Į³─ĻüĒŻ¼įŲ┤µā”ęč│╔×ķ┤µā”ąąśI(y©©)╬┤üĒ░l(f©Ī)š╣ūŅ×ķ├„└╩Ą─ĘĮŽ“ų«ę╗Ż¼╦³╩Ūį┌įŲėŗ(j©¼)╦ŃĄ─╗∙ĄA(ch©│)ų«╔ŽĄ─čė╔ņ║═░l(f©Ī)š╣Ż¼╩Ūę╗éĆ(g©©)ęįöĄ(sh©┤)ō■(j©┤)┤µā”║═╣▄└Ē×ķ║╦ą─Ą─įŲėŗ(j©¼)╦ŃŽĄĮy(t©»ng)ĪŻ║Ż┴┐öĄ(sh©┤)ō■(j©┤)Ą─ųĖöĄ(sh©┤)į÷ķLęč│╔×ķ¼F(xi©żn)īŹ(sh©¬)Ż¼Ė∙ō■(j©┤)IDC Ż©Internet Data CenterŻ¼ ╗ź┬ō(li©ón)ŠW(w©Żng)öĄ(sh©┤)ō■(j©┤)ųąą─Ż® Ą─ūŅą┬Įy(t©»ng)ėŗ(j©¼)ĮY(ji©”)╣¹’@╩ŠŻ¼ĄĮ2012 ─ĻĄūŻ¼ ╚½Ū“öĄ(sh©┤)ō■(j©┤)┐é┴┐īó▀_(d©ó)ĄĮ2.7 ZBŻ¼ĄĮ2015─Ļīó▀_(d©ó)ĄĮ8 ZBĪŻ¹£┐ŽÕaĄ─蹊┐ł¾(b©żo)ĖµųĖ│÷Ż¼┤¾┴┐Ą─öĄ(sh©┤)ō■(j©┤)ęčĮø(j©®ng)ØB═ĖĄĮ├┐ę╗éĆ(g©©)ąąśI(y©©)║═śI(y©©)äš(w©┤)┬Ü─▄ŅI(l©½ng)ė“Ż¼ųØu│╔×ķųžę¬Ą─╔·«a(ch©Żn)ę¬╦žĪŻ─┐Ū░Ż¼ é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)┤µā”Ą─öU(ku©░)š╣ąį▓╗╝čŻ¼ īæ╚╦öĄ(sh©┤)ō■(j©┤)Ą─╦┘Č╚▀h(yu©Żn)▀h(yu©Żn)Ą═ė┌öĄ(sh©┤)ō■(j©┤)«a(ch©Żn)╔·Ą─╦┘Č╚ĪŻ
ė┌╩ŪįŲėŗ(j©¼)╦Ń╝╝ąg(sh©┤)æ¬(y©®ng)ė├Č°╔·Ż¼HadoopįŲėŗ(j©¼)╦ŃŲĮ┼_╩ŪApacheŲņŽ┬Ą─ę╗éĆ(g©©)ķ_į┤Ęų▓╝╩Įėŗ(j©¼)╦ŃĒŚ(xi©żng)─┐Ż¼ėąą¦Ą─ĮŌøQ┴╦╔Ž╩÷å¢Ņ}ĪŻHadoopį┌┐╔╔Ļ┐sąįĪóĮĪēčąįĪóėŗ(j©¼)╦Ńąį─▄║═│╔▒Š╔ŽŠ▀ėą├„’@Ą─ā×(y©Łu)ä▌Ż¼ęč│╔×ķ«ö(d©Īng)Ū░╗ź┬ō(li©ón)ŠW(w©Żng)Ų¾śI(y©©)ų„┴„Ą─┤¾öĄ(sh©┤)ō■(j©┤)┤µā”║═Ęų╬÷ŲĮ┼_ĪŻŅA(y©┤)ėŗ(j©¼)Ż¼į┌╬┤üĒ5─Ļā╚(n©©i)īóėą50%Ą─┤¾öĄ(sh©┤)ō■(j©┤)ĒŚ(xi©żng)─┐Ģ■(hu©¼)į┌Hadoop Ą─┐“╝▄╔Ž▀\(y©┤n)ąąĪŻįō╬─į┌Hadoop įŲėŗ(j©¼)╦ŃŲĮ┼_×ķ╗∙ĄA(ch©│)╔ŽŻ¼“×(y©żn)ūC┴╦Hadoop├µī”║Ż┴┐öĄ(sh©┤)ō■(j©┤)Ą─╠Ä└Ē─▄┴”Ż¼ęį╝░įO(sh©©)ėŗ(j©¼)▓óīŹ(sh©¬)¼F(xi©żn)┴╦╗∙ė┌hadoopĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ą─ScoolįŲ┤µā”╬─╝■╣▄└ĒŽĄĮy(t©»ng)ĪŻ
1 įŲ┤µā”ŲĮ┼_
įŲ┤µā”Ą─īŹ(sh©¬)¼F(xi©żn)ę¬ęįČÓĘN╝╝ąg(sh©┤)Ą─░l(f©Ī)š╣×ķŪ░╠߯¼▒╚╚ńīÆĦŠW(w©Żng)Įj(lu©░)Ą─░l(f©Ī)š╣ĪóWEB2.0╝╝ąg(sh©┤)Īóæ¬(y©®ng)ė├┤µā”Ą─░l(f©Ī)š╣Īó╝»╚║╝╝ąg(sh©┤)ĪóŠW(w©Żng)Ė±╝╝ąg(sh©┤)ĪóĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)ĪóCDNā╚(n©©i)╚▌Ęų░l(f©Ī)ĪóP2P╝╝ąg(sh©┤)ĪóöĄ(sh©┤)ō■(j©┤)ē║┐s╝╝ąg(sh©┤)ĪóųžÅ═(f©┤)öĄ(sh©┤)ō■(j©┤)äh│²╝