ĪČųą╣▓ųąčļĪóć°äšį║ĻPė┌╔Ņ╗»ßt(y©®)╦Äąl(w©©i)╔·¾wųŲĖ─Ė’Ą─ęŌęŖĪĘ├„┤_ųĖ│÷Ż║“Į©┴óĘų╣ż├„┤_Īóą┼Žó╗ź═©Īó┘Yį┤╣▓ŽĒĪóģf(xi©”)š{╗źäėĄ─╣½╣▓ąl(w©©i)╔·Ę■äš¾wŽĄĪŻ”į┌╚½ć°ģ^(q©▒)ė“╗»ßt(y©®)»¤ąl(w©©i)╔·Ė─Ė’▀M│╠ųąŻ¼ģ^(q©▒)ė“łDŲ¼┤µÖn╝░═©ėŹŽĄĮy(t©»ng)Ż©PACSŻ®╩Ū▒╚▌^ųžę¬Ą─ę╗Łh(hu©ón)ĪŻģ^(q©▒)ė“PACS ųĖęįģ^(q©▒)ė“ŠW(w©Żng)ĮjŲĮ┼_×ķ╗∙ĄAŻ¼ęįģ^(q©▒)ė“ā╚ųąą─ßt(y©®)į║╗“┤¾ßt(y©®)į║×ķ║╦ą─Ż¼Į©┴ó┐ńßt(y©®)į║║═ßt(y©®)»¤ÖCśŗĄ─ßt(y©®)īWė░Ž±ą┼ŽóĮ╗ōQŲĮ┼_Ż¼īŹ¼F(xi©żn)ģ^(q©▒)ė“ā╚ßt(y©®)īWė░Ž±öĄ(sh©┤)ō■(j©┤)┼cą┼ŽóĄ─╣▓ŽĒĪŻĄ½─┐Ū░ļx▀@éĆ─┐ś╦╚į╚╗ėąŽÓ«öę╗Č╬ŠÓļxŻ¼Ųõųąė÷ĄĮūŅ┤¾Ą─šŽĄKŠ═╩Ūßt(y©®)īWė░Ž±╬─╝■Ą─┤µā”å¢Ņ}ĪŻ
1.ģ^(q©▒)ė“PACSī”┤µā”Ą─ę¬Ū¾
1.1 ┤µā”╠ž³c
PACS ┤µā”ų„ę¬╩ŪųĖłDŽ±╬─╝■Ą─┤µā”Ż¼Ųõ╠ž³cŻ║ó┘ öĄ(sh©┤)ō■(j©┤)┴┐┤¾Ż¼į÷ķL╦┘Č╚┐ņŻ¼╚ń301 ßt(y©®)į║Ą─Ę┼╔õ┐Ų├┐╠ņĄ─ė░Ž±ē║┐s║¾ę▓ėą40ČÓGBŻ¼1─Ļ╝s10TBŻ╗ó┌ łDŽ±╬─╝■═©ėŹĖ±╩Į×ķDICOMĪó╬─╝■│▀┤ń▌^┤¾Ż╗ó█ öĄ(sh©┤)ō■(j©┤)▒Ż┤µĢrķgķLŻ¼ßt(y©®)īWė░Ž±ę╗░Ńę¬Ū¾─▄┤µā”15 ─ĻŻ╗ó▄ ┐╔Ęų╝ē┤µā”Ż¼Į³Ų┌įLå¢┴┐┤¾Ą─öĄ(sh©┤)ō■(j©┤)▓╔ė├į┌ŠĆ┤µā”Ż¼▀hŲ┌įLå¢┴┐ąĪĄ─öĄ(sh©┤)ō■(j©┤)▓╔ė├Į³ŠĆ╗“ļxŠĆ┤µā”Ż╗ó▌ ┐╔═©▀^ÜwÖn╣▄└Ē╣”─▄Ż¼īŹ¼F(xi©żn)╚▌×─▒ŻūoĪŻ
ßśī”▀@ą®╠ž³cŻ¼ģ^(q©▒)ė“PACS įOėŗæ¬įō▓╔ė├ČÓöĄ(sh©┤)ō■(j©┤)ųąą─Ą──Ż╩ĮŻ¼ęį▒ŻūC╠ß╣®ČÓéĆ┤µā”╣Ø(ji©”)³cĄ─öĄ(sh©┤)ō■(j©┤)Ę■äšĪŻ
1.2 ┤µā”¼F(xi©żn)ĀŅ
─┐Ū░Ż¼Ė„ßt(y©®)į║Ą─PACS ę╗░ŃČ╝ū±čŁDICOM ś╦£╩Ż¼Č°į┌┤µā”ĘĮ├µätĖ„ąąŲõ▒ŃŻ¼ø]ėąĮy(t©»ng)ę╗ęÄ(gu©®)ĘČĪŻ«ößt(y©®)į║Ą─śI(y©©)äš░l(f©Ī)š╣įĮüĒįĮ┤¾Ż¼ęį╝░├µŽ“ģ^(q©▒)ė“╗»║¾Ż¼▀@ą®PACS Š═Ģ■├µ┼RŽ┬├µĄ─å¢Ņ}Ż║ó┘ ┤µā”┐╔öUš╣ąį▓ŅŻ¼ČÓöĄ(sh©┤)ßt(y©®)į║Ą─PACS ┤µā”╝▄śŗ║▄ļyķLŲ┌ų¦│ųŻ¼├┐▀^ę╗Č©ĢrķgŠ═ę¬▀MąąöU╚▌▓┘ū„Ż¼Č°ŪęöU╚▌║¾╬─╝■▓ķįā╦č╦„Ą╚ąį─▄ŽÓæ¬ĮĄĄ═Ż╗ó┌ ģ^(q©▒)ė“╣▓ŽĒ└¦ļyŻ¼Ė„ßt(y©®)į║Ą─PACS ų«ķgę¬Į©┴óöĄ(sh©┤)ō■(j©┤)╣▓ŽĒŻ¼ų╗─▄Į©┴óĖ„ūįĄ─┤µā”Įė┐┌üĒīŹ¼F(xi©żn)Ż¼▀@ĘNöĄ(sh©┤)ō■(j©┤)é„▌öĘĮ╩Į╩Ūæ¬ė├īė├µĄ─Ż¼╦³Ą─Ė─äėĢ■ī¦ų┬Ė„PACS ŽÓæ¬ūāäėŻ¼įņ│╔╔²╝ēŠSūo└¦ļyŻ╗ó█ ░▓╚½ąį▓╗╝čŻ¼┤µā”öĄ(sh©┤)ō■(j©┤)Ą─éõĘ▌┤ļ╩®▓╗ūŃŻ¼║▄╚▌ęūę“ė▓▒P╣╩šŽĄ╚įŁę“ī¦ų┬ė░Ž±öĄ(sh©┤)ō■(j©┤)Ą─┤¾┴┐üG╩¦Ż¼╔§ų┴¤oĘ©╗ųÅ═ĪŻ
