1Īóę²čį
ļSų°ęį▓®┐═Īó╔ńĮ╗ŠWĮjĪó╗∙ė┌╬╗ų├Ą─Ę■äšLBS ×ķ┤·▒ĒĄ─ą┬ą═ą┼Žó░l(f©Ī)▓╝ĘĮ╩ĮĄ─▓╗öÓė┐¼F(xi©żn)Ż¼ęį╝░įŲėŗ╦ŃĪó╬’┬ō(li©ón)ŠWĄ╚╝╝ągĄ─┼dŲŻ¼öĄ(sh©┤)ō■š²ęįŪ░╦∙╬┤ėąĄ─╦┘Č╚į┌▓╗öÓĄ─į÷ķL║═└█ĘeŻ¼┤¾öĄ(sh©┤)ō■Ģr┤·ęčĮøüĒĄĮĪŻīWągĮńĪó╣żśI(y©©)Įń╔§ų┴ė┌š■Ė«ÖCśŗČ╝ęčĮøķ_╩╝├▄ŪąĻPūó┤¾öĄ(sh©┤)ō■å¢Ņ}Ż¼▓óī”Ųõ«a╔·ØŌ║±Ą─┼d╚żĪŻŠ═īWągĮńČ°čįŻ¼Nature įńį┌2008 ─ĻŠ══Ų│÷┴╦Big Data īŻ┐»ĪŻėŗ╦Ń╔ńģ^(q©▒)┬ō(li©ón)├╦(Computing Community Consortium)į┌2008 ─Ļ░l(f©Ī)▒Ē┴╦ł¾ĖµĪČBig-Data Computing: Creatingrevolutionary breakthroughs in commerce, science, and societyĪĘ,ĻU╩÷┴╦į┌öĄ(sh©┤)ō■“īäėĄ─蹊┐▒│Š░Ž┬Ż¼ĮŌøQ┤¾öĄ(sh©┤)ō■å¢Ņ}╦∙ąĶĄ─╝╝ągęį╝░├µ┼RĄ─ę╗ą®╠¶æ(zh©żn)ĪŻScience į┌2011 ─Ļ2 į┬═Ų│÷īŻ┐»ĪČDealing with DataĪĘŻ¼ų„ę¬ć·└@ų°┐ŲīW蹊┐ųą┤¾öĄ(sh©┤)ō■Ą─å¢Ņ}š╣ķ_ėæšōŻ¼šf├„┤¾öĄ(sh©┤)ō■ī”ė┌┐ŲīW蹊┐Ą─ųžę¬ąįĪŻ├└ć°ę╗ą®ų¬├¹Ą─öĄ(sh©┤)ō■╣▄└ĒŅIė“Ą─īŻ╝ęīWš▀ätÅ─īŻśI(y©©)Ą─蹊┐ĮŪČ╚│÷░l(f©Ī)Ż¼┬ō(li©ón)║Ž░l(f©Ī)▓╝┴╦ę╗Ę▌░ūŲżĢ°ĪČChallenges and Opportunities with Big DataĪŻįō░ūŲżĢ°Å─īWągĄ─ĮŪČ╚│÷░l(f©Ī)Ż¼ĮķĮB┴╦┤¾öĄ(sh©┤)ō■Ą─«a╔·Ż¼Ęų╬÷┴╦┤¾öĄ(sh©┤)ō■Ą─╠Ä└Ē┴„│╠Ż¼▓ó╠ß│÷┤¾öĄ(sh©┤)ō■╦∙├µ┼RĄ─╚¶Ė╔╠¶æ(zh©żn)ĪŻ
╚½Ū“ų¬├¹Ą─ū╔įā╣½╦Š¹£┐ŽÕa(McKinsey)╚ź─Ļ6 į┬Ę▌░l(f©Ī)▓╝┴╦ę╗Ę▌ĻPė┌┤¾öĄ(sh©┤)ō■Ą─įö▒Mł¾ĖµĪČBig data: The next frontier for innovation, competition, and productivityĪĘŻ¼ī”┤¾öĄ(sh©┤)ō■Ą─ė░ĒæĪóĻPµI╝╝ąg║═æ¬ė├ŅIė“Ą╚Č╝▀Mąą┴╦įö▒MĄ─Ęų╬÷ĪŻ▀M╚ļ2012 ─ĻęįüĒŻ¼┤¾öĄ(sh©┤)ō■Ą─ĻPūóČ╚┼c╚šŠŃį÷ĪŻ1 į┬Ę▌Ą─▀_╬ų╦╣╩└ĮńĮøØ·šōē»╔ŽŻ¼┤¾öĄ(sh©┤)ō■╩Ūų„Ņ}ų«ę╗Ż¼įō┤╬Ģ■ūh▀Ć╠žäeßśī”┤¾öĄ(sh©┤)ō■░l(f©Ī)▓╝┴╦ł¾ĖµĪČBig Data, Big Impact: New Possibilities for International DevelopmentĪĘŻ¼╠Įėæ┴╦ą┬Ą─öĄ(sh©┤)ō■«a╔·ĘĮ╩ĮŽ┬Ż¼╚ń║╬Ė³║├Ą─└¹ė├öĄ(sh©┤)ō■üĒ«a╔·┴╝║├Ą─╔ńĢ■ą¦ęµĪŻįōł¾Ėµųž³cĻPūó┴╦éĆ╚╦«a╔·Ą─ęŲäėöĄ(sh©┤)ō■┼cŲõ╦¹öĄ(sh©┤)ō■Ą─╚┌║Ž┼c└¹ė├ĪŻ3 į┬Ę▌├└ć°ŖW░═±Rš■Ė«░l(f©Ī)▓╝┴╦ĪČ┤¾öĄ(sh©┤)ō■蹊┐║═░l(f©Ī)š╣│½ūhĪĘ[7](Big Data Research and Development Initiative)Ż¼═Č┘Y2 ā|ęį╔Ž├└į¬Ż¼š²╩Įåóäė“┤¾öĄ(sh©┤)ō■░l(f©Ī)š╣ėŗäØ”ĪŻėŗäØį┌┐ŲīW蹊┐ĪóŁh(hu©ón)Š│Īó╔·╬’ßt(y©®)īWĄ╚ŅIė“└¹ė├┤¾öĄ(sh©┤)ō■╝╝ąg▀Mąą═╗ŲŲĪŻŖW░═±Rš■Ė«Ą─▀@ę╗ėŗäØ▒╗ęĢ×ķ├└ć°š■Ė«└^ą┼ŽóĖ▀╦┘╣½┬Ę(Information