╝ąg(sh©┤)ĪóöĄ(sh©┤)ō■(j©┤)╝ė├▄╝╝ąg(sh©┤)Īó┤µā”╠ōöM╗»╝╝ąg(sh©┤)Īó┤µā”ŠW(w©Żng)Įj(lu©░)╗»╣▄└Ē╝╝ąg(sh©┤)ĪŻ║Ż┴┐öĄ(sh©┤)ō■(j©┤)Ą─┐╔╣▄└ĒąįĪó┐╔öU(ku©░)š╣ąįĪó┐╔┐┐ąįĪó┐é¾w│╔▒ŠŻ©TCOŻ®Īóęį╝░╚▌┴┐öU(ku©░)š╣ąįīóūŅĮKøQČ©įŲ┤µā”╬┤üĒ░l(f©Ī)š╣ą╬╩ĮĪŻ╦∙ėąįŲ┤µā”ŽĄĮy(t©»ng)æ¬(y©®ng)Š▀ėąė▓╝■╚▀ėÓĪóūįäė(d©░ng)Ą─╣╩šŽŪąōQĪó┤µā”įO(sh©©)éõ╔²╝ē▓╗Ģ■(hu©¼)ī¦(d©Żo)ų┬Ę■äš(w©┤)ųąöÓĪó╚▌┴┐Ęų┼õ▓╗╩▄╬’└Ēė▓▒PŽ▐ųŲĪó╣Ø(ji©”)╩ĪļŖ┴”Īó╝░Ģr(sh©¬)╠ß╣®╚▌┴┐Ą─öU(ku©░)š╣Īó║Ż┴┐▓óąąöU(ku©░)╚▌ĪóĮy(t©»ng)ę╗Ą─ī”═Ō├¹ĘQĪóžō(f©┤)▌dŠ∙║ŌĪó╚▌ęū╣▄└ĒĄ╚ā×(y©Łu)³c(di©Żn)ĪŻ
1.1 įŲ┤µā”Ą─╠žąį
«Éśŗ(g©░u)ąįŻ║╩ŪųĖįŲ┤µā”ŽĄĮy(t©»ng)─▄ē“╝µ╚▌▓╗═¼Ą─┤µā”įO(sh©©)éõĪóŠW(w©Żng)Įj(lu©░)▓Ņ«ÉĪó▓╗═¼Ą─▓┘ū„ŽĄĮy(t©»ng)ĪóĖ„ĘNėŗ(j©¼)╦ŃÖC(j©®)ė▓╝■║═▓╗═¼ŠÄ│╠šZčįĪŻ
Ęų▓╝ąįŻ║╩ŪųĖå╬ę╗Ą─öĄ(sh©┤)ō■(j©┤)ųąą─┤µā”─Ż╩Į¤oĘ©ØMūŃ¼F(xi©żn)ėąė├æ¶į┌öĄ(sh©┤)ō■(j©┤)įLå¢ą¦┬╩ĪóöĄ(sh©┤)ō■(j©┤)┐╔┐┐ąį║═ŽĄĮy(t©»ng)žō(f©┤)▌dŠ∙║ŌĘĮ├µĄ─ąĶŪ¾Ż¼įŲ┤µā”ŲĮ┼_Ą─┤µā”┘Yį┤│žųąīó░³║¼ČÓéĆ(g©©)Ąž└Ē╬╗ų├Ęų▓╝Ą─öĄ(sh©┤)ō■(j©┤)ųąą─ė├üĒ▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)╚▀ėÓ║═žō(f©┤)▌dŠ∙║ŌĪŻ
öU(ku©░)š╣ąįŻ║╩ŪųĖįŲ┤µā”ŽĄĮy(t©»ng)┐╔ęį║åå╬Ė▀ą¦Ą─×ķ┤µā”┐šķgöU(ku©░)╚▌Ż¼┤µā”╣Ø(ji©”)³c(di©Żn)Ą─╝ė╚ļ║══╦│÷▒žĒÜęį¤ß▓Õ░╬Ą─ĘĮ╩Į▀M(j©¼n)ąąĪŻ
═Ė├„ąįŻ║╩ŪųĖ░³└©┤µā”╬╗ų├═Ė├„║═ė├æ¶įLå¢═Ė├„Ż¼ė├æ¶▓╗ąĶę¬ĻP(gu©Īn)ą─öĄ(sh©┤)ō■(j©┤)┤µā”Ą─Š▀¾w╬╗ų├Ż¼Š═─▄ē“Š═Į³įLå¢ĄĮöĄ(sh©┤)ō■(j©┤)Ą─Ė▒▒ŠŻ¼ī”ė┌ė├æ¶Č°čįŻ¼öĄ(sh©┤)ō■(j©┤)┐é╩Ū┐╔ė├Ą─ĪŻ
▓ó░l(f©Ī)ąįŻ║╩ŪųĖįŲ┤µā”ŽĄĮy(t©»ng)ųąČÓéĆ(g©©)ė├æ¶┐╔─▄Ģ■(hu©¼)═¼Ģr(sh©¬)ī”╣▓ŽĒöĄ(sh©┤)ō■(j©┤)┘Yį┤░l(f©Ī)│÷šłŪ¾Ż¼├┐éĆ(g©©)įŲ┤µā”ĮM╝■▒žĒÜ▒╗įO(sh©©)ėŗ(j©¼)│╔į┌▓ó░l(f©Ī)Łh(hu©ón)Š│ųą╩Ū░▓╚½Ą─ĪŻ
┐╔┐┐ąįŻ║╩ŪųĖ╚╬ę╗▀M(j©¼n)│╠Īóėŗ(j©¼)╦ŃÖC(j©®)║═ŠW(w©Żng)Įj(lu©░)Č╝ėą┐╔─▄¬Ü(d©▓)┴óĄ─░l(f©Ī)╔·╣╩šŽŻ¼ę“┤╦├┐éĆ(g©©)įŲ┤µā”ĮM╝■ąĶę¬ŪÕ│■╦∙ę└┘ćĄ─ĮM╝■┐╔─▄│÷¼F(xi©żn)╣╩šŽĄ─ĘĮ╩ĮŻ¼ĮM╝■ę¬įO(sh©©)ėŗ(j©¼)│╔─▄▀m«ö(d©Īng)?sh©┤)─╠Ä└Ē├┐éĆ(g©©)╣╩šŽĪŻ
