¼)╦„ę²┴ąäō(chu©żng)Į©Ą─╦„ę²µIųĄĄ─ūų╣Ø(ji©”)Ę┤Ž“Ż¼╩╣ė├Ę┤Ž“µI╦„ę²Ą─║├╠Ä╩ŪīóųĄ▀B└m(x©┤)▓Õ╚ļĄĮ╦„ę²ųąĢr(sh©¬)Ę┤Ž“µI─▄▒▄├ŌĀÄ(zh©źng)ė├ĪŻ╩╣ė├Ę┤Ž“µI╦„ę²╩╣Ą├├┐éĆ(g©©)µIųĄ▒╗ŅŹĄ╣┴╦Ēśą“Ż¼īó╦„ę²Ą─µIųĄĘų╔óķ_(k©Īi)ĪŻ
└²╚ńŻ║
46892 ----> 29864
Horoscope ---> eposcoroH
äō(chu©żng)Į©Ę┤Ž“µI╦„ę²ąĶę¬╩╣ė├reverseĻP(gu©Īn)µIūųĪŻ
create index emp_sal_reverse_idx on emp(sal) reverseŻ╗
4Īó╗∙ė┌║»öĄ(sh©┤)Ą─╦„ę²
ė├æ¶(h©┤)▓ķįā(x©▓n)Ģr(sh©¬)Ż¼╚ń╣¹▓ķįā(x©▓n)šZ(y©│)ŠõĄ─whereūėŠõųąėą║»öĄ(sh©┤)┤µį┌Ż¼oracleīó╩╣ė├║»öĄ(sh©┤)╦„ę²╝ė┐ņ▓ķįā(x©▓n)╦┘Č╚ĪŻ
create index dept_dname_idx on dept9UPPERŻ©dname)Ż®Ż╗
╚ń╔Ž╦∙╩ŠŻ¼╬ęéāäō(chu©żng)Į©┴╦ę╗éĆ(g©©)╗∙ė┌▒Ēdeptųą┴ądnameĄ─║»öĄ(sh©┤)╦„ę²Ż¼äō(chu©żng)Į©įō╦„ę²Ģr(sh©¬)╩ūŽ╚īó┴ądnameųąĄ─ųĄ▐D(zhu©Żn)ōQ×ķ┤¾īæ(xi©¦)Ż¼╚╗║¾ī”(du©¼)┤¾īæ(xi©¦)Ą─dnameäō(chu©żng)Į©╦„ę²Ż¼Ę┼╚ļ╦„ę²▒ĒĪŻ┘Yį┤«ö(d©Īng)ė├æ¶(h©┤)ąĶę¬▀M(j©¼n)ąą╚ńŽ┬▓ķįā(x©▓n)Ą─Ģr(sh©¬)║“Š═Ģ■(hu©¼)śO┤¾Ą─╠ßĖ▀▓ķįā(x©▓n)╦┘Č╚ĪŻ
select UPPER(dname) from scott.dept where UPPER(dname) ='SALES'Ż╗
┴∙ĪóSGAįöĮŌ
OracleĄ─SGA╩ŪųĖŽĄĮy(t©»ng)╚½Šųģ^(q©▒)Ż¼╦³░³└©öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŠÅø_ģ^(q©▒)Īóųžū÷╚šųŠŠÅø_ģ^(q©▒)Īó╣▓ŽĒ│žĪójava│žĪó┤¾│žĪó┴„│žĪŻę¬ā×(y©Łu)╗»SGAŠ═╩Ū꬚{(di©żo)š¹▀@ą®öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ĮM╝■Ą─ģóöĄ(sh©┤) Ż¼▀@ą®ĮM╝■Š═╩ŪīŹ(sh©¬)└²ā×(y©Łu)╗»Ą─▓┘ū„ī”(du©¼)Ž¾Ż¼Å─Č°╠ßĖ▀ŽĄĮy(t©»ng)Ą─▀\(y©┤n)ąąą¦┬╩Ż¼╚ń╠ßĖ▀ė├æ¶(h©┤)▓ķįā(x©▓n)Ą─Ēææ¬(y©®ng)╩┬╝■Ą╚ĪŻ
öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ŠÅø_ģ^(q©▒)Ż║┤µĘ┼ė├æ¶(h©┤)Å─Äņ(k©┤)ųąūx╚ĪĄ─öĄ(sh©┤)ō■(j©┤)Ż¼ė├æ¶(h©┤)▓ķšęöĄ(sh©┤)ō■(j©┤)Ģ■(hu©¼)Ž╚į┌▀@└’▀M(j©¼n)ąą▓ķšęŻ¼╚ń╣¹ø](m©”i)ėą▓┼Ģ■(hu©¼)╚źūxöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)╬─╝■Ż¼╦∙ęįįōģ^(q©▒)ė“Ą─įO(sh©©)ų├▓╗─▄▀^(gu©░)ąĪĪŻ
ųžū÷╚šųŠŠÅø_ģ^(q©▒)Ż║▀@└’Ę┼ų├ė├æ¶(h©┤)Ė─ūāĄ─öĄ(sh©┤)ō■(j©┤)Ż¼╦∙ėąūā╗»┴╦Ą─öĄ(sh©┤)ō■(j©┤)║═ąĶę¬╗žØLĄ─öĄ(sh©┤)ō■(j©┤)Č╝Ģ║Ģr(sh©¬)▒Ż┤µį┌▀@└’ĪŻ
╣▓ŽĒ│žŻ║░³└©öĄ(sh©┤)ō■(j©┤)ūųĄõĖ▀╦┘ŠÅ┤µ║═Äņ(k©┤)Ė▀╦┘ŠÅ┤µŻ¼Äņ(k©┤)Ė▀╦┘ŠÅ┤µ┤µĘ┼oracleĮŌ╬÷Ą─SQLšZ(y©│)ŠõĪóPL/SQL▀^(gu©░)│╠Īó░³ęį╝░Ė„ĘN┐žųŲĮY(ji©”)śŗ(g©░u)Ż¼╚ń▒ĒĪóÄņ(k©┤)ŠÅø_Šõ▒·Ą╚ĪŻ