PACS ╠ß╣®╔╠ų„ę¬īŻūóė┌æ¬ė├īė├µŻ¼┤µā”īė├µīŻśI(y©©)ąį▓╗ē“ĪŻę¬ĮŌøQ╔Ž╩÷å¢Ņ}Ż¼ų╗ėąĮ©┴óĮy(t©»ng)ę╗Ą─┤µā”ŲĮ┼_▓┼─▄Ą├ęįĮŌøQĪŻÅ─įŲėŗ╦Ń░l(f©Ī)š╣Č°üĒĄ─įŲ┤µā”╩Ūę╗éĆ║▄║├Ą─ĮŌøQĘĮ░ĖĪŻ
2.╗∙ė┌įŲ┤µā”Ą─ģ^(q©▒)ė“PACS╝▄śŗįOėŗ
2.1 įŲ┤µā”ā×(y©Łu)ä▌
ģ^(q©▒)ė“PACS ŲĮ┼_Į©įO┐╔ęį░┤╗ņ║ŽįŲĄ─ĘĮ╩Į▀MąąŻ¼╝┤į┌ģ^(q©▒)ė“PACS ŲĮ┼_ā╚▓┐Ż¼├┐éĆßt(y©®)į║Ą─öĄ(sh©┤)ō■(j©┤)ųąą─Š∙ū„×ķįŲ┤µā”Ą─ę╗éĆå╬į¬Ż¼╦³éā┬ō(li©ón)║ŽĮM│╔ģ^(q©▒)ė“PACS ŲĮ┼_Ą─╦ĮėąįŲ┤µā”Ż¼ų„ę¬ė├üĒ┤µĘ┼Į³Ų┌öĄ(sh©┤)ō■(j©┤)ĪŻ▀hŲ┌öĄ(sh©┤)ō■(j©┤)┐╔┤µĘ┼į┌╔╠śI(y©©)įŲ┤µā”ųąŻ¼═¼Ģrį┌Ė„öĄ(sh©┤)ō■(j©┤)Ą─▒ŠĄžū÷║├éõĘ▌ĪŻ╦ĮėąįŲ┤µā”ęįĖ▀╦┘ŠW(w©Żng)Įj▀MąąĮ©įOŻ¼╚ń╠ōöM╦Į╚╦ŠW(w©Żng)ĮjŻ©VPNŻ®īŻŠĆŻ¼ęį▒ŻūCĮ³Ų┌öĄ(sh©┤)ō■(j©┤)ūx╚ĪĄ─é„▌ö╦┘Č╚Ż╗▀hŲ┌öĄ(sh©┤)ō■(j©┤)┤µĘ┼į┌╔╠śI(y©©)įŲ┤µā”ųąŻ¼╝┤╩╣╣½ėąŠW(w©Żng)Įj╦┘Č╚▌^┬²Ż¼öĄ(sh©┤)ō■(j©┤)ūx╚Ī╦┘Č╚ę▓─▄Įė╩▄ĪŻ▓╔ė├įŲ┤µā”Ą─ųTČÓā×(y©Łu)ä▌Ż║
Ż©1Ż®│╔▒Šā×(y©Łu)ä▌ĪŻßt(y©®)į║ų╗ąĶ┘Å┘I▒Ż┤µĮ³Ų┌ė░Ž±╬─╝■Ą─įOéõŻ¼▀hŲ┌Ą─ÜwÖnöĄ(sh©┤)ō■(j©┤)Ę┼į┌╔╠śI(y©©)įŲ┤µā”ųąŻ¼▓╗ąĶę¬═Č╚ļ┤¾┴┐┘YĮ┘Å┘IūŃē“Ą─┤µā”įOéõĪó▄ø╝■Į©įO║═╚╦┴”│╔▒Š═Č╚ļĪŻ
Ż©2Ż®╣▄└Ēā×(y©Łu)ä▌ĪŻįŲ┤µā”╠ß╣®╔╠žōž¤┤µā”įOéõĄ─▀\▐DĪóŠSūoĪó╔²╝ē╝░╚š│Ż╣▄└Ē╣żū„Ż¼ßt(y©®)į║╣Ø(ji©”)╩Ī┴╦ŽÓĻP═Č╚ļĪŻ
Ż©3Ż®öUš╣ā×(y©Łu)ä▌ĪŻįŲ┤µā”Ą─▓óąą╝▄śŗįŁ└ĒøQČ©┴╦ŲõöUš╣ĘĮ▒ŃąįŻ¼ė├æ¶ų╗ąĶ┘Å┘I┐šķgŻ¼▓╗ė├┐╝æ]┐šķgĄ─öUš╣┼c╔²╝ēĪŻ
Ż©4Ż®įLå¢ā×(y©Łu)ä▌ĪŻī”ė┌╩╣ė├įŲ┤µā”Ą─ģ^(q©▒)ė“PACS ŽĄĮy(t©»ng)Ż¼«öė├æ¶į┌ģ^(q©▒)ė“═ŌĄŪõøŽĄĮy(t©»ng)ĢrŻ¼┼cįL墊W(w©Żng)šŠę╗śėĘĮ▒ŃŻ¼▀@éĆ╠žąįī”ė┌ęŲäėųŪ─▄ĮKČ╦ė├æ¶║▄ėąė├ĪŻ─┐Ū░║▄ČÓ╚²╝ūßt(y©®)į║į┌═ŲÅV╩╣ė├IPADĪó╩ųÖCĄ╚ųŪ─▄ĮKČ╦▀Mąą┼R┤▓į\öÓĄ╚ßt(y©®)äš▓┘ū„ĪŻī”ė┌▓╔ė├įŲ┤µā”Ą─PACS üĒšfŻ¼Å─ļŖ─XĄĮųŪ─▄ĮKČ╦Ą─ęŲų▓īóĢ■ūāĄ├ĘŪ│Ż╚▌ęūĪó│╔▒ŠĄ═ĪŻ
