Ū░čį
ļSų°ą┼Žó╠Ä└Ē╝╝ąg(sh©┤)Ą─▓╗öÓ░l(f©Ī)š╣Ż¼ą┼ŽóĄ─┤µā”(ch©│)Īó╣▄└Ē╩╣ė├║═ŠSūo(h©┤)’@Ą├įĮüĒįĮųžę¬Ż¼Č°é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)Äņ╣▄└ĒŽĄĮy(t©»ng)║▄ļyØMūŃŲõę¬Ū¾Ż¼▒Ē¼F(xi©żn)×ķŻ║öĄ(sh©┤)ō■(j©┤)┴┐│╔Äū║╬╝ē(j©¬)öĄ(sh©┤)Ą─į÷ķL(zh©Żng)Ż¼▓╗═¼▓┐ĘųĄ─öĄ(sh©┤)ō■(j©┤)ļyęį╝»║ŽŻ¼įLå¢öĄ(sh©┤)ō■(j©┤)Ą─Ēææ¬(y©®ng)ąį─▄▓╗öÓĮĄĄ═ĪŻę¬╩╣öĄ(sh©┤)ō■(j©┤)─▄ē“░l(f©Ī)ō]ŲõūŅ╝č╣”ą¦Ż¼Ė³║├Ąž×ķė├æ¶Ę■äš(w©┤)Ż¼öĄ(sh©┤)ō■(j©┤)é}ÄņĄ─│÷¼F(xi©żn)×ķė├æ¶╠Ä└Ē╦∙ąĶꬥ─øQ▓▀ą┼Žó╠ß╣®┴╦ę╗ĘNėąą¦Ą─ĘĮĘ©ĪŻ
1 ŽÓĻP(gu©Īn)└Ēšō║═╝╝ąg(sh©┤)╗∙ĄA(ch©│)
öĄ(sh©┤)ō■(j©┤)═┌Š“Ą─Č©┴xŻ║öĄ(sh©┤)ō■(j©┤)═┌Š“Š═╩ŪÅ─┤¾┴┐Ą─Īó▓╗═Ļ╚½Ą─Īóėąįļ┬ĢĄ─Īó─Ż║²Ą─ĪóļSÖC(j©®)Ą─įŁ╩╝öĄ(sh©┤)ō■(j©┤)ųąŻ¼╠ß╚Īļ[║¼į┌ŲõųąĄ─Īó╚╦éā╩┬Ž╚▓╗ų¬Ą└Ą─ĪóĄ½ėų╩ŪØōį┌ėąė├Ą─ą┼Žó║═ų¬ūR(sh©¬)Ą─▀^│╠ĪŻ
öĄ(sh©┤)ō■(j©┤)═┌Š“ŲõīŹ(sh©¬)╩Ūę╗éĆ(g©©)ųØuč▌ūāĄ─▀^│╠ĪŻļŖūėöĄ(sh©┤)ō■(j©┤)╠Ä└ĒĄ─│§Ų┌Ż¼╚╦éāŠ═įćłD═©▀^ę╗ą®ĘĮĘ©üĒīŹ(sh©¬)¼F(xi©żn)ūįäė(d©░ng)øQ▓▀ų¦│ųŻ¼«ö(d©Īng)Ģr(sh©¬)ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)│╔×ķ╚╦éāĻP(gu©Īn)ą─Ą─Į╣³c(di©Żn)ĪŻÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)Ą─▀^│╠Š═╩Ūīóę╗ą®ęčų¬▓ó│╔╣”ĮŌøQĄ─å¢Ņ}ū„×ķĘČ└²▌ö╚ļėŗ(j©¼)╦ŃÖC(j©®)Ż¼ÖC(j©®)Ų„═©▀^īW(xu©”)┴Ģ(x©¬)▀@ą®ĘČ└²Ż¼┐éĮY(ji©”)▓ó╔·│╔ŽÓæ¬(y©®ng)Ą─ęÄ(gu©®)ätĪŻļS║¾Ż¼ļSų°╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)╝╝ąg(sh©┤)Ą─ą╬│╔║═░l(f©Ī)š╣Ż¼╚╦éāĄ─ūóęŌ┴”▐D(zhu©Żn