Highway)ėŗäØų«║¾į┌ą┼Žó┐ŲīWŅIė“Ą─ėųę╗ųž┤¾┼e┤ļĪŻ┼c┤╦═¼ĢrŻ¼┬ō(li©ón)║Žć°ę╗éĆ├¹×ķGlobal Pulse Ą─│½ūhĒŚ─┐į┌Į±─Ļ5 į┬░l(f©Ī)▓╝ł¾ĖµĪČBig Data for DevelopmentŻ║Challenges & OpportunitiesĪĘŻ¼įōł¾Ėµų„ę¬ĻU╩÷┤¾öĄ(sh©┤)ō■Ģr┤·Ė„ć°╠žäe╩Ū░l(f©Ī)š╣ųąć°╝ęį┌├µ┼RöĄ(sh©┤)ō■║ķ┴„(Data Deluge)Ą─ŪķørŽ┬╦∙ė÷ĄĮĄ─ÖCė÷┼c╠¶æ(zh©żn)Ż¼═¼Ģr▀Ćī”┤¾öĄ(sh©┤)ō■Ą─æ¬ė├▀Mąą┴╦│§▓ĮĄ─ĮŌūxĪŻĪČ╝~╝sĢrł¾ĪĘĄ─╬─š┬ĪČThe Age of Big DataĪĘät═©▀^ų„┴„├Į¾wĄ─ą¹é„╩╣Ųš═©├±▒Ŗķ_╩╝ęŌūRĄĮ┤¾öĄ(sh©┤)ō■Ą─┤µį┌Ż¼ęį╝░┤¾öĄ(sh©┤)ō■ī”ė┌╚╦éā╚š│Ż╔·╗ŅĄ─ė░ĒæĪŻ
┤¾öĄ(sh©┤)ō■Ą─╗¤ß▓ó▓╗ęŌ╬Čų°ī”ė┌┤¾öĄ(sh©┤)ō■Ą─┴╦ĮŌ╔Ņ╚ļŻ¼Ę┤Č°▒Ē├„┤¾öĄ(sh©┤)ō■┤µį┌▀^Č╚│┤ū„Ą─╬ŻļUĪŻ┤¾öĄ(sh©┤)ō■Ą─╗∙▒ŠĖ┼─ŅĪóĻPµI╝╝ągęį╝░ī”ŲõĄ─└¹ė├╔ŽŠ∙┤µį┌║▄ČÓĄ─ę╔å¢║═ĀÄūhĪŻ▒Š╬─Å─┤¾öĄ(sh©┤)ō■å¢Ņ}▒│║¾Ą─▒Š┘|│÷░l(f©Ī)Ż¼ī”¼F(xi©żn)ėąĄ─┤¾öĄ(sh©┤)ō■蹊┐┘Y┴Ž▀Mąą╚½├µĄ─Üw╝{║═┐éĮYĪŻ╩ūŽ╚║åę¬ĮķĮB┤¾öĄ(sh©┤)ō■Ą─╗∙▒ŠĖ┼─ŅŻ¼ĻU╩÷Ųõ═¼é„Įy(t©»ng)öĄ(sh©┤)ō■ÄņĄ─ģ^(q©▒)äeĪŻį┌┤╦╗∙ĄA╔ŽŻ¼ī”┤¾öĄ(sh©┤)ō■╠Ä└Ē┐“╝▄▀Mąąįö╝ÜĮŌ╬÷ĪŻ╬ęéāšJ×ķ┤¾öĄ(sh©┤)ō■Ą─░l(f©Ī)š╣ļx▓╗ķ_įŲėŗ╦Ń╝╝ągŻ¼įŲėŗ╦Ńų¦ō╬ų°┤¾öĄ(sh©┤)ō■┤µā”Īó╣▄└Ēęį╝░öĄ(sh©┤)ō■Ęų╬÷Ą╚ĪŻę“┤╦▒Š╬─š╣ķ_ĮķĮB┴╦┤¾öĄ(sh©┤)ō■Ģr┤·▓╗┐╔╗“╚▒Ą─įŲėŗ╦Ń╝╝ąg║═╣żŠ▀ĪŻūŅ║¾╚½├µĻU╩÷┤¾öĄ(sh©┤)ō■Ģr┤·├µ┼RĄ─ą┬╠¶æ(zh©żn)ĪŻ
2Īó┤¾öĄ(sh©┤)ō■Ą─╗∙▒ŠĖ┼─ŅĪóüĒį┤┼cæ¬ė├
2.1 ┤¾öĄ(sh©┤)ō■Ą─╗∙▒ŠĖ┼─Ņ
┤¾öĄ(sh©┤)ō■▒Š╔Ē╩Ūę╗éĆ▒╚▌^│ķŽ¾Ą─Ė┼─ŅŻ¼å╬Å─ūų├µüĒ┐┤Ż¼╦³▒Ē╩ŠöĄ(sh©┤)ō■ęÄ(gu©®)─ŻĄ─²ŗ┤¾ĪŻĄ½╩ŪāHāHöĄ(sh©┤)┴┐╔ŽĄ─²ŗ┤¾’@╚╗¤oĘ©┐┤│÷┤¾öĄ(sh©┤)ō■▀@ę╗Ė┼─Ņ║═ęį═∙Ą─“║Ż┴┐öĄ(sh©┤)ō■”Ż©Massive DataŻ®Īó“│¼┤¾ęÄ(gu©®)─ŻöĄ(sh©┤)ō■”(Very Large Data)Ą╚Ė┼─Ņų«ķgėą║╬ģ^(q©▒)äeĪŻī”ė┌┤¾öĄ(sh©┤)ō■╔ą╬┤ėąę╗éĆ╣½šJĄ─Č©┴xŻ¼▓╗═¼Ą─Č©┴x╗∙▒Š╩ŪÅ─┤¾öĄ(sh©┤)ō■Ą─╠žš„│÷░l(f©Ī)Ż¼═©▀^▀@ą®╠žš„Ą─ĻU╩÷║═Üw╝{Ż¼įćłDĮo│÷ŲõČ©┴xĪŻį┌▀@ą®Č©┴xųąŻ¼▒╚▌^ėą┤·▒ĒąįĄ─╩Ū3V Č©┴xŻ¼╝┤šJ×ķ┤¾öĄ(sh©┤)ō■ąĶØMūŃ3 éĆ╠ž³cŻ║ęÄ(gu©®)─Żąį(Volume)ĪóČÓśėąį(Variety)║═Ė▀╦┘ąį(Velocity)ĪŻ│²┤╦ų«═ŌŻ¼▀Ćėą╠ß│÷4V Č©┴xĄ─Ż¼╝┤ćLįćį┌3V Ą─╗∙ĄA╔Žį÷╝ėę╗éĆą┬Ą─╠žąįĪŻĻPė┌Ą┌╦─éĆV Ą─šfĘ©▓ó▓╗Įy(t©»ng)ę╗Ż¼IDC šJ×ķ┤¾öĄ(sh©┤)ō■▀Ć欫öŠ▀ėąārųĄąį(Value)Ż¼┤¾öĄ(sh©┤)ō■Ą─ārųĄ═∙═∙│╩¼F(xi©żn)│÷ŽĪ╩ĶąįĄ─╠ž³cĪŻČ°IBM šJ×ķ┤¾öĄ(sh©┤)ō■▒ž╚╗Š▀ėąšµīŹąį(Veracity)ĪŻŠS╗∙░┘┐Ųī”┤¾öĄ(sh©┤)ō■Ą─Č©┴xät║åå╬├„┴╦Ż║┤¾öĄ(sh©┤)ō■╩ŪųĖ└¹ė├│Żė├▄ø╝■╣żŠ▀▓Č½@Īó╣▄└Ē║═╠Ä└ĒöĄ(sh©┤)ō■╦∙║─Ģrķg│¼▀^┐╔╚▌╚╠ĢrķgĄ─öĄ(sh©┤)ō■╝»ĪŻ
