Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą─蹊┐ķ_╩╝ė┌20╩└╝o70─Ļ┤·ųąŲ┌Ż¼«ö(d©Īng)Ģr├└ć°ėŗ╦ŃÖC╣½╦ŠčąųŲ┴╦Ą┌ę╗éĆĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą─įŁą═SDD-1ĪŻ▀@éĆŽĄĮy(t©»ng)╩Ūį┌1976-1978─Ļ▀MąąįO(sh©©)ėŗ║═čą░l(f©Ī)Ą─Ż¼ų«║¾į┌1979─ĻīŹ¼F(xi©żn)┴╦į┌DEC-10║═DEC-20ėŗ╦ŃÖC╔ŽĄ─▓┐╩║═╩╣ė├ĪŻ╦³Äū║§░³└©┴╦Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą─╚½▓┐└Ēšō║═īŹ¼F(xi©żn)╝╝ąg(sh©┤)Ż¼╩ŪĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)░l(f©Ī)š╣Ą─ĄõĘČĪŻ─┐Ū░ęčĮø(j©®ng)ėąę╗ą®═¼śŗ(g©░u)Ęų▓╝║═«Éśŗ(g©░u)Ęų▓╝Ą─Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą─įŁą═ĪŻ
╬ęć°ī”Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĄ─蹊┐╩╝ė┌80─Ļ┤·Ż¼ļm╚╗Ų▓Į═ĒŻ¼Ą½╩ŪŲ³c▒╚▌^Ė▀ĪŻ─┐Ū░ęčĮø(j©®ng)čą░l(f©Ī)│÷Ą─įŁą═ŽĄĮy(t©»ng)¤ošō╩Ūąį─▄╔Ž▀Ć╩Ū╣”─▄╔ŽČ╝ęčĮø(j©®ng)▀_ĄĮ╩└ĮńŲĮŠ∙╦«ŲĮĪŻĮø(j©®ng)▀^īóĮ³Äū╩«─ĻĄ─░l(f©Ī)š╣Ż¼Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą─└Ēšō║═╝╝ąg(sh©┤)ęčĮø(j©®ng)ĘŪ│Ż│╔╩ņŻ¼Č°Ūę╝╝ąg(sh©┤)ļy³cå¢Ņ}ę▓ęčĮø(j©®ng)╣ź┐╦ĪŻį┌Š┼╩«─Ļ┤·ęčĮø(j©®ng)ėą«a(ch©Żn)ŲĘķ_╩╝▀M╚ļ╩ął÷Ż¼Ą½╩Ūė╔ė┌«ö(d©Īng)ĢrŽĄĮy(t©»ng)Å═(f©┤)ļsąįī”ė┌═Ļ╚½═Ė├„Ą─Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ▀Ć║▄ļy▀_ĄĮŻ¼╦∙ęį«ö(d©Īng)ĢrĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)╗∙▒Š╔Žø]ėą▀M╚ļīŹė├╗»ļAČ╬ĪŻ
Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)śO┤¾Ą─ØMūŃ┴╦«ö(d©Īng)Į±ą┼ŽóŽĄĮy(t©»ng)æ¬(y©®ng)ė├Ą─ąĶŪ¾Ż¼═¼Ģrę▓Ę¹║Ž«ö(d©Īng)Į±Ų¾śI(y©©)ĮM┐ŚĄ─╣▄└Ē╦╝Žļ║═ĘĮ╩ĮĪŻī”─Ūą®╣▄└Ē╔Ž╝»ųąČ°Ąžė“╔ŽĘų╔óĄ─┐ńć°╝»łFĪó┤¾ÖCĻP(gu©Īn)Īó┤¾Ų¾śI(y©©)Ż¼└²╚ń╚½Ū“ąįĄ─╗“╚½ć