)Ž“ų¬ūR(sh©¬)╣ż│╠ĪŻų¬ūR(sh©¬)╣ż│╠▓╗═¼ė┌ÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)Ż¼▓╗╩Ū×ķėŗ(j©¼)╦ŃÖC(j©®)▌ö╚ļĘČ└²Ż¼ė╔Ųõ╔·│╔Ą─ęÄ(gu©®)ätŻ¼Č°╩Ūų▒Įė×ķėŗ(j©¼)╦ŃÖC(j©®)▌ö╚ļęč▒╗┤·┤a╗»Ą─ęÄ(gu©®)ätŻ¼Č°ėŗ(j©¼)╦ŃÖC(j©®)╩Ū═©▀^╩╣ė├▀@ą®ęÄ(gu©®)ätĮŌøQ─│ą®å¢Ņ}ĪŻīŻ╝ꎥĮy(t©»ng)Š═╩Ū▀@ĘNĘĮĘ©╦∙Ą├ĄĮĄ─│╔╣¹Ż¼Ą½ėą═Č┘Y┤¾║═ą¦╣¹▓╗╔§└ĒŽļĄ╚▓╗ūŃĪŻ20╩└╝o(j©¼)80─Ļ┤·╚╦éāėųį┌ą┬Ą─╔±Įø(j©®ng)ŠW(w©Żng)Įj(lu©░)└ĒšōĄ─ųĖī¦(d©Żo)Ž┬Ż¼ųžą┬╗žĄĮÖC(j©®)Ų„īW(xu©”)┴Ģ(x©¬)Ą─ĘĮĘ©╔ŽĪŻ▓óīóŲõ│╔╣¹æ¬(y©®ng)ė├ė┌╠Ä└Ē┤¾ą═╔╠śI(y©©)öĄ(sh©┤)ō■(j©┤)ÄņŻ¼│÷¼F(xi©żn)┴╦öĄ(sh©┤)ō■(j©┤)ÄņųąĄ─ų¬ūR(sh©¬)░l(f©Ī)¼F(xi©żn)Ż¼║å(ji©Żn)ĘQKDDŻ©Knowledged Discovery in DatabaseŻ®ĪŻ╦³Ę║ųĖÅ─╦∙ėąöĄ(sh©┤)ō■(j©┤)į┤ųą░l(f©Ī)Š“─Ż╩ĮĄ─┬ō(li©ón)ŽĄ║═ĘĮĘ©Ż¼╚╦éāĮė╩▄┴╦▀@éĆ(g©©)ąg(sh©┤)šZĪŻ1995 į┌├└ć°(gu©«)ėŗ(j©¼)╦ŃÖC(j©®)īW(xu©”)Ģ■(hu©¼)Ż©ACMŻ®╔ŽŻ¼╠ß│÷┴╦öĄ(sh©┤)ō■(j©┤)═┌Š“Ż©DMŻ¼DataMiningŻ®Ė┼─Ņū„×ķų¬ūR(sh©¬)░l(f©Ī)¼F(xi©żn)▀^│╠Ą─ĻP(gu©Īn)µI▓Į¾EŻ¼Ą½╩Ū¼F(xi©żn)į┌╚╦éāī”(du©¼)ė┌KDD║═DM ▀@ā╔éĆ(g©©)Ė┼─Ņ═©│Ż▓╗╝ėęįģ^(q©▒)äeŻ¼╦∙ęį═∙═∙╗ņė├ĪŻ
2 öĄ(sh©┤)ō■(j©┤)═┌Š“ųąĄ─Š█ŅÉ╦ŃĘ©
Š█ŅÉ╦ŃĘ©╩Ū▒Š╬─ųž³c(di©Żn)蹊┐Ą─ī”(du©¼)Ž¾Ż¼═©▀^ĮķĮBŠ█ŅÉ╦ŃĘ©Ą─ę╗ą®╗∙▒ŠįŁ└Ē║═Ė┼─ŅŻ¼īó┤╦╦ŃĘ©į┌CRM ŽĄĮy(t©»ng)ųąū„│÷ę╗éĆ(g©©)æ¬(y©®ng)ė├ĪŻ