Ż©5Ż®Č©ųŲā×(y©Łu)ä▌ĪŻ▓╗═¼ßt(y©®)į║ī”ė┌┤µā”Ą─ąĶŪ¾Ė„ėąģ^(q©▒)äeŻ¼į┌┼õų├å¢Ņ}╝╚ę¬ØMūŃąį─▄┼c░▓╚½ę¬Ū¾Ż¼ėųę¬╣Ø(ji©”)╩Ī│╔▒ŠĪŻįŲ┤µā”Ę■äš╔╠Ģ■Ė∙ō■(j©┤)ģ^(q©▒)ė“PACSĄ─ąĶŪ¾Ūķøręį╝░ĒŚ─┐Ą─ŅA╦ŃŻ¼╠ß╣®║Ž▀mĄ─┤µā”ĮŌøQĘĮ░ĖĪŻę“┤╦įŲ┤µā”«aŲĘ▓╗āH╠ß╣®┴╦┐šķg▒Š╔ĒŻ¼▀ĆĖ∙ō■(j©┤)ąĶŪ¾Įo│÷┴╦ę╗éĆ┴┐╔ĒČ©ųŲĄ─ĮŌøQĘĮ░ĖĪŻ
2.2 Hadoop║åĮķ
Hadoop ╩Ūė╔Apache ╗∙ĮĢ■ķ_░l(f©Ī)Ą─ķ_į┤Ą─Ęų▓╝╩ĮŽĄĮy(t©»ng)╗∙ĄA╝▄śŗŻ¼╝╚╩Ūė├æ¶▓╗┴╦ĮŌĄūīė╝Ü╣Ø(ji©”)Ą─ŪķørŻ¼ę▓┐╔ęįķ_░l(f©Ī)Ęų▓╝╩Į│╠ą“ĪŻHadoop ŲĮ┼_┐╔▀\ąąį┌Ųš═©Ą─PC ÖC╚║╔ŽŻ¼śO┤¾ĄžĮĄĄ═┴╦蹊┐ķ_░l(f©Ī)│╔▒ŠĪŻHadoop ┐“╝▄ųąūŅ║╦ą─Ą─įOėŗ╩ŪHDFSŻ©Hadoop Distributed File SystemŻ®ĪóMapReduce ║═HBaseĪŻ
HDFS ╩ŪGoogle Ą─Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ż©Google File SystemŻ¼GFSŻ®Ą─ķ_į┤īŹ¼F(xi©żn)ĪŻŲõ╠ž³cŻ║╚▌ÕeąįĖ▀Ż¼┐╔į┌Ą═┴«Ą─ė▓╝■╔Ž▀Mąą▓┐╩Ż╗öĄ(sh©┤)ō■(j©┤)é„▌ö╦┘Č╚Ė▀Ż¼ī”ė┌öĄ(sh©┤)ō■(j©┤)╝»┤¾Ą─æ¬ė├│╠ą“╠žäe▀m║ŽŻ╗įLå¢┐╔öUš╣ąį║├Ż¼ų╗ąĶ║åå╬Ąžį┌╝»╚║└’╠Ē╝ė╣Ø(ji©”)³cŠ═─▄īŹ¼F(xi©żn)┐═æ¶Č╦═¼ĢrįLå¢öĄ(sh©┤)┴┐ČÓĄ─ŪķørŻ╗▓┘ū„ĘĮ▒ŃŻ¼═¼śėėąé„Įy(t©»ng)╬─╝■▓┘ū„Ż¼╚ń╬─╝■Ą─äō(chu©żng)Į©Īóäh│²Īóųž├³├¹Ą╚Ż╗HDFS öĄ(sh©┤)ō■(j©┤)ēKĄ─┤¾ąĪ─¼šJ×ķ64 MBŻ¼▀m║Ž╠Ä└Ē║═┤µā”┤¾╬─╝■Ż¼Ą½ī”ąĪ╬─╝■▓╗▀m║ŽĪŻ
HDFS ╩Ūų„Å─ĮYśŗĄ─¾wŽĄ┐“╝▄Ż¼ę╗éĆHDFS ╝»╚║═©│Żė╔ę╗éĆNameNode ╣Ø(ji©”)³c┼cČÓéĆDataNode ╣Ø(ji©”)³cĮM│╔ĪŻNameNode╣Ø(ji©”)³c╩Ūų„Ę■äšŲ„Ż¼Ųõ╣”─▄ėą╣▄└Ē┐═æ¶Č╦įLå¢Īó╣▄└ĒöĄ(sh©┤)ō■(j©┤)į¬║═╬─╝■ēKĪó╣▄└Ē├³├¹┐šķgĪó▒O(ji©Īn)┬ĀšłŪ¾║═╠Ä└ĒšłŪ¾Īóą─╠°Öz£yĄ╚ĪŻČ°Ė„DataNode ╣Ø(ji©”)³cätžōž¤öĄ(sh©┤)ō■(j©┤)ēKĄ─ūxīæŻ¼Ž“NameNode ł¾Ėµ╣Ø(ji©”)³cĀŅæB(t©żi)Ż¼ł╠(zh©¬)ąąöĄ(sh©┤)ō■(j©┤)Ą─┴„╦«ŠĆÅ═ųŲĄ╚┤µā”╣▄└Ē╣żū„ĪŻ