°ąįĄ─ŃyąąĪó╣½╦ŠĪó▒ŻļUśI(y©©)Īó▀BµiĄĻĪóĖ„ŅÉĮ╗═©▀\▌öśI(y©©)Ż¼ęį╝░╚½ć°ąįĄ─╚╦ĪóžöĪó┘Yį┤ĪóŁh(hu©ón)Š│╣▄└ĒÖCśŗ(g©░u)║═▄Ŗ╩┬ć°Ę└▓┐ķTĄ╚ąĶŪ¾śOŲõÅŖ┴ęĪŻį┌▀@ą®ĮM┐Ś«ö(d©Īng)ųąŻ¼╝╚ę¬ėąĖ„▓┐ķTĄ─Šų▓┐┐žųŲ║═Ęų╔ó╣▄└ĒŻ¼═¼Ģrę▓ąĶ꬚¹éĆĮM┐ŚĄ─╚½Šų┐žųŲęį╝░Ė▀īė┤╬Ą─ģf(xi©”)═¼╣▄└ĒĪŻę“┤╦Ż¼Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)╩Ū╬┤üĒöĄ(sh©┤)ō■(j©┤)ÄņĄ─▒ž╚╗┌ģä▌ĪŻ
ę╗ĪóĘų▓╝╩Į┤µā”Ą─Č©┴x
Ęų▓╝╩Į┤µā”Ż¼╩ŪīóöĄ(sh©┤)ō■(j©┤)Ęų╔ó┤µā”į┌ČÓ┼_¬Ü┴óĄ─┤µā”įO(sh©©)éõ╔ŽĪŻé„Įy(t©»ng)Ą─┤µā”ŽĄĮy(t©»ng)▓╔ė├╝»ųą╩ĮĄžĄ─Ę■äš(w©┤)Ų„üĒ┤µĘ┼╦∙ėąĄ─öĄ(sh©┤)ō■(j©┤)Ż¼ę“┤╦Ż¼┤µā”Ę■äš(w©┤)Ų„Ą─ąį─▄Š═│╔×ķŽĄĮy(t©»ng)ąį─▄Ą─Ų┐ŅiŻ¼═¼Ģrę▓╩Ū░▓╚½ąį║═┐╔┐┐ąįĄ─ĻP(gu©Īn)µI³cŻ¼¤oĘ©ØMūŃ┤¾ęÄ(gu©®)─Ż┤µā”Ą─ąĶę¬ĪŻĘų▓╝╩Į┤µā”▓╔ė├┐╔öUš╣Ą─ŽĄĮy(t©»ng)ĮY(ji©”)śŗ(g©░u)Ż¼═¼Ģr└¹ė├ČÓ┼_┤µā”Ę■äš(w©┤)Ų„üĒĘųō·(d©Īn)┤µā”žō║╔Ż¼└¹ė├╬╗ų├Ę■äš(w©┤)Ų„Č©╬╗┤µā”öĄ(sh©┤)ō■(j©┤)Ą─┤µā”╬╗ų├ą┼ŽóŻ¼╦³▓╗Ą½╠ßĖ▀┴╦ŽĄĮy(t©»ng)Ą─┐╔ė├ąįĪó┐╔┐┐ąį║═┤µ╚Īą¦┬╩Ż¼▀Ćęūė┌öUš╣┤µā”įO(sh©©)éõĪŻ
Ęų▓╝╩ĮŽĄĮy(t©»ng)ų„ę¬ų¦│ųĘų▓╝╩ĮĄ─╠Ä└ĒŻ¼╦³╩ŪČÓ╠Ä└ĒÖCĮY(ji©”)śŗ(g©░u)¾wŽĄŻ¼═©▀^ėŗ╦ŃÖCŠW(w©Żng)Įj(lu©░)░čČÓéĆ╠Ä└ĒÖC▀BĮėŲüĒŻ¼░čę╗éĆ╚╬äš(w©┤)ĘųĮŌ×ķČÓéĆūė╚╬äš(w©┤)╚╗║¾Ęų▓╝ĄĮČÓéĆ╠Ä└ĒÖC╔Ž═¼Ģrł╠(zh©¬)ąąŻ¼ūŅĮKīóĮY(ji©”)╣¹╔·│╔│÷üĒŻ¼ĘĄ╗žĮośI(y©©)äš(w©┤)ŽĄĮy(t©»ng)ĪŻĘų▓╝╩ĮŽĄĮy(t©»ng)ų„ę¬░³└©▓┘ū„ŽĄĮy(t©»ng)ĪóŠÄūgŽĄĮy(t©»ng)Īó╬─╝■ŽĄĮy(t©»ng)Īó│╠ą“įO(sh©©)ėŗ║═Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą╚ĪŻĘų▓╝╩ĮŽĄĮy(t©»ng)į┌▀Mąą╚╬äš(w©┤)╠Ä└ĒĢrŻ¼╩ūŽ╚īóę╗éĆėŗ╦ŃĄ─╚╬äš(w©┤)▓Ęų│╔ČÓéĆūė╚╬äš(w©┤)Ż¼īóČÓéĆūė╚╬äš(w©┤)Ęų░l(f©Ī)ĄĮČÓéĆ╠Ä└ĒÖC╔Ž═¼Ģr▀Mąą╠Ä└ĒŻ¼ūŅĮK║Ž▓óūė╚╬äš(w©┤)╠Ä└ĒĄ─ĮY(ji©”)╣¹Ż¼░čūŅĮKĮY