Š█ŅÉŻ║Š█ŅÉ╩Ūķ_╩╝Ęų╬÷Ą─║├ĘĮĘ©Ż¼╠žäe╩Ū├µ┼R┤¾┴┐Å═(f©┤)ļsĄ─┐╔─▄ėą║▄ČÓā╚(n©©i)▓┐ĮY(ji©”)śŗ(g©░u)Ą─öĄ(sh©┤)ō■(j©┤)╝»ĪŻ═©▀^╩╣ė├▀@ĘNĘĮĘ©Ż¼Ęų╬÷š▀┐╔ęįīóę╗éĆ(g©©)┤¾å¢Ņ}░┤šš╠žš„Ęų│╔ę╗ĮMĪŻŻ¼▀@ą®Š█ŅÉ╠ß╣®┴╦ī”(du©¼)Ųõųą│╔åTĄ─├Ķ╩÷ĪŻ═©▀^╠ß╣®ĘųŅÉ▀@ą®Š█ŅÉĄ─ĘĮĘ©Ż¼╬ęéāŠ═─▄ē“?q©▒)”å¢Ņ}ėąéĆ(g©©)┤¾ų┬Ą─┴╦ĮŌĪŻŠ█ŅÉŠ═╩Ūīó╬’└Ē╗“│ķŽ¾Ą─╝»║ŽĘųĮM│╔×ķė╔ŅÉ╦ŲĄ─ī”(du©¼)Ž¾ĮM│╔Ą─ČÓéĆ(g©©)ŅÉĄ─▀^│╠ĪŻŠ█ŅÉĄ─ĮY(ji©”)╣¹╩Ū╩╣═¼ę╗éĆ(g©©)ŅÉäeā╚(n©©i)Ą─ī”(du©¼)Ž¾Š▀ėą▌^Ė▀Ą─ŽÓ╦ŲČ╚Ż¼Č°▓╗═¼Ą─ŅÉäeĄ─ī”(du©¼)Ž¾ų«ķg▓Ņäe║▄┤¾ĪŻŠ█ŅÉį÷ÅŖ(qi©óng)┴╦╚╦éāī”(du©¼)┐═ė^¼F(xi©żn)īŹ(sh©¬)Ą─šJ(r©©n)ūR(sh©¬)Ż¼╩ŪĖ┼─Ņ├Ķ╩÷║═Ų½▓ŅĘų╬÷Ą─Ž╚øQŚl╝■ĪŻ
2.1 CRMĄ─Ė┼─Ņ
CRM Ą─║╦ą─ā╚(n©©i)╚▌╩Ū═©▀^▓╗öÓĄžĖ─╔Ų┼c╣▄└ĒŲ¾śI(y©©)õN╩█ĪóĀI(y©¬ng)õNĪó┐═æ¶Ę■äš(w©┤)║═ų¦│ųĄ╚┼c┐═æ¶ĻP(gu©Īn)ŽĄėąĻP(gu©Īn)Ą─śI(y©©)äš(w©┤)┴„│╠Ż¼╠ßĖ▀Ė„éĆ(g©©)Łh(hu©ón)╣Ø(ji©”)Ą─ūįäė(d©░ng)╗»│╠Č╚ĪŻÅ─Č°┐sČ╠õN╩█ų▄Ų┌Ż¼ĮĄĄ═õN╩█│╔▒ŠŻ¼öU(ku©░)┤¾õN╩█┴┐Ż¼ōīš╝Ė³ČÓ╩ął÷(ch©Żng)Ę▌Ņ~Ż¼īżŪ¾ą┬Ą─╩ął÷(ch©Żng)ÖC(j©®)Ģ■(hu©¼)Ż¼ūŅĮK▀_(d©ó)ĄĮÅ─Ė∙▒Š╔Ž╠ß╔²Ų¾śI(y©©)║╦ą─Ėé(j©¼ng)ĀÄ(zh©źng)┴”Ą──┐Ą─ĪŻ
2.2 öĄ(sh©┤)ō■(j©┤)é}ÄņĄ─╠ž³c(di©Żn)
öĄ(sh©┤)ō■(j©┤)é}Äņ╩Ū├µŽ“ų„Ņ}Ą─ų„Ņ}Ż¼╩ŪųĖė├æ¶╩╣ė├öĄ(sh©┤)ō■(j©┤)é}Äņ▀M(j©¼n)ąąøQ▓▀Ģr(sh©¬)╦∙ĻP(gu©Īn)ą─Ą─ųž³c(di©Żn)ĘĮ├µŻ¼╚ń╣żśI(y©©)ŪķørĪó▐r(n©«ng)śI(y©©)ŪķørĪóš¹éĆ(g©©)Ė▀┐Ų╝╝ł@░l(f©Ī)š╣?f©żn)ŅørĄ╚Ż╗╦∙ų^├µŽ“ų„Ņ}Ż¼╩ŪųĖöĄ(sh©┤)ō■(j©┤)é}Äņā╚(n©©i)Ą─ą┼Žó╩Ū░┤ų„Ņ}▀M(j©¼n)ąąĮM┐ŚĄ─Ż¼×ķ░┤ų„Ņ}▀M(j©¼n)ąąøQ▓▀Ą─▀^│╠╠ß╣®ą┼ŽóĪŻ