MapReduce ╩Ūė╔Map ║═Reduce ║»öĄ(sh©┤)ĮM│╔Ą─ę╗ĘN║å╗»Ą─▓óąąėŗ╦Ń─Żą═Ż¼Ęųäe▀Mąą╚╬䚥─ĘųĮŌ║═ī”ĮY╣¹Ą─ģR┐éĪŻŲõįŁ└Ē╩Ūīó┤²╠Ä└ĒĄ─öĄ(sh©┤)ō■(j©┤)╝»ĘųĮŌ│╔ČÓéĆūėöĄ(sh©┤)ō■(j©┤)╝»Ż¼Ūę├┐ę╗ūėöĄ(sh©┤)ō■(j©┤)╝»Č╝┐╔▓óąą╠Ä└ĒĪŻķ_░l(f©Ī)╚╦åTĄ─ų„ę¬╣żū„╩ŪīŹ¼F(xi©żn) Map ║═Reduce ║»öĄ(sh©┤)Ż¼Č°▓╗▒ž╚ź┐╝æ]ę╗ą®Ąūīė╝Ü╣Ø(ji©”)Ż¼╚ń╚▌Õe╠Ä└ĒĪóžō▌dŲĮ║ŌĪóŠW(w©Żng)Įj═©ą┼Ą╚Ż¼ę“┤╦ķ_░l(f©Ī)ĘŪ│ŻĘĮ▒Ń╚▌ęūĪŻ
HBase ╩Ūę╗éĆķ_į┤Ą─Īó╗∙ė┌┴ą┤µā”─Żą═Ą─Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņŻ¼╩ŪGoogle Ą─Bigtable Ęų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)ÄņĄ─ķ_į┤īŹ¼F(xi©żn)Ż¼╦³├µŽ“┴ąŻ¼┐╔╔ņ┐sąįĪó┐╔┐┐ąįĖ▀Ż¼ąį─▄║├Ż¼Ųõ╬─╝■┤µā”ŽĄĮy(t©»ng)╩ŪHadoop HDFSŻ¼└¹ė├┤╦╝╝ąg┐╔į┌Ųš═©PC ÖC╔ŽĮ©┴ó┤¾ęÄ(gu©®)─ŻĮYśŗ╗»┤µā”╝»╚║ĪŻ
ęį▀@ą®║╦ą─ų¦ų∙×ķ╗∙ĄAĄ─HadoopŻ¼─▄ē“ī”┤¾┴┐öĄ(sh©┤)ō■(j©┤)▀MąąĘų▓╝╩Į╠Ä└ĒĪŻŲõĖ▀┐╔┐┐ąį¾w¼F(xi©żn)į┌╦³▒Ż┤µĄ─öĄ(sh©┤)ō■(j©┤)ėąČÓéĆĖ▒▒ŠŻ¼┤_▒Ż─▄ē“ßśī”╩¦öĪĄ─╣Ø(ji©”)³cųžą┬Ęų▓╝╠Ä└ĒŻ¼▀@ę▓╩╣ŲõŠ▀ėąĖ▀╚▌ÕeąįĪŻė╔ė┌ęį▓󹹥─ĘĮ╩Į╣żū„Ż¼╠Ä└Ē╦┘Č╚┤¾┤¾╝ė┐ņŻ¼ę“┤╦Š▀ėąĖ▀ą¦ąįĪŻŲõ┐╔╔ņ┐sąįät╩Ūė╔ė┌╦³┐╔ĘĮ▒Ńį÷╝ė╣Ø(ji©”)³cŻ¼─▄ē“╠Ä└Ē PB ╝ēöĄ(sh©┤)ō■(j©┤)ĪŻ┤╦═ŌŻ¼Hadoop Ą─Į©įO│╔▒ŠĄ═Ż¼ęįHadoop Į©┴óģ^(q©▒)ė“PACS Ą─įŲ┤µā”╩ŪĘŪ│Ż▀m║ŽĄ─ĪŻ
2.3 ŽĄĮy(t©»ng)╝▄śŗįOėŗ
─┐Ū░ģ^(q©▒)ė“PACS ║═┤¾ą═ßt(y©®)į║╚½į║PACS ═©│Ż▓╔ė├╝»ųą╩Į┤µā”Ż¼┤µā”╝▄śŗ┤¾ČÓ▓╔ė├“į┌ŠĆ- Į³ŠĆ-ļxŠĆ”╚²╝ē┤µā”─Ż╩ĮŻ¼▀@ĘN─Ż╩Į│Żė├ų▒▀B╩Į┤µā”Ż¼┤µā”įOéõų▒Įė┼cų„ÖCŽÓ▀BĮėŻ¼╚▌┴┐öU│õ▓╗ĘĮ▒ŃŻ¼ŠSūo╔²╝ē└¦ļyĪŻ┴Ē═ŌŻ¼ģ^(q©▒)ė“PACS öĄ(sh©┤)ō■(j©┤)╩ŪPB ╝ēĄ─Ż¼ę¬▒ŻūC╦∙ėąöĄ(sh©┤)ō■(j©┤)Ą─┤µā”▒╗Ė▀╦┘īŹĢrįLå¢Ż¼─┐Ū░╝╝ągŽ┬Ż¼ų▒▀B╩Į┤µā”’@╚╗ØMūŃ▓╗┴╦▀@ę¬Ū¾Ż¼╝┤╩╣╩ŪSAN( ┤µā”ģ^(q©▒)ė“ŠW(w©Żng)Įj) ║═NAS( ŠW(w©Żng)Įj▀BĮė╩Į┤µā”) ę▓ļyęįīŹ¼F(xi©żn)ĪŻ─┐Ū░Ą─╝▄śŗŽ┬Ż¼▀hŲ┌ė░Ž±öĄ(sh©┤)ō■(j©┤)ę╗░Ń╩ŪęįļxŠĆĘĮ╩ĮŻ¼═©▀^╣Ō▒PÄņ╗“┤┼ĦÄņĄ─ĘĮ╩Į▒Ż┤µŻ¼īŹĢrįLå¢└¦ļyŻ¼ŽĄĮy(t©»ng)┐╔ė├ąį▓ŅĪŻ