(ji©”)╣¹╠ßĮ╗ĮośI(y©©)äš(w©┤)ŽĄĮy(t©»ng)╩╣ė├ĪŻ▀@ę╗³c┼c▓󹹎ĄĮy(t©»ng)ŽÓ╦ŲŻ¼Ą½╦³║═▓󹹎ĄĮy(t©»ng)ę▓┤µį┌ų°ģ^(q©▒)äeŻ¼Ęų▓╝╩ĮŽĄĮy(t©»ng)╩Ūīóūė╚╬äš(w©┤)å╬¬Ü▀Mąą╠Ä└ĒŻ¼¬Ü┴ół╠(zh©¬)ąąŻ¼ŽÓ╗źų«ķgÄū║§ø]ėą╚╬║╬ė░ĒæŻ¼└²╚ńŲõųąĄ─ę╗éĆūė╚╬äš(w©┤)į┌▀MąąśI(y©©)äš(w©┤)╠Ä└ĒĢrŻ¼ė╔ė┌─│ĘĮ├µįŁę“Ż¼ī¦(d©Żo)ų┬ĮY(ji©”)╣¹Õeš`╗“š▀öĄ(sh©┤)ō■(j©┤)«É│ŻŻ¼¤oĘ©ĘĄ╗žš²┤_Ą─ĮY(ji©”)╣¹Ż¼Ą½ī”Ųõ╦¹Ą─ūė╚╬äš(w©┤)ģsø]ėą╚╬║╬ė░ĒæŻ¼Ųõ╦¹ūė╚╬äš(w©┤)╚į─▄š²│Ż▀\ąąŻ¼ĘĄ╗žš²┤_Ą─ĮY(ji©”)╣¹ĪŻ╦∙ęįŻ¼Ęų▓╝╩ĮŽĄĮy(t©»ng)╩Ūį╩įSūŅĮKĄ─ĮY(ji©”)╣¹ėąę╗Č©Ą─Õeš`║═š`▓ŅŻ¼▓óŪęī”īŹĢrąįę¬Ū¾ę▓▓╗Ė▀Ą─ŽĄĮy(t©»ng)ĪŻ
╦³═©│Ż░³└©╚ńŽ┬╚²éĆ╗∙▒Š╠ž³cŻ║
1) Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)ųąūŅųžę¬╩ŪĄ─Ęųīė┐žųŲĮY(ji©”)śŗ(g©░u)Ż¼Ęųīė┐žųŲĮY(ji©”)śŗ(g©░u)╩Ūš¹éĆĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)╣▄└ĒĄ─╗∙ĄA(ch©│)Ż¼╦³═©│Żęį╚½ŠųöĄ(sh©┤)ō■(j©┤)Äņ×ķ║╦ą─Ż¼╩╣Ė„éĆŠų▓┐öĄ(sh©┤)ō■(j©┤)Äņ╣▄└ĒŽĄĮy(t©»ng)Č╝ōĒėą╣▄└Ē▒ŠĄžöĄ(sh©┤)ō■(j©┤)ÄņĄ─ūįų„ÖÓ(qu©ón)ĪŻ
2) öĄ(sh©┤)ō■(j©┤)Äņ¬Ü┴óąį╩Ūš¹éĆĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĄ─║╦ą─Ż¼Č°Ūęī”öĄ(sh©┤)ō■(j©┤)Ą─Ęų▓╝╩Į═Ė├„ąį▀Mąą┴╦Č©┴x║═ĮķĮBĪŻĘų▓╝╩Į═Ė├„ąį╩ŪųĖ│╠ą“Ą─š²┤_ąį▓╗╩▄öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)ęŲĄ─Įz║┴ė░ĒæŻ¼Ę┬ĘöĄ(sh©┤)ō■(j©┤)╩Ū╝»ųą╩Į┤µā”Ą─Ż¼═Ļ╚½ø]ėą▒╗Ęų╔óĪŻų╗╩Ūį┌╩╣ė├öĄ(sh©┤)ō■(j©┤)ĢrŻ¼═¼ĢrÅ─Ęų▓╝į┌▓╗═¼╬’└Ē╬╗ų├╔ŽĄ─öĄ(sh©┤)ō■(j©┤)Äņ▀Mąą╠ß╚ĪöĄ(sh©┤)ō■(j©┤)Ż¼╚╗║¾īó╠ß╚Ī│÷üĒĄ─öĄ(sh©┤)ō■(j©┤)▀Mąą║Ž▓óŻ¼ĘĄ╗žĮośI(y©©)äš(w©┤)ŽĄĮy(t©»ng)╩╣ė├Ż¼öĄ(sh©┤)ō■(j©┤)Ą─įLå¢╦┘Č╚▒╚╝»ųą╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╦┘Č╚ę¬┬²Ż¼ĮĄĄ═┴╦öĄ(sh©┤)ō■(j©┤)╠Ä└ĒĄ─ą¦┬╩ĪŻ