č█Ž┬į┌┤¾öĄ(sh©┤)ō■Č©┴xå¢Ņ}╔Ž║▄ļy▀_│╔ę╗éĆ═Ļ╚½Ą─╣▓ūRŻ¼▀@³c║═įŲėŗ╦ŃĄ─Ė┼─Ņäé╠ß│÷ĢrĄ─Ūķør╩ŪŽÓ╦ŲĄ─ĪŻį┌├µī”īŹļHå¢Ņ}ĢrŻ¼▓╗▒ž▀^Č╚Ą─Šą─Óė┌Š▀¾wĄ─Č©┴xų«ųąŻ¼░č╬š3V Č©┴xĄ─╗∙ĄA╔ŽŻ¼▀m«ö?sh©┤)─┐╝æ]4V ╠žąį╝┤┐╔ĪŻ
2.2 Å─öĄ(sh©┤)ō■Äņ(Database, DB)ĄĮ┤¾öĄ(sh©┤)ō■(Big Data, BD)
Å─öĄ(sh©┤)ō■Äņ(DB)ĄĮ┤¾öĄ(sh©┤)ō■(BD)Ż¼┐┤╦Ųų╗╩Ūę╗éĆ║åå╬Ą─╝╝ągč▌▀MŻ¼Ą½╝Ü╝Ü┐╝Š┐▓╗ļy░l(f©Ī)¼F(xi©żn)ā╔š▀ėąų°▒Š┘|╔ŽĄ─▓ŅäeĪŻ┤¾öĄ(sh©┤)ō■Ą─│÷¼F(xi©żn)Ż¼▒žīóŅŹĖ▓é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■╣▄└ĒĘĮ╩ĮĪŻį┌öĄ(sh©┤)ō■üĒį┤ĪóöĄ(sh©┤)ō■╠Ä└ĒĘĮ╩Į║═öĄ(sh©┤)ō■╦╝ŠSĄ╚ĘĮ├µČ╝Ģ■ī”ŲõĦüĒĖ’├³ąįĄ─ūā╗»ĪŻ
╚ń╣¹ę¬ė├║åå╬Ą─ĘĮ╩ĮüĒ▒╚▌^é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■Äņ║═┤¾öĄ(sh©┤)ō■Ą─ģ^(q©▒)äeĄ─įÆŻ¼╬ęéāšJ×ķ“│ž╠┴▓ȶ~”║═“┤¾║Ż▓ȶ~”╩ŪéĆ║▄║├Ą─ŅÉ▒╚ĪŻ“│ž╠┴▓ȶ~”┤·▒Ēų°é„Įy(t©»ng)öĄ(sh©┤)ō■ÄņĢr┤·Ą─öĄ(sh©┤)ō■╣▄└ĒĘĮ╩ĮŻ¼Č°“┤¾║Ż▓ȶ~”ätī”æ¬ų°┤¾öĄ(sh©┤)ō■Ģr┤·Ą─öĄ(sh©┤)ō■╣▄└ĒĘĮ╩ĮŻ¼“¶~”╩Ū┤²╠Ä└ĒĄ─öĄ(sh©┤)ō■ĪŻ“▓ȶ~”Łh(hu©ón)Š│Śl╝■Ą─ūā╗»ī¦ų┬┴╦“▓ȶ~”ĘĮ╩ĮĄ─Ė∙▒Šąį▓Ņ«ÉĪŻ▀@ą®▓Ņ«Éų„ę¬¾w¼F(xi©żn)į┌╚ńŽ┬ÄūéĆĘĮ├µŻ║
1ĪóöĄ(sh©┤)ō■ęÄ(gu©®)─ŻŻ║“│ž╠┴”║═“┤¾║Ż”ūŅ╚▌ęū░l(f©Ī)¼F(xi©żn)Ą─ģ^(q©▒)äeŠ═╩ŪęÄ(gu©®)─ŻĪŻ“│ž╠┴”ęÄ(gu©®)─ŻŽÓī”▌^ąĪŻ¼╝┤▒Ń╩ŪŽ╚Ū░šJ×ķ▒╚▌^┤¾Ą─“│ž╠┴”Ż¼Ų®╚ńVLDB(Very Large Database)Ż¼║═“┤¾║Ż”XLDB(Extremely Large Database)ŽÓ▒╚╚į┼fŲ½ąĪĪŻ“│ž╠┴”Ą─╠Ä└Ēī”Ž¾═©│ŻęįMB ×ķ╗∙▒Šå╬╬╗Ż¼Č°“┤¾║Ż”ät│Ż│ŻęįGBŻ¼╔§ų┴╩ŪTBĪóPB ×ķ╗∙▒Š╠Ä└Ēå╬╬╗ĪŻ
2ĪóöĄ(sh©┤)ō■ŅÉą═Ż║▀^╚źĄ─“│ž╠┴”ųąŻ¼öĄ(sh©┤)ō■Ą─ĘNŅÉå╬ę╗Ż¼═∙═∙āHāHėąę╗ĘN╗“╔┘öĄ(sh©┤)ÄūĘNŻ¼▀@ą®öĄ(sh©┤)ō■ėųęįĮYśŗ╗»öĄ(sh©┤)ō■×ķų„ĪŻČ°į┌“┤¾║Ż”ųąŻ¼öĄ(sh©┤)ō■Ą─ĘNŅÉĘ▒ČÓŻ¼öĄ(sh©┤)ęįŪ¦ėŗŻ¼Č°▀@ą®öĄ(sh©┤)ō■ėų░³║¼ų°ĮYśŗ╗»Īó░ļĮYśŗ╗»ęį╝░ĘŪĮYśŗ╗»Ą─öĄ(sh©┤)ō■Ż¼▓óŪę░ļĮYśŗ╗»║═ĘŪĮYśŗ╗»öĄ(sh©┤)ō■╦∙š╝Ę▌Ņ~įĮüĒįĮ┤¾ĪŻ