ą¦┬╩Ż║╩ŪųĖė├æ¶įLå¢įŲ┤µā”ŽĄĮy(t©»ng)ųą╣▓ŽĒöĄ(sh©┤)ō■(j©┤)Ą─╦ŃĘ©æ¬(y©®ng)įō▒▄├Ōąį─▄Ų┐ŅiŻ¼ŅlĘ▒įLå¢Ą─öĄ(sh©┤)ō■(j©┤)ąĶę¬Å═(f©┤)ųŲĖ³ČÓĄ─Ė▒▒ŠŻ¼ė├æ¶─▄ē“Š═Į³½@Ą├ūŅ┐ņĄ─įLå¢Ģr(sh©¬)ķgŻ¼═¼Ģr(sh©¬)ė├æ¶╩╣ė├įŲ┤µā”Ę■äš(w©┤)Ą─Įė┐┌æ¬(y©®ng)įō▒M┐╔─▄║åå╬ĪŻ
2 įŲ┤µā”Ą─ĮY(ji©”)śŗ(g©░u)─Żą═
įŲ┤µā”╩Ūęį┤µā”įO(sh©©)éõ×ķ║╦ą─Ż¼ŠC║Ž┴╦ČÓĘNĖ▀ą┬ėŗ(j©¼)ąg(sh©┤)śŗ(g©░u)│╔Ą─Å═(f©┤)ļsŽĄĮy(t©»ng)ĪŻ╦³═©▀^æ¬(y©®ng)ė├▄ø╝■üĒī”═ŌĮńė├æ¶╠ß╣®Įy(t©»ng)ę╗Ą─Ę■äš(w©┤)ĪŻŲõĮY(ji©”)śŗ(g©░u)─Żą═ė╔ęįŽ┬╦─īėĮM│╔ĪŻ
2.1 ┤µā”īė
┤µā”īė╩ŪįŲ┤µā”ųąūŅ×ķ╗∙ĄA(ch©│)Ą─▓┐ĘųŻ¼ ═¼Ģr(sh©¬)ę▓╩ŪįŲ┤µā”Ą─ĄūīėĪŻįŲ┤µā”═©▀^╗ź┬ō(li©ón)ŠW(w©Żng)Īó╣Ō└w═©Ą└ŠW(w©Żng)Įj(lu©░)Ą╚Ż¼īó┤¾┴┐Ą─▓╗═¼ŅÉą═ŪęĘų▓╝į┌▓╗═¼Ąž└Ē╬╗ų├Ą─┤µā”įO(sh©©)éõ▀BĮėį┌ę╗ŲŻ¼īŹ(sh©¬)¼F(xi©żn)║Ż┴┐öĄ(sh©┤)ō■(j©┤)Ą─Įy(t©»ng)ę╗┤µā”ĪŻ═¼Ģr(sh©¬)īŹ(sh©¬)¼F(xi©żn)ī”┤µā”įO(sh©©)éõĄ─╝»ųą╣▄└ĒĪóĀŅæB(t©żi)▒O(ji©Īn)┐žęį╝░╚▌┴┐Ą─äė(d©░ng)æB(t©żi)öU(ku©░)š╣ĪŻīŹ(sh©¬)┘|(zh©¼)╔ŽŻ¼▀@Š═╩Ūę╗ĘN├µŽ“Ę■äš(w©┤)Ą─Ęų▓╝╩Į┤µā”ŽĄĮy(t©»ng)ĪŻ
2.2 ╗∙ĄA(ch©│)╣▄└Ēīė
╗∙ĄA(ch©│)╣▄└Ēīėį┌įŲ┤µā”ŽĄĮy(t©»ng)ųą╩ŪūŅļyīŹ(sh©¬)¼F(xi©żn)Ą─▓┐ĘųŻ¼ę▓╩ŪįŲ┤µā”ųąūŅ×ķ║╦ą─Ą─ę╗īėĪŻįō╗∙ĄA(ch©│)╣▄└Ēīėų„ę¬æ¬(y©®ng)ė├╝»╚║ĪóĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Īó╠ōöM╗»Ą╚╝╝ąg(sh©┤)üĒīŹ(sh©¬)¼F(xi©żn)įŲ┤µā”ŽĄĮy(t©»ng)ųąČÓéĆ(g©©)┤µā”įO(sh©©)éõų«ķgĄ─ģf(xi©”)═¼╣żū„Ż¼╩╣Ą├▀@ą®▓╗═¼įO(sh©©)éõ─▄ē“├µŽ“ė├æ¶╠ß╣®ę╗ų┬Ą─Ę■äš(w©┤)ĪŻ×ķ┴╦▒Żūo(h©┤)ė├æ¶öĄ(sh©┤)ō■(j©┤)Ą─░▓╚½ąį║═╦Į├▄ąįŻ¼ įŲ┤µā”╩╣ė├┴╦öĄ(sh©┤)ō■(j©┤)╝ė├▄╝╝ąg(sh©┤)Īóā╚(n©©i)╚▌Ęų░l(f©Ī)╝╝ąg(sh©┤)ĪóöĄ(sh©┤)ō■(j©┤)éõĘ▌║═╚▌×─(z©Īi)Ą╚╝╝ąg(sh©┤)üĒ▒ŻūCė├æ¶Ą─öĄ(sh©┤)ō■(j©┤)▓╗▒╗Ė`╚ĪĪóą╣├▄╗“üG╩¦ĪŻ═©▀^įO(sh©©)ėŗ(j©¼)Įy(t©»ng)ę╗Ą─ė├æ¶╣▄└ĒĪó░▓╚½╣▄└ĒĪóĖ▒▒Š╣▄└Ē╝░▓▀┬į╣▄└ĒĄ╚╣½╣▓öĄ(sh©┤)ō■(j©┤)╣▄└Ē╣”─▄Ż¼īóĄūīė┤µā”┼c╔Žīėæ¬(y©®ng)ė├¤o┐pŃĢĮėŲüĒŻ¼ īŹ(sh©¬)¼F(xi©żn)ČÓ┤µā”įO(sh©©)éõų«ķgĄ─ģf(xi©”)═¼╣żū„Ż¼ęįĖ³║├Ą─ąį─▄ī”═Ō╠ß╣®ČÓĘNĘ■äš(w©┤)ĪŻ
2.3 æ¬(y©®ng)ė├Įė┐┌īė