«a╔·▀@ą®å¢Ņ}Ą─Ė∙į┤ų„ę¬╩Ū▓╔ė├┴╦╝»ųą╩Į┤µā”╝▄śŗĪŻßśī”╔Ž╩÷å¢Ņ}Ż¼▓╔ė├╦ĮėąįŲ┤µā”┼c╔╠śI(y©©)įŲ┤µā”ŽÓĮY║ŽĄ─ĘĮ╩ĮŻ¼Ė³Ė─ģ^(q©▒)ė“PACS ╝▄śŗŻ¼īó╝»ųą╩Į┤µā”Ė─×ķĘų▓╝╩Į┤µā”Ż¼╚ź│²“ļxŠĆ”▓┐ĘųŻ¼īó“į┌ŠĆ- Į³ŠĆ- ļxŠĆ”╚²╝ē┤µā”╝▄śŗĖ³Ė─×ķ“į┌ŠĆ- ÜwÖn”Č■╝ē┤µā”╝▄śŗĪŻ“ļxŠĆ”┤µā”Ż¼┐╔ęįėąą¦╠ßĖ▀ŽĄĮy(t©»ng)Ą─┐╔ė├ąįĪŻ▀@śė╝╚┐╔ØMūŃPB ╝ē┤µā”╚▌┴┐Ą─ąĶŪ¾Ż¼ę▓┐╔īŹ¼F(xi©żn)įŁüĒ“ļxŠĆ”öĄ(sh©┤)ō■(j©┤)Ą─īŹĢrįLå¢Ż¼╠ß╔²ŽĄĮy(t©»ng)┐╔ė├ąįĪŻ
ģ^(q©▒)ė“PACSĄ─įŲ┤µā”ŽĄĮy(t©»ng)ęįHadoop ×ķ╗∙ĄA╝▄śŗŻ¼š¹éĆ┐“╝▄ė╔╗∙ė┌HDFS Ą─╬’└ĒīėĪóė├ė┌╠Ä└Ē║═┤µā”ė░Ž±öĄ(sh©┤)ō■(j©┤)Ę■䚥─ųąķgīėĪóš{ė├▀@ą®Ę■䚥─Įė┐┌īėęį╝░Š▀¾wĄ─æ¬ė├īėĮM│╔Ż¼ęŖłD1ĪŻ╬’└ĒīėŻ¼╝┤┤µā”įOéõŠ▀ėą║Ż┴┐Ą─┤µā”╚▌┴┐Ż¼┤µā”╝▄śŗ×ķHDFSŻ¼═©▀^HDFS īŹ¼F(xi©żn)žō▌dŠ∙║ŌĪóöĄ(sh©┤)ō■(j©┤)éõĘ▌Ą╚╣”─▄Ż¼▓óŽ“═Ō╠ß╣®Įy(t©»ng)ę╗Ą─┤µā”įLå¢Įė┐┌ĪŻųąķgīėīŹ¼F(xi©żn)ė░Ž±öĄ(sh©┤)ō■(j©┤)Ą─┤µā”┼cūx╚ĪŻ¼įō╣”─▄═©▀^įLå¢╬’└ĒīėĄ─HDFS ╠ß╣®Ą─Įė┐┌īŹ¼F(xi©żn)ĪŻĮė┐┌īėį┌ųąķgīėĄ─╗∙ĄA╔Žū÷▀Mę╗▓ĮĄ─╣”─▄ĘŌčbŻ¼╩╣ķ_░l(f©Ī)ŠÄ│╠Ė³╚▌ęūĪŻæ¬ė├īėät└¹ė├Įė┐┌īė╠ß╣®Ą─╣”─▄Įė┐┌Ż¼ŠÄīæĘų▓╝╩ĮĄ─▓óąą╠Ä└Ēæ¬ė├│╠ą“ĪŻ
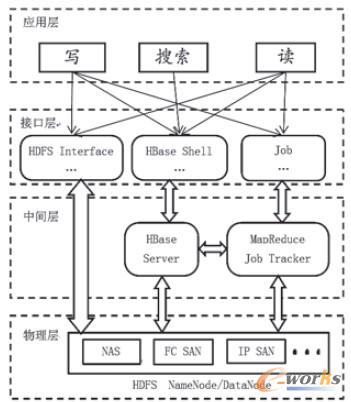
łD1 įŲ┤µā”╝▄śŗ╩ŠęŌłD
2.4 ╗∙ė┌HDFSĄ─╬─╝■╠Ä└Ē
DICOM łDŽ±═©│ŻČ╝╩ŪąĪ╬─╝■Ż¼▌^┤¾Ą─╬─╝■╚ńDRĪóCRę╗░Ń╩Ūį┌10M ūų╣Ø(ji©”)ū¾ėęŻ¼Č°CTĪóMR ╬─╝■ätų╗ėąÄū░┘K ūų╣Ø(ji©”)┤¾ąĪĪŻė╔ė┌HDFS╬─╝■ŽĄĮy(t©»ng)└’─¼šJĄ─öĄ(sh©┤)ō■(j©┤)ēK┤¾ąĪ╩Ū64M ūų╣Ø(ji©”)Ż¼┤µĘ┼Ą─ąĪ╬─╝■╠½ČÓŻ¼īóŽ¹║─┤¾┴┐HDFS ų„╣Ø(ji©”)³cNameNodeā╚┤µŻ¼Å─Č°ĮĄĄ═š¹éĆ╝»╚║ąį─▄ĪŻ┴Ē═ŌŻ¼ė╔ė┌├┐éĆ╬─╝■Ģ■▒╗Å═ųŲ3 Ę▌Ż¼▀^ČÓĄ─ąĪ╬─╝■Ģ■╩╣ąį─▄ĮĄĄ═Ż¼ę“┤╦ąĶę¬Į©┴óę╗éĆ╠Ä└ĒąĪ╬─╝■Ą─│ķŽ¾īėŻ¼ī”├┐éĆ▓Ī╚╦▓╔╝»ĄĮĄ─łDŽ±╬─╝■▀Mąą╠Ä└ĒĪŻī”ė┌įŲ┤µā”ųąąĪ╬─╝■┤µā”┼cįLå¢å¢Ņ}Ż¼┐╔═©▀^ūį▀mæ¬╬─╝■ŽĄĮy(t©»ng)▀Mąąā×(y©Łu)╗»ĪŻßśī”ģ^(q©▒)ė“PACS ė░Ž±╬─╝■ŅÉą═▌^×ķå╬ę╗Ą─╠ž³cŻ¼╠ß│÷┴╦ā╔éĆĮŌøQĘĮ░Ė▀MąąčąŠ┐ĪŻ