3Īó─Ż╩Į(Schema)║═öĄ(sh©┤)ō■Ą─ĻPŽĄŻ║é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■ÄņČ╝╩ŪŽ╚ėą─Ż╩ĮŻ¼╚╗║¾▓┼Ģ■«a╔·öĄ(sh©┤)ō■ĪŻ▀@Š═║├▒╚╩ŪŽ╚▀x║├║Ž▀mĄ─“│ž╠┴”Ż¼╚╗║¾▓┼Ģ■Ž“Ųõųą═ČĘ┼▀m║Žį┌įō“│ž╠┴”Łh(hu©ón)Š│╔·ķLĄ─“¶~”ĪŻČ°┤¾öĄ(sh©┤)ō■Ģr┤·║▄ČÓŪķørŽ┬ļyęįŅAŽ╚┤_Č©─Ż╩ĮŻ¼─Ż╩Įų╗ėąį┌öĄ(sh©┤)ō■│÷¼F(xi©żn)ų«║¾▓┼─▄┤_Č©Ż¼Ūę─Ż╩ĮļSų°öĄ(sh©┤)ō■┴┐Ą─į÷ķL╠Äė┌▓╗öÓĄ─č▌ūāų«ųąĪŻ▀@Š═║├▒╚Ž╚ėą╔┘┴┐Ą─¶~ŅÉŻ¼ļSų°Ģrķg═ŲęŲŻ¼¶~Ą─ĘNŅÉ║═öĄ(sh©┤)┴┐Č╝į┌▓╗öÓĄ─į÷ķLĪŻ¶~Ą─ūā╗»Ģ■╩╣┤¾║ŻĄ─│╔Ęų║═Łh(hu©ón)Š│╠Äė┌▓╗öÓĄ─ūā╗»ų«ųąĪŻ
4Īó╠Ä└Ēī”Ž¾Ż║į┌“│ž╠┴”ųą▓ȶ~Ż¼“¶~”āHāH╩ŪŲõ▓ČōŲī”Ž¾ĪŻČ°į┌“┤¾║Ż”ųąŻ¼“¶~”│²┴╦╩Ū▓ČōŲī”Ž¾ų«═ŌŻ¼▀Ć┐╔ęį═©▀^─│ą®“¶~”Ą─┤µį┌üĒ┼ąöÓŲõ╦¹ĘNŅÉĄ─“¶~”╩Ūʱ┤µį┌ĪŻę▓Š═╩Ūšfé„Įy(t©»ng)öĄ(sh©┤)ō■ÄņųąöĄ(sh©┤)ō■āHū„×ķ╠Ä└Ēī”Ž¾ĪŻČ°į┌┤¾öĄ(sh©┤)ō■Ģr┤·Ż¼ę¬īóöĄ(sh©┤)ō■ū„×ķę╗ĘN┘Yį┤üĒ▌oų·ĮŌøQŲõ╦¹ųTČÓŅIė“Ą─å¢Ņ}ĪŻ
5Īó╠Ä└Ē╣żŠ▀Ż║▓ČōŲ“│ž╠┴”ųąĄ─“¶~”Ż¼ę╗ĘNØOŠW╗“╔┘öĄ(sh©┤)ÄūĘN╗∙▒ŠŠ═┐╔ęįæ¬ī”Ż¼ę▓Š═╩Ū╦∙ų^Ą─One Size Fits AllĪŻĄ½╩Ūį┌“┤¾║Ż”ųąŻ¼▓╗┐╔─▄┤µį┌ę╗ĘNØOŠW─▄ē“▓Č½@╦∙ėąĄ─¶~ŅÉŻ¼ę▓Š═╩ŪšfNo Size Fits AllĪŻ
Å─“│ž╠┴”ĄĮ“┤¾║Ż”Ż¼▓╗āHāH╩ŪęÄ(gu©®)─ŻĄ─ūā┤¾ĪŻé„Įy(t©»ng)Ą─öĄ(sh©┤)ō■Äņ┤·▒Ēų°öĄ(sh©┤)ō■╣ż│╠(Data Engineering)Ą─╠Ä└ĒĘĮ╩ĮŻ¼┤¾öĄ(sh©┤)ō■Ģr┤·Ą─öĄ(sh©┤)ō■ęč▓╗āHāHų╗╩Ū╣ż│╠╠Ä└ĒĄ─ī”Ž¾Ż¼ąĶę¬▓╔╚Īą┬Ą─öĄ(sh©┤)ō■╦╝ŠSüĒæ¬ī”ĪŻłDņ`¬ä½@Ą├š▀Īóų°├¹öĄ(sh©┤)ō■ÄņīŻ╝ęJim Gray ▓®╩┐ė^▓ņ▓ó┐éĮY╚╦ŅÉūį╣┼ęįüĒŻ¼į┌┐ŲīW蹊┐╔ŽŻ¼Ž╚║¾ÜvĮø┴╦īŹ“×Īó└Ēšō║═ėŗ╦Ń╚²ĘNĘČ╩ĮĪŻ«ööĄ(sh©┤)ō■┴┐▓╗öÓį÷ķL║═└█ĘeĄĮĮ±╠ņŻ¼é„Įy(t©»ng)Ą─╚²ĘNĘČ╩Įį┌┐ŲīW蹊┐Ż¼╠žäe╩Ūę╗ą®ą┬Ą─蹊┐ŅIė“ęčĮø¤oĘ©║▄║├Ą─░l(f©Ī)ō]ū„ė├Ż¼ąĶę¬ėąę╗ĘN╚½ą┬Ą─Ą┌╦─ĘNĘČ╩ĮüĒųĖī¦ą┬ą╬ä▌Ž┬Ą─┐ŲīW蹊┐ĪŻ╗∙ė┌▀@ĘN┐╝æ]Ż¼Jim Gray ╠ß│÷┴╦ę╗ĘNą┬Ą─öĄ(sh©┤)ō■╠Į╦„ą═蹊┐ĘĮ╩ĮŻ¼▒╗╦¹ūį╝║ĘQų«×ķ┐ŲīW蹊┐Ą─“Ą┌╦─ĘNĘČ╩Į”(The Fourth Paradigm)ĪŻ

▒Ē1 ┐ŲīW░l(f©Ī)¼F(xi©żn)Ą─╦─ĘNĘČ╩Į
╦─ĘNĘČ╩ĮĄ─▒╚▌^╚ń▒Ē1╦∙╩ŠĪŻĄ┌╦─ĘNĘČ╩ĮĄ─īŹ┘|Š═╩ŪÅ─ęįėŗ╦Ń×ķųąą─Ż¼▐DūāĄĮęįöĄ(sh©┤)ō■╠Ä└Ē×ķųąą─Ż¼ę▓Š═╩Ū╬ęéā╦∙šfĄ─öĄ(sh©┤)ō■╦╝ŠSĪŻ▀@ĘNĘĮ╩ĮąĶę¬╬ęéāÅ─Ė∙▒Š╔Ž▐Dūā╦╝ŠSĪŻš²╚ńŪ░├µ╠ߥĮĄ─“▓ȶ~”Ż¼į┌┤¾öĄ(sh©┤)ō■Ģr┤·Ż¼öĄ(sh©┤)ō■▓╗į┘āHāH╩Ū“▓ČōŲ”Ą─ī”Ž¾Ż¼Č°æ¬«ö▐Dūā│╔ę╗ĘN╗∙ĄA┘Yį┤Ż¼ė├öĄ(sh©┤)ō■▀@ĘN┘Yį┤üĒģf(xi©”)═¼ĮŌøQŲõ╦¹ųTČÓŅIė“Ą─å¢Ņ}ĪŻėŗ╦Ń╔ńĢ■┐ŲīW(Computational