3) öĄ(sh©┤)ō■(j©┤)Ą─╚▀ėÓ╠žąį╩ŪĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)ą┬į÷Ą─ų„ę¬╠žąįŻ¼▀@ę▓╩ŪĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ║═╝»ųą╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĄ─ę╗éĆų„ę¬ģ^(q©▒)äeĪŻį÷╝ėöĄ(sh©┤)ō■(j©┤)Ą─╚▀ėÓČ╚ų„ę¬│÷ė┌ÄūéĆĘĮ├µŻ║ę╗ĘĮ├µŻ¼╬ęéāį┌▓╗═¼Ą─öĄ(sh©┤)ō■(j©┤)Äņ╣Ø(ji©”)³c╔Ž▒Ż┴¶ŽÓ═¼Ą─öĄ(sh©┤)ō■(j©┤)┐╔ęį╩╣ė├æ¶įLå¢öĄ(sh©┤)ō■(j©┤)Ģrų▒Įė╩╣ė├▒ŠĄžöĄ(sh©┤)ō■(j©┤)Ż¼╩╣▒ŠĄžöĄ(sh©┤)ō■(j©┤)ÄņĄ─æ¬(y©®ng)ė├į÷ÅŖĪŻ┴Ēę╗ĘĮ├µŻ¼«ö(d©Īng)─│éĆöĄ(sh©┤)ō■(j©┤)Äņ╣Ø(ji©”)³cę╗Ą®░l(f©Ī)╔·╣╩šŽ╗“š▀ōpē─ĢrŻ¼╬ęéā┐╔ęį═©▀^╩╣ė├Ųõ╦¹Ą─öĄ(sh©┤)ō■(j©┤)Äņ╣Ø(ji©”)³cüĒ▀MąąÅ═(f©┤)ųŲöĄ(sh©┤)ō■(j©┤)Ż¼Å─Č°▒ŻūC┴╦öĄ(sh©┤)ō■(j©┤)Äņ╣Ø(ji©”)³cĄ─š²│Ż▀\ąąŻ¼ī”Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą─ĘĆ(w©¦n)Č©ąį║═░▓╚½ąį╠ß╣®┴╦ėą┴”Ą─▒ŻšŽĪŻ
Č■ĪóĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĄ─Ė┼─Ņ
Į³─ĻüĒŻ¼ėŗ╦ŃÖC╝╝ąg(sh©┤)═╗’w├═▀MŻ¼ėŗ╦ŃÖCĄ─╩╣ė├įĮüĒįĮÅVĪŻå╬ėŗ╦ŃÖCŽĄĮy(t©»ng)Ą─Ę■äš(w©┤)Ų„įĮüĒįĮ¤oĘ©ØMūŃ╚╦éāī”ėŗ╦ŃÖCąį─▄║═╣”─▄╔ŽĄ─ąĶŪ¾Ż¼ę“┤╦Ż¼═©▀^ėŗ╦ŃÖCŠW(w©Żng)Įj(lu©░)▀BĮėČÓ┼_ėŗ╦ŃÖCĘ■äš(w©┤)Ų„ĮM│╔Ęų▓╝╩ĮŁh(hu©ón)Š│╩Ū«ö(d©Īng)Į±öĄ(sh©┤)ō■(j©┤)ÄņĄ─░l(f©Ī)š╣┌ģä▌ĪŻļSų°Ų¾śI(y©©)░l(f©Ī)š╣Ą─▓╗öÓēč┤¾Ż¼Ų¾śI(y©©)┌ģŽ“ė┌Ęų╔ó╗»Ż¼é„Įy(t©»ng)Ą─╝»ųą╩Į▄ø╝■ŽĄĮy(t©»ng)ęč¤oĘ©ØMūŃŲ¾śI(y©©)Ą─ąĶ꬯¼ķ_╩╝ų▓ĮÅ─╝»ųą╩Į▀^Č╔ĄĮĘų▓╝╩ĮĪŻĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ▒ž╚╗│╔×ķöĄ(sh©┤)ō■(j©┤)Äņ╝╝ąg(sh©┤)Ą─ų„ę¬čąŠ┐ĘĮŽ“ĪŻ