Ą┌ę╗éĆĘĮ░Ė╩Ūīó├┐Ę∙łDŽ±┐┤ū„ę╗ļŻ¼░čę╗┤╬Öz▓ķĄ─╦∙ėąłDŽ±║Ž▓ó│╔ę╗éĆą“┴ąłDŽ±╬─╝■ĪŻį┌DICOM╬─╝■ųąŻ¼łDŽ±öĄ(sh©┤)ō■(j©┤)▒Ż┤µį┌Pixel Data öĄ(sh©┤)ō■(j©┤)į¬╦žųąŻ¼╦³Ą─ųĄė“ųą▒Ż┤µĄ─Ž±╦žöĄ(sh©┤)ō■(j©┤)┐╔ęį╩ŪįŁ╩╝öĄ(sh©┤)ō■(j©┤)Ż¼ę▓┐╔ęį╩ŪĮø(j©®ng)▀^ĘŌčbĄ─ĪŻĘŌčbĄ─Ž±╦žöĄ(sh©┤)ō■(j©┤)Ą─ųĄ╩Ūė╔ĘųĖŅķ_Ą─ČÓéĆŽ±╦žöĄ(sh©┤)ō■(j©┤)┴„ĮM│╔Ż¼ęį┤╦üĒ▒Ē╩ŠČÓļĄ─łDŽ±ĪŻ┤╦ĘĮ░Ėꬥ╚╬─╝■Ž┬▌d═Ļ║¾▓┼─▄’@╩ŠŻ¼Č°▓╗╩Ūßt(y©®)╔·╦∙┴ĢæTĄ─▀ģŽ┬▌d▀ģ’@╩ŠŻ¼«ö▓Ī╚╦ę╗┤╬Öz▓ķĄ─łDŽ±║▄ČÓĢr( ╚ńCT łDŽ±Ż¼┐╔▀_╔ŽŪ¦Åł)Ż¼łDŽ±╬─╝■┐é┤¾ąĪ▀_Äū░┘M╔§ų┴GöĄ(sh©┤)┴┐╝ēŻ¼Ž┬▌dĢrķg╔įķLĢ■ūīßt(y©®)╔·ėXĄ├ļyęį╚╠╩▄ĪŻ
Ą┌Č■éĆĘĮ░Ė╩ŪĘųĮMē║┐sĪŻīó▓Ī╚╦Ą─łDŽ±╬─╝■░┤Ųõą“┴ąŻ©Series_noŻ®╠¢╝░ŠÄ╠¢Ż©Instance_noŻ®Ą─Ēśą“▀MąąĘųĮMŻ¼├┐ę╗ĮMĄ─╬─╝■┐é┤¾ąĪ×ķ64Mū¾ėęŻ¼╚╗║¾Ęųäeīó├┐ę╗ĮM╬─╝■ē║┐s│╔ę╗éĆē║┐s╬─╝■▀Mąą┤µā”Ż¼▀@śėį┌Ž┬▌dĄ─Ģr║“Ż¼Ž┬▌dę╗ĮMŠ═ĮŌē║▓ó’@╩ŠŻ¼ęįīŹ¼F(xi©żn)▀ģŽ┬▌d▀ģ’@╩ŠłDŽ±Ą─╣”─▄ĪŻ┤╦ĘĮ░ĖĄ─ā×(y©Łu)³c▀Ćį┌ė┌╦³ī”łDŽ±Ą─ē║┐s╩Į¤oōpŻ¼ē║┐s║¾╬─╝■═©│Ż▓╗ĄĮįŁüĒ╬─╝■┐é┤¾ąĪĄ─1/2Ż¼├„’@Ąž£p╔┘┴╦ŠW(w©Żng)Įjé„▌öĢrķgĪŻ
×ķīŹ¼F(xi©żn)▓ó£yįć▀@ā╔éĆĘĮ░ĖĄ─╣”─▄Ż¼įOėŗ┴╦ę╗╠ūDICOM╬─╝■ūxīæųąķg╝■Ż¼ĘŌčb┴╦Ąūīė▓┘ū„╝Ü╣Ø(ji©”)Ż¼īŹ¼F(xi©żn)DICOM╬─╝■Ą─▓ķįāĪóūx╚Ī║═īæ╚ļĄ╚╣”─▄Ż¼▓ó×ķæ¬ė├īė╠ß╣®Įy(t©»ng)ę╗Ą─Įė┐┌Ż¼┐╔Ė∙ō■(j©┤)┼õų├▀xō±ĘĮ░Ė1╗“ĘĮ░Ė2ĪŻ
3.įŲ┤µā”£yįć╝░Ęų╬÷
3.1 £yįćĘĮĘ©
£yįćįŲ╝▄śŗŽ┬Ą─╬─╝■īæ╚ļ┼cūx╚Ī╦┘Č╚Ż¼ęį╝░╦³éā┼cDataNode ╣Ø(ji©”)³cöĄ(sh©┤)Ą─ĻPŽĄŻ╗═¼Ģr£yįćĘĮ░Ė1┼cĘĮ░Ė2Łh(hu©ón)Š│Ž┬Ż¼▓╗═¼┤¾ąĪė░Ž±╬─╝■Ą─Ž┬▌d▓ó’@╩Šą¦╣¹ĪŻ
ė▓╝■Łh(hu©ón)Š│Ż║▓╔ė├1 ┼_Ę■äšŲ„( ╚A┤T Z8NAD6Ż¼CPU Ż║Intel Xeon E5504 Ż╗ā╚┤µŻ║8GB DDR3Ż®┼cŲš═©PC ÖC5 ┼_( ┬ō(li©ón)Žļåó╠ņM488EŻ¼CPU Ż║E2180 2.0GHzŻ¼ā╚┤µ1GB) ▀Mąą─ŻöM蹊┐ĪŻŲš═©PC ÖC▀\ąąDataNodeŻ¼ŠW(w©Żng)Įj╩Ūā╚▓┐Šųė“ŠW(w©Żng)Īó100M ŠW(w©Żng)┐┌ĪŻŲõųąŻ¼Ę■äšŲ„Ą─╣”─▄╩ŪŻ║Įė╩šÅ─įOéõ╗“ßt(y©®)╔·╣żū„šŠé„üĒĄ─DICOM ╬─╝■Ż╗į┌▓Ī╚╦╔┘Ą─ķeĢrļAČ╬Ż©═Ē╔ŽĢrķgŻ¼┐╔ęįūįąąįOČ©Ż®Ż¼└¹ė├Ū░╩÷Ą─ųąķg╝■╠Ä└Ē«ö╠ņĮė╩šĄ─DICOM ╬─╝■Ż¼▓ó░l(f©Ī)╦═ĄĮįŲ┤µā”Ż╗Įė╩šßt(y©®)╔·╣żū„šŠŽ┬▌dDICOM ╬─╝■šłŪ¾Ż¼╚ń╣¹▒ŠĄžėąįō╬─╝■Ż¼ätÅ─▒ŠĄž░l(f©Ī)╦═ĄĮßt(y©®)╔·╣żū„šŠŻ¼╚ń╣¹▒ŠĄžø]ėąŻ¼ätÅ─įŲ┤µā”▓ķįā▓óŽ┬▌d╬─╝■Ż¼░l(f©Ī)╦═ĄĮßt(y©®)╔·╣żū„šŠĪŻ