SocialScience)╗∙ė┌╠žČ©╔ńĢ■ąĶŪ¾Ż¼į┌╠žČ©Ą─╔ńĢ■└ĒšōųĖī¦Ž┬Ż¼╩š╝»Īóš¹└Ē║═Ęų╬÷öĄ(sh©┤)ō■ūŃ█E(dataprint)Ż¼ęį▒Ń▀Mąą╔ńĢ■ĮŌßīĪó▒O(ji©Īn)┐žĪóŅA£y┼cęÄ(gu©®)äØĄ─▀^│╠║═╗ŅäėĪŻėŗ╦Ń╔ńĢ■┐ŲīW╩Ūę╗ĘNĄõą═Ą─ąĶę¬▓╔ė├Ą┌╦─ĘNĘČ╩ĮüĒū÷ųĖī¦Ą─┐ŲīW蹊┐ŅIė“ĪŻDuncan J. Watts į┌ĪČūį╚╗ĪĘļsųŠ╔ŽĄ─╬─š┬ĪČAtwenty-first century scienceĪĘę▓ųĖ│÷ĮĶų·ė┌╔ńĮ╗ŠWĮj║═ėŗ╦ŃÖCĘų╬÷╝╝ągŻ¼21 ╩└╝oĄ─╔ńĢ■┐ŲīWėą┐╔─▄īŹ¼F(xi©żn)Č©┴┐╗»Ą─蹊┐Ż¼Å─Č°│╔×ķę╗ķTšµš²Ą─ūį╚╗┐ŲīWĪŻ
2.3 ┤¾öĄ(sh©┤)ō■Ą─«a╔·║═æ¬ė├
╚╦ŅÉÜv╩Ę╔ŽÅ─╬┤ėą──éĆĢr┤·║═Į±╠ņę╗śė«a╔·╚ń┤╦║Ż┴┐Ą─öĄ(sh©┤)ō■ĪŻöĄ(sh©┤)ō■Ą─«a╔·ęčĮø═Ļ╚½▓╗╩▄ĢrķgĪóĄž³cĄ─Ž▐ųŲĪŻÅ─ķ_╩╝▓╔ė├öĄ(sh©┤)ō■Äņū„×ķöĄ(sh©┤)ō■╣▄└ĒĄ─ų„ę¬ĘĮ╩Įķ_╩╝Ż¼╚╦ŅÉ╔ńĢ■Ą─öĄ(sh©┤)ō■«a╔·ĘĮ╩Į┤¾ų┬ĮøÜv┴╦3 éĆļAČ╬Ż¼Č°š²╩ŪöĄ(sh©┤)ō■«a╔·ĘĮ╩ĮĄ─Š▐┤¾ūā╗»▓┼ūŅĮKī¦ų┬┤¾öĄ(sh©┤)ō■Ą─«a╔·ĪŻ
1Īó▀\ĀI╩ĮŽĄĮy(t©»ng)ļAČ╬ĪŻöĄ(sh©┤)ō■ÄņĄ─│÷¼F(xi©żn)╩╣Ą├öĄ(sh©┤)ō■╣▄└ĒĄ─Å═ļsČ╚┤¾┤¾ĮĄĄ═Ż¼īŹļHųąöĄ(sh©┤)ō■Äņ┤¾Č╝×ķ▀\ĀIŽĄĮy(t©»ng)╦∙▓╔ė├Ż¼ū„×ķ▀\ĀIŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■╣▄└ĒūėŽĄĮy(t©»ng)ĪŻ▒╚╚ń│¼╩ąĄ─õN╩█ėøõøŽĄĮy(t©»ng)Ż¼ŃyąąĄ─Į╗ęūėøõøŽĄĮy(t©»ng)Īóßt(y©®)į║▓Ī╚╦Ą─ßt(y©®)»¤ėøõøĄ╚ĪŻ╚╦ŅÉ╔ńĢ■öĄ(sh©┤)ō■┴┐Ą┌ę╗┤╬┤¾Ą─’w▄Sš²╩ŪĮ©┴óį┌▀\ĀI╩ĮŽĄĮy(t©»ng)ķ_╩╝ÅVĘ║╩╣ė├öĄ(sh©┤)ō■Äņķ_╩╝ĪŻ▀@éĆļAČ╬ūŅų„ę¬╠ž³c╩ŪöĄ(sh©┤)ō■═∙═∙░ķļSų°ę╗Č©Ą─▀\ĀI╗ŅäėČ°«a╔·▓óėøõøį┌öĄ(sh©┤)ō■ÄņųąĄ─Ż¼▒╚╚ń│¼╩ą├┐õN╩█│÷ę╗╝■«aŲĘŠ═Ģ■į┌öĄ(sh©┤)ō■Äņųą«a╔·ŽÓæ¬Ą─ę╗ŚlõN╩█ėøõøĪŻ▀@ĘNöĄ(sh©┤)ō■Ą─«a╔·ĘĮ╩Į╩Ū▒╗äėĄ─ĪŻ
2Īóė├æ¶įŁäō(chu©żng)ā╚╚▌ļAČ╬ĪŻ╗ź┬ō(li©ón)ŠWĄ─šQ╔·┤┘╩╣╚╦ŅÉ╔ńĢ■öĄ(sh©┤)ō■┴┐│÷¼F(xi©żn)Ą┌Č■┤╬┤¾Ą─’w▄SĪŻĄ½╩Ūšµš²Ą─öĄ(sh©┤)ō■▒¼░l(f©Ī)«a╔·ė┌Web 2.0 Ģr┤·Ż¼Č°Web 2.0 Ą─ūŅųžę¬ś╦ųŠŠ═╩Ūė├æ¶įŁäō(chu©żng)ā╚╚▌Ż©UGC,User Generated ContentŻ®ĪŻ▀@ŅÉöĄ(sh©┤)ō■Į³Äū─Ļę╗ų▒│╩¼F(xi©żn)▒¼š©ąįĄ─į÷ķLŻ¼ų„ę¬ėąā╔éĆĘĮ├µĄ─įŁę“ĪŻ╩ūŽ╚╩Ūęį▓®┐═Īó╬ó▓®×ķ┤·▒ĒĄ─ą┬ą═╔ńĮ╗ŠWĮjĄ─│÷¼F(xi©żn)║═┐ņ╦┘░l(f©Ī)š╣Ż¼╩╣Ą├ė├涫a╔·öĄ(sh©┤)ō■Ą─ęŌįĖĖ³╝ėÅŖ┴ęĪŻŲõ┤╬Š═╩ŪęįųŪ─▄╩ųÖCĪóŲĮ░ÕļŖ─X×ķ┤·▒ĒĄ─ą┬ą═ęŲäėįOéõĄ─│÷¼F(xi©żn)Ż¼▀@ą®ęūöyĦĪó╚½╠ņ║“Įė╚ļŠWĮjĄ─ęŲäėįOéõ╩╣Ą├╚╦éāį┌ŠW╔Ž░l(f©Ī)▒Ēūį╝║ęŌęŖĄ─═ŠÅĮĖ³×ķ▒ŃĮ▌ĪŻ▀@éĆļAČ╬öĄ(sh©┤)ō■Ą─«a╔·ĘĮ╩Į╩Ūų„äėĄ─ĪŻ