æ¬(y©®ng)ė├Įė┐┌īė╩ŪįŲ┤µā”ųąūŅņ`╗ŅČÓūāĄ─▓┐ĘųĪŻįŲ┤µā”Ę■äš(w©┤)╔╠Ė∙ō■(j©┤)īŹ(sh©¬)ļHśI(y©©)äš(w©┤)ąĶŪ¾Ż¼┐╔ęįķ_░l(f©Ī)▀h(yu©Żn)│╠öĄ(sh©┤)ō■(j©┤)éõĘ▌ĪóęĢŅl³c(di©Żn)▓źŲĮ┼_Ą╚▓╗═¼ŅÉą═Ą─Ę■äš(w©┤)Įė┐┌Ż¼×ķė├æ¶╠ß╣®ŽÓæ¬(y©®ng)Ą─æ¬(y©®ng)ė├Ę■äš(w©┤)ĪŻæ¬(y©®ng)ė├Įė┐┌īė╩ŪįŲ┤µā”ŲĮ┼_ųą┐╔ęįņ`╗ŅöU(ku©░)š╣Ą─Īóų▒Įė├µŽ“ė├æ¶Ą─▓┐ĘųĪŻĖ∙ō■(j©┤)ė├æ¶ąĶŪ¾Ż¼įŲ┤µā”┐╔ęįķ_░l(f©Ī)│÷▓╗═¼Ą─æ¬(y©®ng)ė├Įė┐┌Ż¼╠ß╣®ŽÓæ¬(y©®ng)Ą─Ę■äš(w©┤)Ż¼└²╚ńöĄ(sh©┤)ō■(j©┤)┤µā”Ę■äš(w©┤)Īó┐šķgūŌ┘UĘ■äš(w©┤)Īó╣½╣▓┘Yį┤Ę■äš(w©┤)ĪóČÓė├æ¶öĄ(sh©┤)ō■(j©┤)╣▓ŽĒĘ■äš(w©┤)ĪóöĄ(sh©┤)ō■(j©┤)éõĘ▌Ę■äš(w©┤)Ą╚ĪŻ
2.4 įLå¢īė
įLå¢īė╩ŪįŲ┤µā”ųąę¬Ū¾ų╗ėąĮø(j©®ng)▀^╩┌ÖÓ(qu©ón)Ą─ė├æ¶▓┼┐╔ęį═©▀^ś╦(bi©Īo)£╩(zh©│n)Ą─æ¬(y©®ng)ė├Įė┐┌ĄŪĻæŽĄĮy(t©»ng)Ż¼▓┼─▄ŽĒė├└’├µĄ─Ė„ĒŚ(xi©żng)Ę■äš(w©┤)ĪŻĄ½╩ŪĘ■äš(w©┤)╔╠╦∙╠ß╣®Ą─įLå¢╩ųČ╬║═įLå¢ŅÉą═ę“▓╔ė├Ą─╩ųČ╬▓╗═¼Č°▓╗═¼Ż¼Ą½╩Ū═©▀^öĄ(sh©┤)ō■(j©┤)įLå¢īėĄ─įÆŻ¼╚╬║╬ę╗éĆ(g©©)╩┌ÖÓ(qu©ón)ė├æ¶Č╝┐╔ęįį┌╚╬║╬ĄžĘĮŻ¼╩╣ė├╚╬ęŌę╗┼_┬ō(li©ón)ŠW(w©Żng)Ą─ĮKČ╦įO(sh©©)éõŻ¼░┤ššś╦(bi©Īo)£╩(zh©│n)Ą─╣½ė├æ¬(y©®ng)ė├Įė┐┌üĒĄŪõøįŲ┤µā”ŲĮ┼_Ż¼ŽĒ╩▄įŲ┤µā”Ę■äš(w©┤)ĪŻ
3 ▓┐╩įŲŲĮ┼_
3.1 Hadoop
Hadoop╩ŪApacheŲņŽ┬Ą─ę╗éĆ(g©©)ķ_į┤ĒŚ(xi©żng)─┐Ż¼ė├üĒų¦│ų?j©½n)?sh©┤)ō■(j©┤)├▄╝»ą═Ą─Ęų▓╝╩Įæ¬(y©®ng)ė├Ż¼─▄ē“ų¦│ų╔ŽŪ¦╣Ø(ji©”)³c(di©Żn)ęį╝░║Ż┴┐Ż©PB ╝ēŻ®öĄ(sh©┤)ō■(j©┤)┴┐Ą─▀\(y©┤n)╦ŃĪŻHadoop ų„ę¬ė╔ā╔▓┐Ęųśŗ(g©░u)│╔Ż║Hadoop Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ż©HDFS[6]Ż®║═į┌HDFS╔ŽĄ─MapReduce [7]ŠÄ│╠─Żą═īŹ(sh©¬)¼F(xi©żn)ĪŻ
3.1.1 HDFSĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)
HDFS╩ŪGoogle GFSĄ─ķ_į┤░µ▒ŠĄ─īŹ(sh©¬)¼F(xi©żn)Ż¼ū„×ķę╗éĆ(g©©)Ė▀Č╚╚▌Õe(cu©░)Ą─Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ż¼╦³─▄ē“╠ß╣®Ė▀═╠═┬┴┐Ą─öĄ(sh©┤)ō■(j©┤)įLå¢Ż¼▀m║Ž┤µā”║Ż┴┐Ą─┤¾öĄ(sh©┤)ō■(j©┤)╬─╝■Ż¼į┌▄ø╝■īėā╚(n©©i)ų├öĄ(sh©┤)ō■(j©┤)╚▌Õe(cu©░)─▄┴”Ż¼┐╔æ¬(y©®ng)ė├ė┌įŲ┤µā”ŽĄĮy(t©»ng)Ą─┤ŅĮ©┼cķ_░l(f©Ī)Ż¼║═¼F(xi©żn)ėąĄ─Ęų▓╝╩ĮŽĄĮy(t©»ng)ūŅ┤¾Ą─▓╗═¼³c(di©Żn)į┌ė┌Ė▀╚▌Õe(cu©░)ąįĪóęūöU(ku©░)š╣║═Ą═│╔▒ŠĪŻ