ŽĄĮy(t©»ng)▄ø╝■Łh(hu©ón)Š│Ż║Ę■äšŲ„▓┘ū„ŽĄĮy(t©»ng)Windows2008Ż¼öĄ(sh©┤)ō■(j©┤)Äņė├Oracle10gŻ¼įŲ┤µā”╬─╝■ŽĄĮy(t©»ng)╩ŪHadoop-HDFS 0.20.1Ż¼į┌├┐ę╗┼_ÖC╔ŽŠ∙░▓čb▓ó┼õų├JDK Łh(hu©ón)Š│Ż©░µ▒Š1.6Ż®ĪŻ
3.2 £yįćĮY╣¹╝░Ęų╬÷
£yįć▓╗═¼DataNode Ą─ūxīæ╦┘Č╚Īó£yįćĮY╣¹Ż¼ęŖ▒Ē1ĪŻ
▒Ē1 ╬─╝■ūxīæ╦┘Č╚(MB/s)
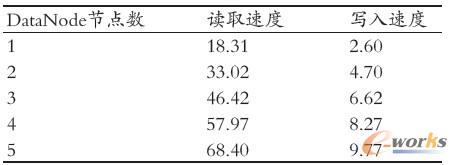
Å─£yįćĮY╣¹┐╔ęį┐┤│÷Ż¼ļSų°DataNode ╣Ø(ji©”)³cöĄ(sh©┤)į÷╝ėŻ¼ūx╚Ī╦┘Č╚ŽÓæ¬į÷╝ėŻ¼╗∙▒Š╩Ū┼cClient öĄ(sh©┤)┴┐ŠĆąįŽÓĻPĄ─ĪŻ▀@╩Ūė╔ė┌Hadoop ųąĄ─öĄ(sh©┤)ō■(j©┤)ēK╩Ū▒M┐╔─▄Š∙ä“Ęų▓╝į┌Ė„DataNode
╣Ø(ji©”)³cųąĄ─Ż¼ūx╚Ī╬─╝■Ģr┐╔ęįŠ█║ŽĖ„DataNode ╣Ø(ji©”)³cĄ─ŠW(w©Żng)ĮjĦīÆŻ¼ļSų°DataNode öĄ(sh©┤)┴┐Ą─į÷┤¾Ż¼Ųõ┐éĦīÆę▓┤¾┤¾į÷╝ėĪŻ
Å─£yįćĮY╣¹ę▓┐╔┐┤│÷Ż¼Hadoop Ą─īæ╚ļ╦┘Č╚├„’@▓Ņė┌ūx╚Ī╦┘Č╚Ż¼▀@┼cHDFS Ą─╣żū„įŁ└ĒėąĻPŻ¼ę“×ķīæ╚ļę╗éĆ╬─╝■ę¬═¼Ģrū÷3 éĆéõĘ▌ĪŻĄ½ļSų°DataNode ╣Ø(ji©”)³cöĄ(sh©┤)┴┐Ą─į÷╝ėŻ¼īæ╚ļ╦┘┬╩ę▓ŽÓæ¬į÷┤¾Ż¼╗∙▒Š╔Ž┼cDataNode ╣Ø(ji©”)³c│╔ŠĆąįĻPŽĄĪŻ
ęį─│▓Ī╚╦Ą─CT Öz▓ķ×ķ└²Ż¼╣▓ėą2185 Ę∙łDŽ±Ż¼╬─╝■┐é┤¾ąĪ×ķ1.15 GĪŻį┌ĘĮ░Ė1ųąŻ¼╔·│╔┴╦ę╗éĆ1.16 G ┤¾ąĪĄ─DICOM ą“┴ąłDŽ±╬─╝■Ż╗į┌ĘĮ░Ė2 ųąŻ¼╔·│╔┴╦53 éĆē║┐s╬─╝■Ż¼├┐éĆ╬─╝■┤¾ąĪį┌17ŻŁ25 MBŻ¼ŲĮŠ∙21.7 MBĪŻ£yįć▀^│╠ųąėøõø╦∙ėąē║┐s╬─╝■Ą─īæ╚ļ/ ūx╚Ī┐éĢrķgŻ¼į┘ĘųäeŪ¾ŲĮŠ∙ųĄĪŻ£yįćĮY╣¹ęŖ▒Ē2Ż©ĘĮ░Ė2 Ą─öĄ(sh©┤)ō■(j©┤)ųąŻ¼ą▒Ė▄“/”Ū░├µ╩Ū╦∙ėą
ē║┐s╬─╝■Ą─┐éūx╚ĪĢrķgŻ¼║¾├µ╩Ū├┐éĆē║┐s╬─╝■Ą─ŲĮŠ∙ūx╚ĪĢrķg)ĪŻ
▒Ē2 ūx╚ĪĢrķg(s)
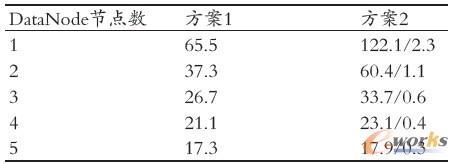
Å─▒Ē2┐╔┐┤│÷Ż¼ļSų°DataNode ╣Ø(ji©”)³cöĄ(sh©┤)į÷╝ėŻ¼╠Ä└ĒĢrķg┤¾┤¾┐sČ╠Ż¼▀@┼cŪ░├µĮY╣¹ę╗ų┬ĪŻĘĮ░Ė2 Ą─┐é╠Ä└ĒĢrķgŠ∙▒╚ĘĮ░Ė1ķLŻ¼▀@╩Ūę“×ķĘĮ░Ė1ų╗ąĶ1┤╬ŠW(w©Żng)Įj▀BĮėšłŪ¾Ż¼Č°ĘĮ░Ė2 ätąĶ53┤╬ĪŻĄ½į┌ĘĮ░Ė1ųąŻ¼ßt(y©®)╔·ų┴╔┘ąĶę¬17.3s▓┼─▄┐┤ĄĮłDŽ±Ż¼Č°ĘĮ░Ė2ųąŻ¼ūŅČÓąĶ2.3sŠ═─▄┐┤ĄĮłDŽ±Ż¼ūŅ╔┘āH0.3sŠ═─▄┐┤ĄĮĪŻ