3ĪóĖąų¬╩ĮŽĄĮy(t©»ng)ļAČ╬ĪŻ╚╦ŅÉ╔ńĢ■öĄ(sh©┤)ō■┴┐Ą┌╚²┤╬┤¾Ą─’w▄SūŅĮKī¦ų┬┴╦┤¾öĄ(sh©┤)ō■Ą─«a╔·Ż¼Į±╠ņ╬ęéāš²╠Äė┌▀@éĆļAČ╬ĪŻ▀@┤╬’w▄SĄ─Ė∙▒ŠįŁę“į┌ė┌Ėąų¬╩ĮŽĄĮy(t©»ng)Ą─ÅVĘ║╩╣ė├ĪŻļSų°╝╝ągĄ─░l(f©Ī)š╣Ż¼╚╦éāęčĮøėą─▄┴”ųŲįņśOŲõ╬óąĪĄ─Ħėą╠Ä└Ē╣”─▄Ą─é„ĖąŲ„Ż¼▓óķ_╩╝īó▀@ą®įOéõÅVĘ║Ą─▓╝ų├ė┌╔ńĢ■Ą─Ė„éĆĮŪ┬õŻ¼═©▀^▀@ą®įOéõüĒī”š¹éĆ╔ńĢ■Ą─▀\▐D▀Mąą▒O(ji©Īn)┐žĪŻ▀@ą®įOéõĢ■į┤į┤▓╗öÓĄ─«a╔·ą┬öĄ(sh©┤)ō■Ż¼▀@ĘNöĄ(sh©┤)ō■Ą─«a╔·ĘĮ╩Į╩ŪūįäėĄ─ĪŻ
║åå╬üĒšfŻ¼öĄ(sh©┤)ō■«a╔·ĮøÜv┴╦▒╗äėĪóų„äė║═ūįäė╚²éĆļAČ╬ĪŻ▀@ą®▒╗äėĪóų„äė║═ūįäėĄ─öĄ(sh©┤)ō■╣▓═¼śŗ│╔┴╦┤¾öĄ(sh©┤)ō■Ą─öĄ(sh©┤)ō■üĒį┤Ż¼Ą½Ųõųąūįäė╩ĮĄ─öĄ(sh©┤)ō■▓┼╩Ū┤¾öĄ(sh©┤)ō■«a╔·Ą─ūŅĖ∙▒ŠįŁę“ĪŻ
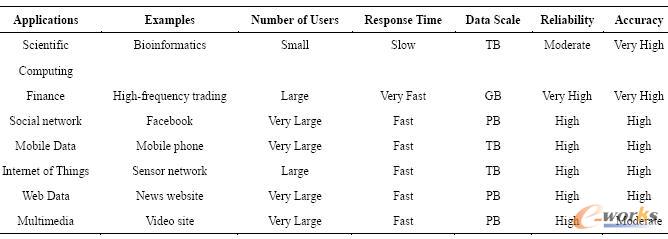
▒Ē2 Ąõą═┤¾öĄ(sh©┤)ō■æ¬ė├Ą─▒╚▌^
š²╚ńGoogle Ą─╩ūŽ»ĮøØ·īW╝ęHal Varian ╦∙šfŻ¼öĄ(sh©┤)ō■╩ŪÅVĘ║┐╔ė├Ą─Ż¼╦∙╚▒Ę”Ą─╩ŪÅ─ųą╠ß╚Ī│÷ų¬ūRĄ──▄┴”ĪŻöĄ(sh©┤)ō■╩š╝»Ą─Ė∙▒Š─┐Ą─╩ŪĖ∙ō■ąĶŪ¾Å─öĄ(sh©┤)ō■ųą╠ß╚Īėąė├Ą─ų¬ūRŻ¼▓óīóŲõæ¬ė├ĄĮŠ▀¾wĄ─ŅIė“ų«ųąĪŻ▓╗═¼ŅIė“Ą─┤¾öĄ(sh©┤)ō■æ¬ė├ėą▓╗═¼Ą─╠ž³cŻ¼▒Ē2 ┴ą┼e┴╦╚¶Ė╔Š▀ėą┤·▒ĒąįĄ─┤¾öĄ(sh©┤)ō■æ¬ė├╝░Ųõ╠žš„ĪŻ
š²╩Ūė╔ė┌┤¾öĄ(sh©┤)ō■Ą─ÅVĘ║┤µį┌Ż¼▓┼╩╣Ą├┤¾öĄ(sh©┤)ō■å¢Ņ}Ą─ĮŌøQ║▄Š▀╠¶æ(zh©żn)ąįĪŻČ°╦³Ą─ÅVĘ║æ¬ė├Ż¼ät┤┘╩╣įĮüĒįĮČÓĄ─╚╦ķ_╩╝ĻPūó║═蹊┐┤¾öĄ(sh©┤)ō■å¢Ņ}ĪŻ
3Īó┤¾öĄ(sh©┤)ō■╠Ä└Ē┐“╝▄
3.1 ┤¾öĄ(sh©┤)ō■╠Ä└Ē─Ż╩Į
┤¾öĄ(sh©┤)ō■Ą─æ¬ė├ŅÉą═║▄ČÓŻ¼ų„ꬥ─╠Ä└Ē─Ż╩Į┐╔ęįĘų×ķ┴„╠Ä└Ē(Stream Processing)║═┼·╠Ä└Ē(Batch Processing)ā╔ĘNĪŻ┼·╠Ä└Ē╩ŪŽ╚┤µā”║¾╠Ä└Ē(Store-then-process)Ż¼Č°┴„╠Ä└Ēät╩Ūų▒Įė╠Ä└Ē(Straight-through processing)ĪŻ
3.1.1 ┴„╠Ä└Ē
┴„╠Ä└ĒĄ─╗∙▒Š└Ē─Ņ╩ŪöĄ(sh©┤)ō■Ą─ārųĄĢ■ļSų°ĢrķgĄ─┴„╩┼Č°▓╗öÓ£p╔┘ĪŻę“┤╦▒M┐╔─▄┐ņĄ─ī”ūŅą┬Ą─öĄ(sh©┤)ō■ū÷│÷Ęų╬÷▓óĮo│÷ĮY╣¹╩Ū╦∙ėą┴„öĄ(sh©┤)ō■╠Ä└Ē─Ż╩ĮĄ─╣▓═¼─┐ś╦ĪŻąĶę¬▓╔ė├┴„öĄ(sh©┤)ō■╠Ä└ĒĄ─┤¾öĄ(sh©┤)ō■æ¬ė├ł÷Š░ų„ę¬ėąŠWĒō³cō¶öĄ(sh©┤)Ą─īŹĢrĮy(t©»ng)ėŗĪóé„ĖąŲ„ŠWĮjĪóĮ╚┌ųąĄ─Ė▀ŅlĮ╗ęūĄ╚ĪŻ
┴„╠Ä└ĒĄ─╠Ä└Ē─Ż╩ĮīóöĄ(sh©┤)ō■ęĢ×ķ┴„Ż¼į┤į┤▓╗öÓĄ─öĄ(sh©┤)ō■ĮM│╔┴╦öĄ(sh©┤)ō■┴„ĪŻ«öą┬Ą─öĄ(sh©┤)ō■ĄĮüĒĢrŠ═┴ó┐╠╠Ä└Ē▓óĘĄ╗ž╦∙ąĶĄ─ĮY╣¹ĪŻłD1╩Ū┴„╠Ä└Ēųą╗∙▒ŠĄ─öĄ(sh©┤)ō■┴„─Żą═Ż║
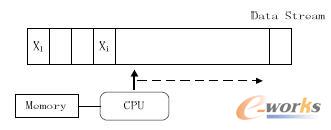
łD1 ╗∙▒ŠĄ─öĄ(sh©┤)ō■┴„─Żą═