HDFS╩Ū┐╔ęį▀\(y©┤n)ąąį┌Ųš═©ė▓╝■╔ŽĄ─Ęų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ż¼▓╔ė├ų„/ģ▓Ż©Master/SlaveŻ®ĮY(ji©”)śŗ(g©░u)ĪŻŲõųąNameNodeų„꬞ō(f©┤)ž¤(z©”)ŠSūo(h©┤)╝»╚║ā╚(n©©i)Ą─į¬öĄ(sh©┤)ō■(j©┤)Ż¼╦∙ėąēKĄ─į¬öĄ(sh©┤)ō■(j©┤)Č╝▒╗ūóāįį┌NameNodeŻ¼ī”═Ō╠ß╣®äō(chu©żng)Į©Īó┤“ķ_Īóäh│²║═ųž├³├¹╬─╝■╗“─┐õøĄ─╣”─▄ĪŻDataNodežō(f©┤)ž¤(z©”)┤µā”öĄ(sh©┤)ō■(j©┤)Ż¼▓ó╠ßžō(f©┤)ž¤(z©”)╠Ä└ĒöĄ(sh©┤)ō■(j©┤)Ą─ūxīæšłŪ¾ĪŻDataNodeČ©Ų┌Ž“NameNode╔Žł¾(b©żo)ą─╠°Ż¼NameNode═©▀^Ēææ¬(y©®ng)ą─╠°üĒ┐žųŲDataNodeĪŻHDFS ╠ß╣®┴╦ę╗éĆ(g©©)Ė▀Č╚╚▌Õe(cu©░)ąį║═Ė▀═╠═┬┴┐Ą─║Ż┴┐öĄ(sh©┤)ō■(j©┤)┤µā”ĮŌøQĘĮ░ĖĪŻHDFS ┐╔ęį╠ß╣®ęįŽ┬╠žąįŻ║
1Ż®┐╔ūį╬ęą▐Å═(f©┤)Ą─Ęų▓╝╩Į╬─╝■┤µā”ŽĄĮy(t©»ng)Ż╗
2Ż®Ė▀┐╔öU(ku©░)š╣ąįŻ¼¤oąĶ═ŻÖC(j©®)äė(d©░ng)æB(t©żi)öU(ku©░)╚▌Ż╗
3Ż®Ė▀┐╔┐┐ąįŻ¼öĄ(sh©┤)ō■(j©┤)ūįäė(d©░ng)Öz£y║═Å═(f©┤)ųŲŻ╗
4Ż®Ė▀═╠═┬┴┐įLå¢Ż¼Ž¹│²įLå¢Ų┐ŅiŻ╗
5Ż®╩╣ė├Ą═│╔▒Š┤µā”║═Ę■äš(w©┤)Ų„śŗ(g©░u)Į©ĪŻ
3.1.2 MapReduceĄ─īŹ(sh©¬)¼F(xi©żn)
MapReduce─Żą═ė╔ā╔ĒŚ(xi©żng)║╦ą─▓┘ū„śŗ(g©░u)│╔Ż║Map║═ ReduceŻ¼ ╩ŪGoogle Ą─ę╗ĒŚ(xi©żng)ųžę¬╝╝ąg(sh©┤)Ż¼ę▓╩Ūę╗éĆ(g©©)ŠÄ│╠─Żą═Ż¼ė├ęį▀M(j©¼n)ąą┤¾ęÄ(gu©®)─Żō■(j©┤)┴┐Ą─Ė▀ą¦ėŗ(j©¼)╦ŃĪŻī”ė┌┤¾┴┐öĄ(sh©┤)ō■(j©┤)Ą─ėŗ(j©¼)╦ŃŻ¼═©│Ż▓╔ė├Ą─╩ųĘ©Š═╩Ū▓óąąėŗ(j©¼)╦ŃĪŻī”ė┌¼F(xi©żn)ļAČ╬Č°čįŻ¼▓óąąėŗ(j©¼)╦Ńī”įSČÓķ_░l(f©Ī)╚╦åTüĒšf▀Ć╩Ūę╗éĆ(g©©)▒╚▌^▀b▀h(yu©Żn)Ą─¢|╬„ĪŻMapReduceŠ═╩Ūę╗ĘN║å╗»▓óąąėŗ(j©¼)╦ŃĄ─ŠÄ│╠─Żą═Ż¼╦³ūī─Ūą®ø]ėąČÓ╔┘▓óąąėŗ(j©¼)╦ŃĮø(j©®ng)“×(y©żn)Ą─ķ_░l(f©Ī)╚╦åTę▓┐╔ęįķ_░l(f©Ī)▓óąąæ¬(y©®ng)ė├│╠ą“ĪŻ
3.1.3 Hadoopā×(y©Łu)ä▌
ŠC╔Ž╦∙╩÷Ż¼▒ŠŲĮ┼_╗∙ė┌HadoopĘų▓╝╩Į╝╝ąg(sh©┤)īŹ(sh©¬)¼F(xi©żn)Ż¼╩╣ŠÄ│╠║═īŹ(sh©¬)¼F(xi©żn)ŲüĒČ╝▒╚▌^╚▌ęūŻ¼─▄ē“Ė▀ą¦Ąž┤µā”║═╣▄└Ē║Ż┴┐öĄ(sh©┤)ō■(j©┤)Ż¼Š▀¾wüĒšfėąęįŽ┬ā×(y©Łu)ä▌Ż║┤µā”ĘĮ├µŻ║¼F(xi©żn)į┌╩└Įń╔ŽūŅ┤¾Ą─Hadoop╝»╚║─┐Ū░į┌FacebookŻ¼┐╔ęį┤µā”30PBĄ─öĄ(sh©┤)ō■(j©┤)ĪŻėŗ(j©¼)╦ŃĘĮ├µŻ║Hadoop╩Ū─┐Ū░TerasortŻ©Terasort╩ŪHadoopųąĄ─Ą─ę╗éĆ(g©©)┼┼ą“ū„śI(y©©)Ż®ėøõøĄ─▒Ż│ųš▀Ż¼Terasort╩ŪĮo│÷1TBĄ─ļSÖC(j©®)öĄ(sh©┤)ō■(j©┤)Ż¼┐┤šl─▄ē“į┌ūŅČ╠Ą─Ģr(sh©¬)ķgā╚(n©©i)═Ļ│╔┼┼ą“Ż¼Hadoop╩╣ė├┴╦1400ČÓéĆ(g©©)╣Ø(ji©”)³c(di©Żn)Ż¼į┌2ĘųńŖā╚(n©©i)═Ļ│╔1TĄ─öĄ(sh©┤)ō■(j©┤)┼┼ą“ĪŻ