┴Ēę╗ĘĮ├µŻ¼į┌21╩└╝oĮø(j©®ng)Ø·░l(f©Ī)š╣ųąŻ¼ą┼Žó╩ŪŲ¾śI(y©©)░l(f©Ī)š╣║═öU┤¾Ą─║╦ą─ę“╦žĪŻė╔ė┌Ų¾śI(y©©)░l(f©Ī)š╣▓╗öÓēč┤¾Ż¼Ų¾śI(y©©)ĮY(ji©”)śŗ(g©░u)Ęų╔ó╗»╝ėäĪŻ¼╩╣Ą├é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)Äņ▓┐╩ĘĮ╩Įęč¤oĘ©ØMūŃŲ¾śI(y©©)Ą─ąĶ꬯¼öĄ(sh©┤)ō■(j©┤)ÄņĄ─Ęų▓╝╩Į▓┐╩ĘĮ╩ĮęčĮø(j©®ng)│╔×ķŲ¾śI(y©©)öĄ(sh©┤)ō■(j©┤)ÄņĄ─║╦ą─Ż¼ę▓╩Ū╬┤üĒöĄ(sh©┤)╩«─Ļų«ā╚(n©©i)Ą─░l(f©Ī)š╣ĘĮŽ“ĪŻ
Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņė╔ę╗ĮMöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cśŗ(g©░u)│╔Ż¼▀@ą®öĄ(sh©┤)ō■(j©┤)Äņ╣Ø(ji©”)³cį┌▀ē▌ŗ╔Ž╩Ū═¼ę╗éĆöĄ(sh©┤)ō■(j©┤)ÄņŻ¼Ą½╩Ū╬’└Ē╔Ž▀@ą®öĄ(sh©┤)ō■(j©┤)Äņ╣Ø(ji©”)³cģs╩ŪĘų╔óį┌▓╗═¼Ąž└Ē╬╗ų├Ż¼═©▀^ėŗ╦ŃÖCŠW(w©Żng)Įj(lu©░)īóŲõ▀BĮėŲüĒŻ¼▓óĮy(t©»ng)ę╗ė╔Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╣▄└ĒŽĄĮy(t©»ng)▀MąąöĄ(sh©┤)ō■(j©┤)Ą─╣▄└ĒŻ¼╣▄└Ē╦∙ėą╣Ø(ji©”)³c╔ŽĄ─öĄ(sh©┤)ō■(j©┤)ĪŻ
░┤╣”─▄▀MąąäØĘųŻ¼Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)ų„ę¬░³└©Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╣▄└ĒŽĄĮy(t©»ng)║═Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĪŻĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╩╣ė├ėŗ╦ŃÖCŠW(w©Żng)Įj(lu©░)īóĘų╔óį┌Ė„ĄžĄ─Ė„éĆöĄ(sh©┤)ō■(j©┤)Äņ╣Ø(ji©”)³c▀BĮėŲüĒą╬│╔ę╗éĆĮy(t©»ng)ę╗Ą─▀ē▌ŗ╝»║ŽĪŻĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņų„ę¬░³└©Šų▓┐æ¬(y©®ng)ė├║═╚½Šųæ¬(y©®ng)ė├Ż║Ęų▓╝æ¬(y©®ng)ė├(╗“╚½Šųæ¬(y©®ng)ė├)ų„ę¬╩ŪųĖī”ā╔éĆęį╔ŽĮY(ji©”)³c╔ŽĄ─öĄ(sh©┤)ō■(j©┤)Äņł╠(zh©¬)ąąæ¬(y©®ng)ė├Ż╗Č°Šų▓┐æ¬(y©®ng)ė├āHī”▒ŠĮY(ji©”)³cĄ─öĄ(sh©┤)ō■(j©┤)Äņł╠(zh©¬)ąąæ¬(y©®ng)ė├ĪŻų╗ėąų¦│ų╚½Šųæ¬(y©®ng)ė├Ą─▓┼▒╗ĘQ×ķĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)ĪŻ╦³ų„ę¬ī”Ęų▓╝╩ĮŁh(hu©ón)Š│Ž┬öĄ(sh©┤)ō■(j©┤)▀Mąą╣▄└Ē║═ŠSūoŻ¼╩╣öĄ(sh©┤)ō■(j©┤)▒Ż│ųę╗ų┬ĪŻ