öĄ(sh©┤)ō■Ą─īŹĢr╠Ä└Ē╩Ūę╗éĆ║▄ėą╠¶æ(zh©żn)ąįĄ─╣żū„Ż¼öĄ(sh©┤)ō■┴„▒Š╔ĒŠ▀ėą│ų└m(x©┤)▀_ĄĮĪó╦┘Č╚┐ņŪęęÄ(gu©®)─ŻŠ▐┤¾Ą╚╠ž³cŻ¼ę“┤╦═©│Ż▓╗Ģ■ī”╦∙ėąĄ─öĄ(sh©┤)ō■▀Mąąė└Š├╗»┤µā”Ż¼Č°ŪęöĄ(sh©┤)ō■Łh(hu©ón)Š│╠Äį┌▓╗öÓĄ─ūā╗»ų«ųąŻ¼ŽĄĮy(t©»ng)║▄ļy£╩┤_šŲ╬šš¹éĆöĄ(sh©┤)ō■Ą─╚½├▓ĪŻė╔ė┌Ēææ¬ĢrķgĄ─ę¬Ū¾Ż¼┴„╠Ä└ĒĄ─▀^│╠╗∙▒Šį┌ā╚┤µųą═Ļ│╔Ż¼Ųõ╠Ä└ĒĘĮ╩ĮĖ³ČÓĄ─ę└┘ćė┌į┌ā╚┤µųąįOėŗŪ╔├ŅĄ─Ė┼ę¬öĄ(sh©┤)ō■ĮYśŗ(Synopsis data structure)Ż¼ā╚┤µ╚▌┴┐╩ŪŽ▐ųŲ┴„╠Ä└Ē─Żą═Ą─ę╗éĆų„ę¬Ų┐ŅiĪŻęįPCM(ŽÓūā┤µā”Ų„)×ķ┤·▒ĒĄ─SCM(Storage ClassMemoryŻ¼ā”┤µ╝ēā╚┤µ)įOéõĄ─│÷¼F(xi©żn)╗“įS┐╔ęį╩╣ā╚┤µ╬┤üĒ▓╗į┘│╔×ķ┴„╠Ä└Ē─Żą═Ą─ųŲ╝sĪŻ
öĄ(sh©┤)ō■┴„Ą─└Ēšō╝░╝╝ąg蹊┐ęčĮøėą╩«Äū─ĻĄ─Üv╩ĘŻ¼─┐Ū░╚į┼f╩Ū蹊┐¤ß³cĪŻė┌┤╦═¼Ģr║▄ČÓīŹļHŽĄĮy(t©»ng)ę▓ęčķ_░l(f©Ī)║═Ą├ĄĮÅVĘ║Ą─æ¬ė├Ż¼▒╚▌^┤·▒ĒąįĄ─ķ_į┤ŽĄĮy(t©»ng)╚ńTwitter Ą─StormĪóYahooĄ─S4ęį╝░Linkedin Ą─KafkaĄ╚ĪŻ
3.1.2 ┼·╠Ä└Ē
Google ╣½╦Šį┌2004 ─Ļ╠ß│÷Ą─MapReduceŠÄ│╠─Żą═╩ŪūŅŠ▀┤·▒ĒąįĄ─┼·╠Ä└Ē─Ż╩ĮĪŻę╗éĆ═Ļš¹Ą─MapReduce ▀^│╠╚ńłD2╦∙╩ŠŻ║
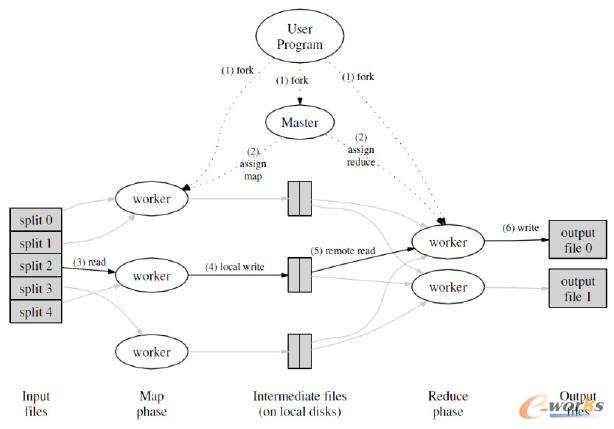
łD2 MapReduceł╠(zh©¬)ąą┴„│╠łD
MapReduce─Żą═╩ūŽ╚īóė├æ¶Ą─įŁ╩╝öĄ(sh©┤)ō■į┤▀MąąĘųēKŻ¼╚╗║¾ĘųäeĮ╗Įo▓╗═¼Ą─Map╚╬äšģ^(q©▒)╠Ä└ĒĪŻMap╚╬äšÅ─▌ö╚ļųąĮŌ╬÷│÷Key/Valueī”╝»║ŽŻ¼╚╗║¾ī”▀@ą®╝»║Žł╠(zh©¬)ąąė├æ¶ūįąąČ©┴xĄ─Map║»öĄ(sh©┤)Ą├ĄĮųąķgĮY╣¹Ż¼▓óīóįōĮY╣¹īæ╚ļ▒ŠĄžė▓▒PĪŻReduce╚╬äšÅ─ė▓▒P╔Žūx╚ĪöĄ(sh©┤)ō■ų«║¾Ż¼Ģ■Ė∙ō■key ųĄ▀Mąą┼┼ą“Ż¼īóŠ▀ėąŽÓ═¼key ųĄĄ─ĮM┐Śį┌ę╗ŲĪŻūŅ║¾ė├æ¶ūįČ©┴xĄ─Reduce║»öĄ(sh©┤)Ģ■ū„ė├ė┌▀@ą®┼┼║├ą“Ą─ĮY╣¹▓ó▌ö│÷ūŅĮKĮY╣¹ĪŻ
Å─MapReduceĄ─╠Ä└Ē▀^│╠╬ęéā┐╔ęį┐┤│÷Ż¼MapReduceĄ─║╦ą─įOėŗ╦╝Žļį┌ė┌Ż║
1)īóå¢Ņ}ĘųČ°ų╬ų«Ż╗
2)░čėŗ╦Ń═ŲĄĮöĄ(sh©┤)ō■Č°▓╗╩Ū░čöĄ(sh©┤)ō■═ŲĄĮėŗ╦ŃŻ¼ėąą¦Ą─▒▄├ŌöĄ(sh©┤)ō■é„▌ö▀^│╠ųą«a╔·Ą─┤¾┴┐═©ėŹķ_õNĪŻ
MapReduce─Żą═║åå╬Ż¼Ūę¼F(xi©żn)īŹųą║▄ČÓå¢Ņ}Č╝┐╔ė├MapReduce─Żą═üĒ▒Ē╩ŠĪŻę“┤╦įō─Żą═╣½ķ_║¾Ż¼┴ó┐╠╩▄ĄĮśO┤¾Ą─ĻPūóŻ¼▓óį┌╔·╬’ą┼ŽóīWĪó╬─▒Š═┌Š“Ą╚ŅIė“Ą├ĄĮÅVĘ║Ą─æ¬ė├ĪŻ