3.2 įŲŲĮ┼_┤ŅĮ©
įŲėŗ(j©¼)╦ŃŲĮ┼_Ą─▓┐╩╩ŪÅ═(f©┤)ļsĄ─ŽĄĮy(t©»ng)╣ż│╠Ż¼░³└©╗∙ĄA(ch©│)įO(sh©©)╩®Ą─ĮMčb┼c┤ŅĮ©ĪóįŲėŗ(j©¼)╦ŃŽĄĮy(t©»ng)ŲĮ┼_Ą─░▓čbĪó▓┐╩Īóš{(di©żo)įć║═£yįćĄ╚Ą╚ĪŻ▒ŠīŹ(sh©¬)“×(y©żn)æ¬(y©®ng)ė├Hadoop┐“╝▄üĒśŗ(g©░u)Į©ąĪą═Ą─įŲėŗ(j©¼)╦ŃŲĮ┼_Łh(hu©ón)Š│Ż¼į┌ė▓╝■╔Žė├Ųš═©PCå╬ÖC(j©®)╗“ČÓ┼_Ųš═©PCļŖ─X╝┤┐╔īŹ(sh©¬)¼F(xi©żn)ĪŻ
▒ŠīŹ(sh©¬)“×(y©żn)ė╔4┼_Ųš═©PCļŖ─Xśŗ(g©░u)│╔Ż¼┼õų├Š∙×ķCore2╠Ä└ĒŲ„Ż¼2Gā╚(n©©i)┤µŻ¼▓┘ū„ŽĄĮy(t©»ng)×ķRed Hat LinuxĪŻŲõųąę╗┼_ū„×ķNamenodeŻ¼ÖC(j©®)Ų„├¹×ķmasterŻ¼ŲõėÓ╚²┼_ū„×ķdataNodeŻ¼ÖC(j©®)Ų„├¹Ęųäe×ķslave01Īóslave02Īóslave03ĪŻŽĄĮy(t©»ng)ĮY(ji©”)śŗ(g©░u)╚ńłD1╦∙╩ŠĪŻį┌4┼_ÖC(j©®)Ų„╔ŽĮ©┴óĮy(t©»ng)ę╗Ą─Hadoopė├æ¶Ż¼▓óįO(sh©©)ų├Hadoopė├æ¶Å─masterų„ÖC(j©®)ĄĮĖ„éĆ(g©©)slavesų„├µĄŪõø▓╗ąĶę¬╩╣ė├├▄┤aĪŻ░▓čbHadoop▀\(y©┤n)ąąŁh(hu©ón)Š│Java1.7Ż¼░▓čb░µ▒Š×ķHadoop1.0.3Ą─HadoopŽĄĮy(t©»ng)Ż¼┼õų├conf╬─╝■ŖAŽ┬Ą─hadoopenv.shĪócore-site.xmlĪóhdfs-site.xmlĪómapred-site.xmlĪómasterĪóslave╬─╝■Ż¼│§╩╝╗»Namenode ╣Ø(ji©”)³c(di©Żn)▓óĖ±╩Į╗»hadoop╬─╝■ŽĄĮy(t©»ng)Ą─┤µā”┐šķgŻ¼▓ó▒ŻūCHadoop╬─╝■ŽĄĮy(t©»ng)į┌Ė„éĆ(g©©)╣Ø(ji©”)³c(di©Żn)╔Ž┼õų├╬─╝■Ą─ę╗ų┬ąįĪŻ
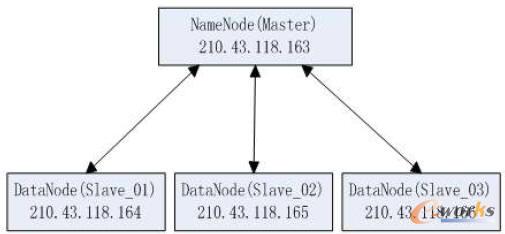
łD1 Hadoop įć“×(y©żn)ŲĮ┼_ĮY(ji©”)śŗ(g©░u)
3.3 ScoolįŲ┤µā”╣▄└ĒŽĄĮy(t©»ng)įO(sh©©)ėŗ(j©¼)
3.3.1 ŽĄĮy(t©»ng)įO(sh©©)ėŗ(j©¼)
▒Š╬─ķ_░l(f©Ī)Ą─ScoolŽĄĮy(t©»ng)įO(sh©©)ėŗ(j©¼)Ą─ųąą─╦╝Žļ╩ŪęįWEB ĘĮ╩ĮŽ“ė├æ¶╠ß╣®╬─╝■▓┘ū„Ę■äš(w©┤)╣”─▄Ż¼ė├æ¶į┌WEB╗∙ĄA(ch©│)╔Ž╩╣ė├▒ŠŽĄĮy(t©»ng)Ż¼Įoė├æ¶╩╣ė├ĦüĒ┴╦śO┤¾ĄžĘĮ▒ŃŻ¼ ė├æ¶ų╗ąĶę¬═©▀^ūóāįŠ═─▄½@╚ĪŽĄĮy(t©»ng)╠ß╣®Ą─┤µā”┐šķgŻ¼Š═┐╔ęį½@╚ĪŽĄĮy(t©»ng)╠ß╣®Ą─┤µā”Ę■äš(w©┤)Ż¼ė├æ¶┐╔ęįĘĮ▒ŃĄ─╣▄└Ē║═╩╣ė├ūį╝║Ą─┐šķgĪŻŽĄĮy(t©»ng)░▓╚½ę▓╩Ū╬ęéāįO(sh©©)ėŗ(j©¼)Ą─ę╗éĆ(g©©)ųž³c(di©Żn)Ż¼ŽĄĮy(t©»ng)═©▀^å╬¬Ü(d©▓)Ą─╬─╝■╣▄└ĒĘ■äš(w©┤)Ų„Ž“įŲ┤µā”ŽĄĮy(t©»ng)░l(f©Ī)╦═ė├涚łŪ¾Ż¼ŽĄĮy(t©»ng)═©▀^š{(di©żo)ė├HadoopŽĄĮy(t©»ng)╠ß╣®Ą─ČÓĘNAPIĘĮ╩ĮĘĮ▒ŃĄž╣▄└Ēė├æ¶╬─╝■Ż¼ø]ėąĮø(j©®ng)▀^“×(y©żn)ūCĄ─ė├æ¶╩Ū▓╗─▄š{(di©żo)ė├║═╩╣ė├APIĮė┐┌ĪŻŻ©╚ńłD2╦∙╩ŠŻ®