┴Ē═ŌŻ¼į┌ĘĮ░Ė2ųąŻ¼ē║┐s╬─╝■ŲĮŠ∙┤¾ąĪ×ķ21.7MBŻ¼ļxHDFS ─¼šJĄ─64MBöĄ(sh©┤)ō■(j©┤)ēK┤¾ąĪėą▓╗ąĪ▓ŅŠÓŻ¼▀@╚įĢ■į┌ę╗Č©│╠Č╚╔Žį÷╝ėNameNodeĘ■äšŲ„ā╚┤µŽ¹║─Ż¼ę“┤╦ē║┐s╠Ä└Ē╦ŃĘ©ąĶę¬Ė─▀MŻ¼īó┼ąöÓē║┐sŪ░Ą─╬─╝■┐é┤¾ąĪ▓╗│¼▀^64MBŻ¼Ė─×ķ┼ąöÓē║┐s╠Ä└Ē║¾Ą─╬─╝■┤¾ąĪ▓╗│¼▀^64 MBŻ¼▀@ąĶę¬į┌║¾└m(x©┤)蹊┐ųąĖ─▀MĪŻ
4.ĮY╩°šZ
įŲ┤µā”╩Ū─┐Ū░Ą─ę╗éĆæ¬ė├蹊┐¤ß³cĪŻįŲ┤µā”Ę■äš×ķģ^(q©▒)ė“PACS ė░Ž±╬─╝■Ą─┤µā”å¢Ņ}╠ß╣®┴╦ėąą¦Ą─ĮŌøQĘĮ░ĖŻ¼ėąą¦ĮŌøQ┴╦śŗĮ©ģ^(q©▒)ė“ßt(y©®)īWė░Ž±öĄ(sh©┤)ō■(j©┤)ųąą─Ą─│╔▒ŠĖ▀Īó┐╔öUš╣ąį▓ŅĪóé„▌öĦīÆ▓╗ūŃĪóļxŠĆöĄ(sh©┤)ō■(j©┤)┐╔ė├ąį▓ŅĄ╚å¢Ņ}Ż¼═¼Ģr£pĄ═┴╦═Č╚ļŻ¼╣Ø(ji©”)╝s│╔▒ŠĪŻ▒Š╬─śŗĮ©┴╦ę╗éĆęįHadoop ╝▄śŗ×ķ╗∙ĄAĄ─įŲ┤µā”Ę■䚎ĄĮy(t©»ng)Ż¼ßśī”HDFS▓╗▀m║ŽCTĪóMRI Ą╚ąĪ╬─╝■Ą─┤µā”Ą─å¢Ņ}Ż¼ķ_░l(f©Ī)┴╦ę╗╠ūųąķg╝■Ż¼ė├ė┌īóąĪ╬─╝■║Ž▓ó×ķ┤¾╬─╝■Ż¼╩╣Ųõ▀mæ¬HDFSĄ─┤µā”╠ž³cĪŻ£yįćĮY╣¹▒Ē├„Ż¼ęįHadoop ×ķ╗∙ĄA╝▄śŗĄ─įŲ┤µā”ŲĮ┼_ļSų°DataNode ╣Ø(ji©”)³cį÷ČÓŻ¼ąį─▄Į³╦ŲŠĆąįį÷╝ėĪŻ═¼Ģr▀Ć蹊┐┴╦╬─╝■┤¾ąĪī”ė┌┐═æ¶Č╦ūx╚Ī▓ó’@╩ŠłDŽ±ą¦╣¹Ą─ė░ĒæŻ¼ĮY╣¹▒Ē├„å╬╝āĄžīó▓Ī╚╦ę╗┤╬Öz▓ķłDŽ±║Ž▓ó×ķę╗éĆ┤¾╬─╝■╩Ū▓╗┐╔╚ĪĄ─Ż¼æ¬«ö┐╝æ]ĄĮŠW(w©Żng)ĮjŽ┬▌d╦┘Č╚ęį╝░į\öÓßt(y©®)╔·ė^ĖąŻ¼├┐éĆ╬─╝■ęį▓╗│¼▀^64MB×ķę╦ĪŻŽ┬ę╗▓ĮĄ─蹊┐╣żū„╩Ūī”ųąķg╝■╣”─▄▀Mę╗▓Į═Ļ╔ŲŻ¼▓ó蹊┐ģ^(q©▒)ė“PACSįŲ┤µā”ŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)░▓╚½┼c╝ė├▄ÖCųŲŻ¼┤_▒Żßt(y©®)į║╝░▓Ī╚╦Ą─ŽÓĻPļ[╦Į╝░öĄ(sh©┤)ō■(j©┤)░▓╚½ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äšŅIė“ĪóąąśI(y©©)æ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻPūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.hanmeixuan.com/
▒Š╬─ś╦Ņ}Ż║╗∙ė┌HadoopĄ─įŲ╝▄śŗģ^(q©▒)ė“PACS┤µā”ĘĮ░ĖįOėŗ
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.hanmeixuan.com/html/support/11121511595.html



▀xą═ųąą─")
¾w“×ųąą─")
«aŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")