╚²ĪóĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą─¾wŽĄĮY(ji©”)śŗ(g©░u)
Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ą─¾wŽĄĮY(ji©”)śŗ(g©░u)ų„ę¬ė╔Šų▓┐Ė┼─ŅīėĪóŠų▓┐ā╚(n©©i)īėĪó╚½Šų═Ōīėęį╝░╚½ŠųĖ┼─ŅīėĄ╚Äū▓┐ĘųĮM│╔Ą─Ż¼Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╩Ū═©▀^ŠW(w©Żng)Įj(lu©░)═©ėŹĪó╚½ŠųöĄ(sh©┤)ō■(j©┤)Äņ╣▄└ĒŽĄĮy(t©»ng)ęį╝░Šų▓┐öĄ(sh©┤)ō■(j©┤)Äņ╣▄└ĒŽĄĮy(t©»ng)═¼Ģr▀Mąą╣▄└ĒĄ─ĪŻ╚²š▀╣▓═¼śŗ(g©░u)│╔┴╦Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĄ─╣▄└ĒŽĄĮy(t©»ng)ĪŻ═©▀^ī”╦³éāĄ─īŹ¼F(xi©żn)Ż¼ų¦ō╬┴╦š¹éĆĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ¾wŽĄĪŻ
Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)╩Ūé„Įy(t©»ng)Ą─╝»ųą╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)į┌ėŗ╦ŃÖCŠW(w©Żng)Įj(lu©░)ĘĮ├µĄ─Ą─čė╔ņĪŻę“┤╦Ż¼Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ▓╗āHŠ▀ėąé„Įy(t©»ng)╝»ųą╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĄ─╚½▓┐╠ž³cŻ¼═¼Ģr╦³ėų▒╚╝»ųą╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╝╝ąg(sh©┤)īŹ¼F(xi©żn)╔Žę¬Ū¾Ė³Ė▀Ż¼īŹ¼F(xi©żn)Ė³╝ėÅ═(f©┤)ļsĪŻ
Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)ų„ę¬äØĘų×ķęįŽ┬╦─īė─Ż╩ĮŻ¼╚ńŽ┬łD╦∙╩ŠĪŻ▀@╦─īėų„ę¬░³└©Ż║╚½ŠųĖ┼─Ņ═ŌīėĪó╚½ŠųęĢłD(╗“ĘQ╚½Šų═Ōīė)ĪóŠų▓┐ā╚(n©©i)īėęį╝░Šų▓┐Ė┼─ŅīėĄ╚╗∙▒Š▓┐ĘųĪŻĖ„éĆīė┤╬ų«ķgōĒėąĖ„ūįĄ─┬ō(li©ón)ŽĄŻ¼▀Mąą▓╗═¼ė│╔õĪŻ
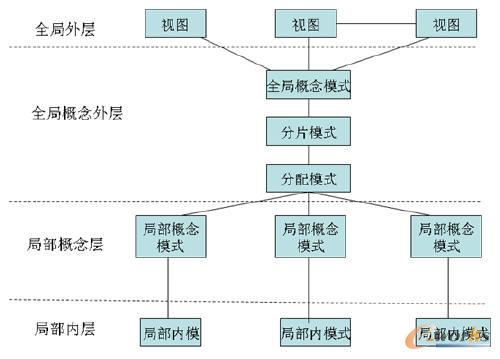
Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)ĮY(ji©”)śŗ(g©░u)łD
Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╩Ūš¹éĆŲ¾śI(y©©)╦ĮėąįŲ╝▄śŗ(g©░u)į┌öĄ(sh©┤)ō■(j©┤)┤µā”ĘĮ├µĄ─ĻP(gu©Īn)µI║╦ą─Ż¼╦³Ą─īŹ¼F(xi©żn)ī”ė┌╦ĮėąįŲŲĮ┼_Ą─īŹ¼F(xi©żn)ų┴ĻP(gu©Īn)ųžę¬Ż¼ė╚Ųõ╩ŪįŲėŗ╦ŃERPĄ─īŹ¼F(xi©żn)ĪŻERPŽĄĮy(t©»ng)ūŅĻP(gu©Īn)µIĄ─║╦ą─Š═╩ŪöĄ(sh©┤)ō■(j©┤)Ż¼Č°öĄ(sh©┤)ō■(j©┤)Ą─┤µā”ę╗ų▒╩ŪŽĄĮy(t©»ng)Ą─ąį─▄Ų┐ŅiŻ¼ų╗ėąÅ─Ė∙▒Š╔ŽĮŌøQöĄ(sh©┤)ō■(j©┤)┤µā”å¢Ņ}▓┼─▄ÅžĄūĮŌøQERPŽĄĮy(t©»ng)Ą─ąį─▄Ų┐ŅiĪŻĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņÅ─Ė∙▒Š╔ŽĮŌøQ┴╦öĄ(sh©┤)ō■(j©┤)Ą─┤µā”Ż¼═©▀^░č▓╗═¼Ą─śI(y©©)äš(w©┤)ŽĄĮy(t©»ng)─ŻēKĄ─öĄ(sh©┤)ō■(j©┤)▓┐╩ĄĮ▓╗═¼Ą─öĄ(sh©┤)ō■(j©┤)ÄņĘ■äš(w©┤)Ų„╔ŽŻ¼Å─Č°£p╔┘┴╦å╬éĆöĄ(sh©┤)ō■(j©┤)ÄņĄ─▓ó░l(f©Ī)▓┘ū„║═║Ż┴┐öĄ(sh©┤)ō■(j©┤)Ą─╠Ä└ĒŻ¼Å─Ė∙▒Š╔Ž╠ß╔²┴╦ąį─▄ĪŻ╦∙ęįŻ¼Ęų▓╝╩Į┤µā”╩Ū╬┤üĒERPöĄ(sh©┤)ō■(j©┤)┤µā”Ą─░l(f©Ī)š╣ĘĮŽ“ĪŻ
▒Š╬─ų„ę¬ĮķĮB┴╦Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĄ─Č©┴xĪó╠ž³cĪóĘųŅÉĪóŽĄĮy(t©»ng)ĮY(ji©”)śŗ(g©░u)Ą╚ĘĮ├µŻ¼═©▀^ī”Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ║╦ą─╝╝ąg(sh©┤)Ą─蹊┐Ż¼║¾Ų┌╬ęéāīóįO(sh©©)ėŗį┌╦ĮėąįŲŲĮ┼_ĘĮ├µĄ─öĄ(sh©┤)ō■(j©┤)Ą─Ęų▓╝╩Į╝▄śŗ(g©░u)Ż¼īŹ¼F(xi©żn)įŲėŗ╦ŃERPöĄ(sh©┤)ō■(j©┤)┤µā”į┌Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)Äņ╔ŽĄ─æ¬(y©®ng)ė├ĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.hanmeixuan.com/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║Ų¾śI(y©©)╦ĮėąįŲį┌RS10ųąĄ─æ¬(y©®ng)ė├ų«Č■Ż║įŲėŗ╦ŃųąĄ─Ęų▓╝╩Į┤µā”
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.hanmeixuan.com/html/consultation/10839710570.html



▀xą═ųąą─")
¾w“×ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")