▒ŠŽĄĮy(t©»ng)└¹ė├Hadoopū„×ķĄūīė╝»╚║▓┐╩Ż¼ė╔ė┌Hadoopī”ė▓╝■Ą─ę¬Ū¾▓╗Ė▀Ż¼Ųš═©pcÖC(j©®)Š═┐╔ęį▀_(d©ó)ĄĮę¬Ū¾Ż¼▓ó─▄ē“Ė▀ą¦Ą─╠Ä└ĒöĄ(sh©┤)ō■(j©┤)Ż¼ĘĮ▒Ńė├æ¶Ą─╩╣ė├║═▓┘ū„Ż¼×ķė├æ¶öĄ(sh©┤)ō■(j©┤)╠ß╣®Įy(t©»ng)ę╗╣▄└ĒĮń├µŻ¼ī”ė├æ¶╝░Ģr(sh©¬)ĘĄ╗ž╠Ä└ĒĮY(ji©”)╣¹Ż¼ŽĄĮy(t©»ng)įO(sh©©)ėŗ(j©¼)┐é¾w┐╔ėąą¦╝ė┐ņŲõĘ■äš(w©┤)æ¬(y©®ng)ė├Ą─▓┐╩║═īŹ(sh©¬)╩®╣żū„ĪŻ
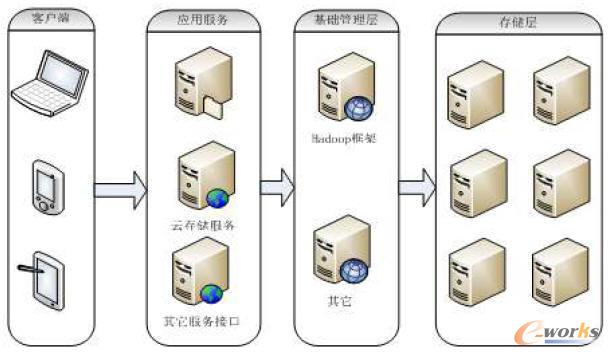
łD2 ŽĄĮy(t©»ng)ĮY(ji©”)śŗ(g©░u)
3.3.2 ─ŻēKįO(sh©©)ėŗ(j©¼)
▒ŠŽĄĮy(t©»ng)ėąęįŽ┬╦─éĆ(g©©)─ŻēKĮM│╔Ż¼╚ńłD3╦∙╩ŠŻ║
ė├æ¶╣▄└Ē─ŻēKŻ║▒Š─ŻēKė├üĒ═Ļ│╔ą┬ė├æ¶Ą─ūóāį╣”─▄Ż¼│╔╣”═©▀^ūóāįĄ─ė├æ¶īó│╔×ķ║ŽĘ©ė├æ¶Ż¼▓ó½@╚Īę╗Č©Ą─┤µā”┐šķgĪŻĮø(j©®ng)▀^ė├æ¶ūóāįŻ¼ŽĄĮy(t©»ng)Ģ■(hu©¼)ėøõøė├æ¶╔ĻšłĢr(sh©¬)Ą─ė├æ¶├¹║═├▄┤aęį╝░Ųõ╦³ė├æ¶ą┼ŽóŻ¼▓ó▒Ż┤µ▀@ą®ė├æ¶öĄ(sh©┤)ō■(j©┤)ą┼ŽóĄĮöĄ(sh©┤)ō■(j©┤)ÄņĪŻė├æ¶╔ĒĘ▌šJ(r©©n)ūC╣”─▄╩ŪųĖė├æ¶ęįWEBĄ─ĘĮ╩ĮĄŪõøĄĮ▒ŠŽĄĮy(t©»ng)Ż¼ė├æ¶ĄŪõøĢr(sh©¬)ŽĄĮy(t©»ng)Ģ■(hu©¼)Ė∙ō■(j©┤)ė├æ¶ĄŪõøą┼Žó┼cöĄ(sh©┤)ō■(j©┤)Äņ▒Ż┤µĄ─ą┼Žóī”▒╚Ż¼ī”▒╚═Ļ╚½ę╗ų┬Ģr(sh©¬)▓┼─▄ē“ĄŪõøĄĮ▒ŠŽĄĮy(t©»ng)ĪŻĘ±ätŻ¼ė├æ¶īó¤oĘ©½@╚ĪįŲ┤µā”ŽĄĮy(t©»ng)╠ß╣®Ą─Ę■äš(w©┤)╣”─▄ĪŻą┼Žó╣▄└Ē╣”─▄╩ŪųĖė├æ¶ōĒėą╣▄└ĒŽÓĻP(gu©Īn)ė├æ¶ą┼ŽóĄ─ÖÓ(qu©ón)┴”Ż¼╚ńĄŪõø├▄┤aĖ³Ė─Īóė├æ¶ą┼ŽóĖ³Ė─Īó├▄┤ašę╗žĄ╚╣”─▄ĪŻ ╬─╝■╣▄└Ē─ŻēKŻ║▒Š─ŻēK╩ŪųĖ║ŽĘ©ė├æ¶į┌ŽĄĮy(t©»ng)╠ß╣®Ą─┤µā”┐šķg╔ŽĄ─╬─╝■▓┘ū„Ę■äš(w©┤)╣”─▄Ż¼ė├æ¶═©▀^┤╦Ę■äš(w©┤)╣▄└Ē┤µā”┐šķg╔ŽĄ─ŽÓĻP(gu©Īn)╬─╝■ĪŻė├æ¶┐╔ęį═Ļ│╔╔Žé„╬─╝■Ż¼Ž┬▌d╬─╝■Ż¼äh│²╬─╝■Ą╚▓┘ū„ĪŻ▒ŠŽĄĮy(t©»ng)į÷╝ėSWFUPLOAD╝╝ąg(sh©┤)üĒīŹ(sh©¬)¼F(xi©żn)╔Žé„┤¾╬─╝■Ą─╣”─▄Ż¼ūŅ┤¾ų¦│ų1G┤¾ąĪĄ─╬─╝■╔Žé„ĪŻ
─┐õø╣▄└Ē─ŻēKŻ║▒Š─ŻēKĄ─╣”─▄╩Ūė├æ¶╣▄└Ē┤µā”┐šķg╔ŽĄ─╬─╝■┤µā”─┐õøŻ¼ė├æ¶┐╔ęįą┬Į©─┐õøüĒ╣▄└Ē▓╗═¼ĘųŅÉĄ─╬─╝■Ż¼ė├æ¶ę▓┐╔ęįäh│²ŽÓæ¬(y©®ng)Ą──┐õøĪŻ
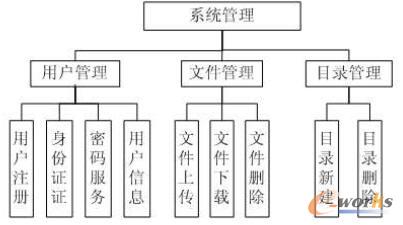