java│žŻ║ł╠(zh©¬)ąąjava┤·┤aĄ─ģ^(q©▒)ė“Ż¼╩Ū×ķ▀\(y©┤n)ąąJVMĘų┼õĄ─ę╗Č╬╣╠Č©┤¾ąĪĄ─ā╚(n©©i)┤µĪŻ
┤¾│žŻ║įōā╚(n©©i)┤µģ^(q©▒)╠ß╣®┤¾ą═Ą─ā╚(n©©i)┤µĘų┼õŻ¼į┌╣▓ŽĒĘ■äš(w©┤)Ų„▀BĮė─Ż╩ĮŽ┬╠ß╣®Ģ■(hu©¼)įÆ(hu©ż)ģ^(q©▒)Ż¼į┌╩╣ė├RMANéõĘ▌╩Ūę▓╩╣ė├įōā╚(n©©i)┤µģ^(q©▒)ū„×ķ┤┼▒P(p©ón)IOĄ─öĄ(sh©┤)ō■(j©┤)ŠÅø_ģ^(q©▒)ĪŻ
┴„│žŻ║┴„ā╚(n©©i)┤µŻ¼×ķoracle┴„īŻ(zhu©Īn)ė├Ą─ā╚(n©©i)┤µ│žŻ¼┴„╩ŪųĖoracleöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)ųąĄ─ę╗éĆ(g©©)öĄ(sh©┤)ō■(j©┤)╣▓ŽĒĪŻ

ī”(du©¼)ė┌öĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ą─ā×(y©Łu)╗»╩Ūę╗éĆ(g©©)║▄╔Ņ╚ļĄ─ā╚(n©©i)╚▌┴╦Ż¼└²╚ń▀Ćėą┐╔ęį?x©▓n)?y©Łu)╗»ųžū÷╚šųŠŠÅø_ģ^(q©▒)Īóā×(y©Łu)╗»╣▓ŽĒ│žā×(y©Łu)╗»PGAā╚(n©©i)┤µĄ╚ĘĮ├µĄ─ā╚(n©©i)╚▌Ż¼
╚šųŠŠÅø_ģ^(q©▒)ųąīóŠÅø_īæ(xi©¦)╚ļĄĮ╚šųŠ╬─╝■ųąĄ─ĘĮ╩Įėą├┐Ė¶3├ļ╠ßĮ╗ĪóöĄ(sh©┤)ō■(j©┤)┤¾ė┌1MBĄ─Ģr(sh©¬)║“ĪóÖz“×(y©żn)³c(di©Żn)░l(f©Ī)╔·Ģr(sh©¬)Īó«ö(d©Īng)DBWR▀M(j©¼n)│╠īóöĄ(sh©┤)ō■(j©┤)Äņ(k©┤)Ė▀╦┘ŠÅø_ģ^(q©▒)ųąĄ─öĄ(sh©┤)ō■(j©┤)īæ(xi©¦)ĄĮöĄ(sh©┤)ō■(j©┤)╬─╝■Ū░Ż¼╚šųŠŠÅø_ģ^(q©▒)Ą─ā×(y©Łu)╗»Š═╩Ūš{(di©żo)š¹log_buffer_pace╗“š▀īó▓╗═¼Ą─╬─╝■Ę┼į┌▓╗═¼Ą─┤┼▒P(p©ón)╔Žęį▒▄├Ōø_═╗ĪŻ
PGA╩Ūę╗éĆ(g©©)│╠ą“╚½Šųģ^(q©▒)Ż¼┐╔ęįū„×ķ┤¾ęÄ(gu©®)─ŻĄ─öĄ(sh©┤)ō■(j©┤)┼┼ą“Ż¼Č°▓╗ąĶę¬╚ź╩╣ė├╠ōöMā╚(n©©i)┤µČ°š╝ė├▓┘ū„ŽĄĮy(t©»ng)Ą─Į╗ōQģ^(q©▒)ĪŻ
Ė³×ķįö╝Ü(x©¼)Ą─ā╚(n©©i)╚▌į┌▒Š╬─Š═▓╗į┘šf(shu©Ł)├„Ż¼Ėą┼d╚żĄ─┼¾ėč┐╔ęįūįąą▓ķķåŽÓĻP(gu©Īn)┘Y┴ŽĪŻīW(xu©”)┴Ģ(x©¬)ę╗ą®SQLĄ─ĄūīėŻ¼┐╔ęįĖ³║├Ą─ą▐¤Æā╚(n©©i)╣”ĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_(t©ói)╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N(y©┤n)║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ć(l©żi)ŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšł(q©½ng)ūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.hanmeixuan.com/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║╗∙ė┌CBOĄ─SQLā×(y©Łu)╗»║═OracleīŹ(sh©¬)└²ā×(y©Łu)╗»
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.hanmeixuan.com/html/support/11121824042.html



▀xą═ųąą─")
¾w“×(y©żn)ųąą─")
«a(ch©Żn)ŲĘ┘Å(g©░u)┘I(m©Żi)")
æ(zh©żn)┬į║Žū„")