¤ošō╩Ū┴„╠Ä└Ē▀Ć╩Ū┼·╠Ä└ĒŻ¼Č╝╩Ū┤¾öĄ(sh©┤)ō■╠Ä└ĒĄ─┐╔ąą╦╝┬ĘĪŻ┤¾öĄ(sh©┤)ō■Ą─æ¬ė├ŅÉą═║▄ČÓŻ¼į┌īŹļHĄ─┤¾öĄ(sh©┤)ō■╠Ä└ĒųąŻ¼│Ż│Ż▓ó▓╗╩Ū║åå╬Ą─ų╗╩╣ė├ŲõųąĄ──│ę╗ĘNŻ¼Č°╩ŪīóČ■š▀ĮY║ŽŲüĒĪŻ╗ź┬ō(li©ón)ŠW╩Ū┤¾öĄ(sh©┤)ō■ūŅųžę¬Ą─üĒį┤ų«ę╗Ż¼║▄ČÓ╗ź┬ō(li©ón)ŠW╣½╦ŠĖ∙ō■╠Ä└ĒĢrķgĄ─ę¬Ū¾īóūį╝║Ą─śI(y©©)äšäØĘų×ķį┌ŠĆ(Online)ĪóĮ³ŠĆ(Nearline)║═ļxŠĆ(Offline)Ż¼▒╚╚ńų°├¹Ą─┬ÜśI(y©©)╔ńĮ╗ŠWšŠLinkedinĪŻ▀@ĘNäØĘųĘĮ╩Į╩Ū░┤╠Ä└Ē╦∙║─ĢrķgüĒäØĘųĄ─ĪŻŲõųąį┌ŠĆĄ─╠Ä└ĒĢrķgę╗░Ńį┌├ļ╝ēŻ¼╔§ų┴╩Ū║┴├ļ╝ēŻ¼ę“┤╦═©│Ż▓╔ė├╔Ž├µ╦∙šfĄ─┴„╠Ä└ĒĪŻļxŠĆĄ─╠Ä└ĒĢrķg┐╔ęįęį╠ņ×ķ╗∙▒Šå╬╬╗Ż¼╗∙▒Š▓╔ė├┼·╠Ä└ĒĘĮ╩ĮŻ¼▀@ĘNĘĮ╩Į┐╔ęįūŅ┤¾Ž▐Č╚Ą─└¹ė├ŽĄĮy(t©»ng)I/OĪŻĮ³ŠĆĄ─╠Ä└ĒĢrķgę╗░Ńį┌ĘųńŖ╝ē╗“š▀╩ŪąĪĢr╝ēŻ¼ī”Ųõ╠Ä└Ē─Żą═▓óø]ėą╠žäeĄ─ę¬Ū¾Ż¼┐╔ęįĖ∙ō■ąĶŪ¾ņ`╗Ņ▀xō±ĪŻĄ½į┌īŹļHųąČÓ▓╔ė├┼·╠Ä└Ē─Ż╩ĮĪŻ
3.2 ┤¾öĄ(sh©┤)ō■╠Ä└ĒĄ─╗∙▒Š┴„│╠
┤¾öĄ(sh©┤)ō■Ą─öĄ(sh©┤)ō■üĒį┤ÅVĘ║Ż¼æ¬ė├ąĶŪ¾║═öĄ(sh©┤)ō■ŅÉą═Č╝▓╗▒MŽÓ═¼Ż¼Ą½╩ŪūŅ╗∙▒ŠĄ─╠Ä└Ē┴„│╠ę╗ų┬ĪŻ║Ż┴┐Web öĄ(sh©┤)ō■Ą─╠Ä└Ē╩Ūę╗ŅÉĘŪ│ŻĄõą═Ą─┤¾öĄ(sh©┤)ō■æ¬ė├Ż¼Å─ųą┐╔ęįÜw╝{│÷┤¾öĄ(sh©┤)ō■╠Ä└ĒĄ─ūŅ╗∙▒Š┴„│╠ĪŻScholarSpaceė╔ųąć°╚╦├±┤¾īWŠWĮj┼cęŲäėöĄ(sh©┤)ō■╣▄└ĒīŹ“×╩ę(WAMDM)ķ_░l(f©Ī)Ż¼─┐ś╦╩ŪĮ©┴óę╗éĆ“ęį╚╦×ķ▒Š”Ż¼╝┤ęįū„š▀×ķųąą─üĒš╣╩ŠČÓīW┐Ųųą╬─╬─½IĄ─╝»│╔öĄ(sh©┤)ō■ÄņŽĄĮy(t©»ng)ĪŻ įōŽĄĮy(t©»ng)ęčĮøÅ─ūŅ│§Ą─ėŗ╦ŃÖCŅIė“öUš╣ĄĮ░³└©ĮøØ·ĪóĘ©┬╔Ą╚╚╦╬─╔ńĢ■┐ŲīWį┌ā╚Ą─ČÓŅIė“ĪŻÅ─öĄ(sh©┤)ō■│ķ╚Ī║═╝»│╔Ż¼ę╗ų▒ĄĮūŅĮKĄ─ĮY╣¹š╣╩ŠŻ¼ScholarSpace ═Ļš¹Ą─¾w¼F(xi©żn)│÷┤¾öĄ(sh©┤)ō■╠Ä└ĒĄ─ę╗░Ń┴„│╠ĪŻį┌Ųõ╗∙ĄA╔Ž╬ęéāÜw╝{│÷┤¾öĄ(sh©┤)ō■Ą─╗∙▒Š┴„│╠Ż¼╚ńłD3 ╦∙╩ŠŻ║
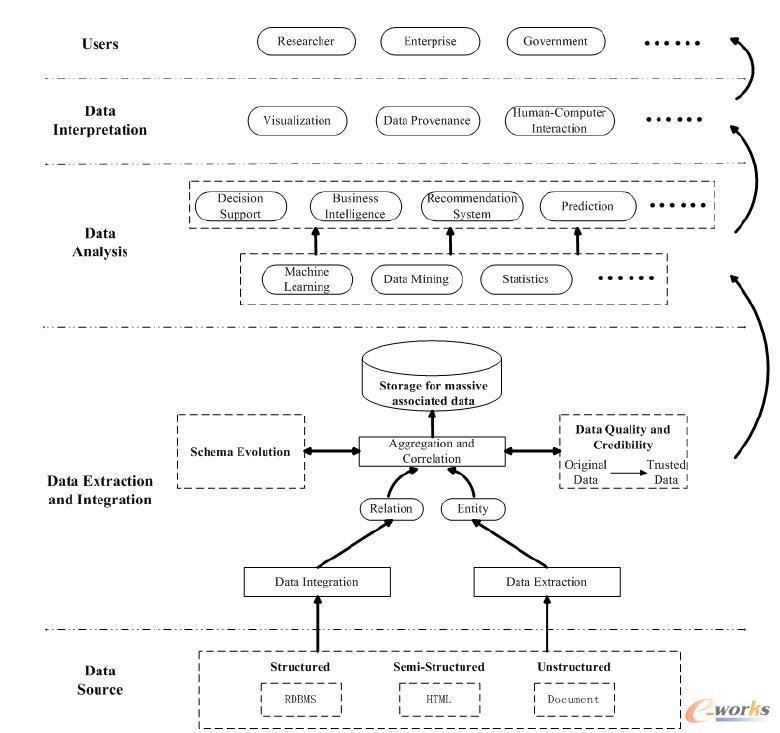
łD3 ┤¾öĄ(sh©┤)ō■╠Ä└Ē╗∙▒Š┴„│╠
š¹éĆ┤¾öĄ(sh©┤)ō■Ą─╠Ä└Ē┴„│╠┐╔ęįČ©┴x×ķį┌║Ž▀m╣żŠ▀Ą─▌oų·Ž┬Ż¼ī”ÅVĘ║«ÉśŗĄ─öĄ(sh©┤)ō■į┤▀Mąą│ķ╚Ī║═╝»│╔Ż¼ĮY╣¹░┤ššę╗Č©Ą─ś╦£╩Įy(t©»ng)ę╗┤µā”ĪŻ└¹ė├║Ž▀mĄ─öĄ(sh©┤)ō■Ęų╬÷╝╝ągī”┤µā”Ą─öĄ(sh©┤)ō■▀MąąĘų╬÷Ż¼Å─ųą╠ß╚ĪėąęµĄ─ų¬ūR▓ó└¹ė├ŪĪ«ö?sh©┤)─ĘĮ╩ĮīóĮY╣¹š╣¼F(xi©żn)ĮoĮKČ╦ė├æ¶ĪŻŠ▀¾wüĒšf┐╔ęįĘų×ķöĄ(sh©┤)ō■│ķ╚Ī┼c╝»│╔ĪóöĄ(sh©┤)ō■Ęų╬÷ęį╝░öĄ(sh©┤)ō■ĮŌßīĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äšŅIė“ĪóąąśI(y©©)æ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻPūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.hanmeixuan.com/
▒Š╬─ś╦Ņ}Ż║┤¾öĄ(sh©┤)ō■╣▄└ĒŻ║Ė┼─ŅĪó╝╝ąg┼c╠¶æ(zh©żn)Ż©╔ŽŻ®
▒Š╬─ŠWųĘŻ║http://m.hanmeixuan.com/html/support/1112189697.html



▀xą═ųąą─")
¾w“×ųąą─")
«aŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")