łD3 ŽĄĮy(t©»ng)įO(sh©©)ėŗ(j©¼)
3.3.3 ŽĄĮy(t©»ng)īŹ(sh©¬)¼F(xi©żn)
╗∙ė┌HadoopĄ─įŲ┤µā”╣▄└ĒŽĄĮy(t©»ng)Ż¼īŹ(sh©¬)¼F(xi©żn)┴╦×ķė├æ¶╠ß╣®įŲ┤µā”Ę■äš(w©┤)Ą─╗∙▒Š╣”─▄Ż¼ė├æ¶ĄŪõøŽĄĮy(t©»ng)Š═┐╔ęį¾w“×(y©żn)ScoolįŲ┤µā”ĦĮoė├æ¶Ą─ĘĮ▒ŃĪóīŹ(sh©¬)ė├ĪóĖ▀ą¦Ą─Ę■äš(w©┤)ĪŻ╚ńłD4╦∙╩ŠĪŻ
łD 4 ŽĄĮy(t©»ng)Įń├µ
4 ĮY(ji©”)╩°šZ
╗∙ė┌HadoopīŹ(sh©¬)¼F(xi©żn)Ą─įŲ┤µā”ŲĮ┼_Ż¼─▄ē“╠ß╣®ę╗ĘN┴«ār(ji©ż)Ą─┤¾ęÄ(gu©®)─ŻöĄ(sh©┤)ō■(j©┤)┤µā”ęį╝░Ė▀╦┘öĄ(sh©┤)ō■(j©┤)╠Ä└ĒĄ─ĮŌøQĘĮ░ĖĪŻ═¼Ģr(sh©¬)Ż¼įō┤µā”ŲĮ┼_Š▀ėą┐╔öU(ku©░)š╣ąįĪó░▓╚½ąįĪó╚▌×─(z©Īi)ąįĪóĖ▒▒Šūįäė(d©░ng)▀ĆįŁĪó┐ņ╦┘Ą─╠žąįŻ¼─▄ē“ØMūŃė├æ¶ī”┤µā”ŲĮ┼_īŹ(sh©¬)Ģr(sh©¬)Ą─░┤ąĶöU(ku©░)╚▌Ą─ąĶŪ¾ĪŻęįHDFSū„×ķĘų▓╝╩ĮöĄ(sh©┤)ō■(j©┤)┤µā”Ą─╚▌Ų„Ż¼ĮŌøQ┴╦öĄ(sh©┤)ō■(j©┤)╚▀ėÓéõĘ▌Ą─å¢Ņ}ĪŻįŲ┤µā”ŲĮ┼_ĮŌøQ┴╦ĘŪĮY(ji©”)śŗ(g©░u)╗»║═░ļĮY(ji©”)śŗ(g©░u)╗»Ą─╦╔╔óöĄ(sh©┤)ō■(j©┤)┤µā”Ż¼ęį╝░┤µā”īėĄ─┐╔┐┐ąį║═┐╔öU(ku©░)š╣ąįĄ╚å¢Ņ}ĪŻ═¼Ģr(sh©¬)Ż¼╗∙ė┌HadoopĄ─įŲ┤µā”ŲĮ┼_į┌ī”Ž¾įLå¢Įė┐┌īėīŹ(sh©¬)¼F(xi©żn)┴╦╣”─▄žSĖ╗Ą─Įė┐┌Ż¼─▄ē“ØMūŃ╚šęµį÷ķLĄ─æ¬(y©®ng)ė├ąĶŪ¾Ż¼×ķĮ±║¾Ą─įŲ┤µā”░▓╚½Īóąį─▄ā×(y©Łu)╗»Īóęį╝░ķ_░l(f©Ī)Ųõ╦³æ¬(y©®ng)ė├Ę■äš(w©┤)Ą─蹊┐╠ß╣®╗∙ĄA(ch©│)ĪŻ
ŽĄĮy(t©»ng)Ą─░▓╚½ęį╝░ąį─▄ā×(y©Łu)╗»╩ŪŽ┬ę╗▓Į蹊┐╣żū„Ą─ųž³c(di©Żn)Ż¼ŽĄĮy(t©»ng)░▓╚½ĘĮ├µūŅ×ķųžę¬Ż¼čąŠ┐kerberosšJ(r©©n)ūCÖC(j©®)ųŲ╩Ūę╗ĘNėąą¦Ą─ĮŌøQĘĮ░ĖŻ¼kerberosīŹ(sh©¬)¼F(xi©żn)Ą─╩ŪÖC(j©®)Ų„╝ēäeĄ─░▓╚½šJ(r©©n)ūCŻ¼ė╔ė┌kerberosī”╝»╚║└’Ą─╦∙ėąÖC(j©®)Ų„Č╝Ęų░l(f©Ī)┴╦keytabŻ¼ŽÓ╗źų«ķg╩╣ė├├▄ĶĆ▀M(j©¼n)ąą═©ą┼Ż¼┤_▒Ż▓╗Ģ■(hu©¼)├░│õĘ■äš(w©┤)Ų„Ą─ŪķørŻ¼ęį▒ŻūCįŲ┤µā”Ą─░▓╚½Ę└ūo(h©┤)╣”─▄ĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N(y©┤n)║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.hanmeixuan.com/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║ę╗ĘN╗∙ė┌HadoopĄ─ScoolįŲ┤µā”ŲĮ┼_
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.hanmeixuan.com/html/support/1112159073.html



▀xą═ųąą─")
¾w“×(y©żn)ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")