öĄ(sh©┤)ō■(j©┤)é}Äņ╩Ū╝»│╔Ą─Ż║╝»│╔Ż¼╩ŪųĖöĄ(sh©┤)ō■(j©┤)é}ÄņųąĄ─ą┼Žó▓╗╩ŪÅ─Ė„éĆ(g©©)śI(y©©)äš(w©┤)ŽĄĮy(t©»ng)ųą║å(ji©Żn)å╬│ķ╚Ī│÷üĒĄ─Ż¼╩ŪĮø(j©®ng)▀^ŽĄĮy(t©»ng)╝ė╣żĪóģR┐é║═š¹└ĒŻ¼▒ŻūCöĄ(sh©┤)ō■(j©┤)é}Äņā╚(n©©i)Ą─ą┼Žó╩ŪĻP(gu©Īn)ė┌š¹éĆ(g©©)ŽĄĮy(t©»ng)Ą─ę╗ų┬Ą─╚½Šųą┼ŽóĪŻ
öĄ(sh©┤)ō■(j©┤)é}Äņ╩ŪĘĆ(w©¦n)Č©Ą─Ż║ĘĆ(w©¦n)Č©Ż¼╩ŪųĖę╗Ą®─│éĆ(g©©)öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)╚ļöĄ(sh©┤)ō■(j©┤)é}Äņęį║¾Ż¼ę╗░ŃŪķørŽ┬īó▒╗ķL(zh©Żng)Ų┌▒Ż┴¶Ż¼ę▓Š═╩ŪöĄ(sh©┤)ō■(j©┤)é}Äņųąę╗░Ńėą┤¾┴┐Ą─▓Õ╚ļ║═▓ķįā▓┘ū„Ż¼Ą½ą▐Ė─║═äh│²▓┘ū„║▄╔┘ĪŻ
öĄ(sh©┤)ō■(j©┤)é}Äņ╩ŪļSĢr(sh©¬)ķgį÷ķL(zh©Żng)Ą─Ż║öĄ(sh©┤)ō■(j©┤)é}Äņ░³║¼Üv╩ĘöĄ(sh©┤)ō■(j©┤)Ż¼╩ŪųĖöĄ(sh©┤)ō■(j©┤)é}Äņā╚(n©©i)Ą─ą┼Žó▓ó▓╗ų╗╩Ū─│ę╗Ģr(sh©¬)³c(di©Żn)Ą─ą┼ŽóŻ¼Č°╩ŪŽĄĮy(t©»ng)ėøõø┴╦Å─▀^╚ź─│ę╗Ģr(sh©¬)³c(di©Żn)Ż©╚ńķ_╩╝æ¬(y©®ng)ė├öĄ(sh©┤)ō■(j©┤)é}ÄņĄ─Ģr(sh©¬)³c(di©Żn)Ż®ĄĮ─┐Ū░Ė„éĆ(g©©)ļAČ╬Ą─ą┼ŽóŻ¼═©▀^▀@ą®ą┼Žó▒Ē├„░l(f©Ī)š╣Üv│╠▓óī”(du©¼)┌ģä▌(sh©¼)ū÷│÷Č©┴┐Ęų╬÷║═ŅA(y©┤)£y(c©©)ĪŻ
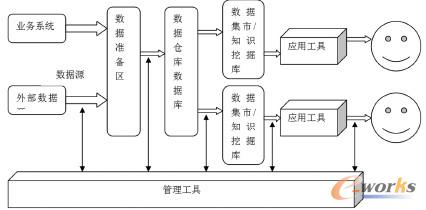
łD1 öĄ(sh©┤)ō■(j©┤)é}ÄņĖ┼─ŅĮY(ji©”)śŗ(g©░u)łD
į┌▒Š╬─Ą─CRMŽĄĮy(t©»ng)Į©─ŻųąŻ¼Į©┴ó│¼╩ąĄ─öĄ(sh©┤)ō■(j©┤)é}Äņ╩Ūę╗éĆ(g©©)ĻP(gu©Īn)µIĄ─▓Į¾EĪŻ
3 Š█ŅÉ╦ŃĘ©┼cīė┤╬Ęų╬÷Ę©
3.1 K-meansŠ█ŅÉ╦ŃĘ©
K-meansŠ█ŅÉ╦ŃĘ©Ą─╗∙▒Š╦╝Žļ
╝┘Č©ąĶꬊ█ŅÉĄ─ī”(du©¼)Ž¾╣▓ėąn éĆ(g©©)Ż¼░čn éĆ(g©©)ī”(du©¼)Ž¾Ęų×ķC éĆ(g©©)┤žŻ¼ęį╩╣┤žā╚(n©©i)ėą▌^Ė▀Ą─ŽÓ╦ŲČ╚Ż¼Č°┤žķgĄ─ŽÓ╦ŲČ╚▌^Ą═ĪŻŽÓ╦ŲČ╚Ą─ėŗ(j©¼)╦ŃĖ∙ō■(j©┤)ę╗éĆ(g©©)┤žųąī”(du©¼)Ž¾Ą─ŲĮŠ∙Ę┬Ż©▒╗┐┤ū„┤žĄ─ųžą─Ż®üĒ▀M(j©¼n)ąąĪŻŲõ╗∙▒Š╦╝Žļ╩ŪŻ║╩ūŽ╚ļSÖC(j©®)Å─öĄ(sh©┤)ō■(j©┤)╝»ųą▀x╚ĪC éĆ(g©©)³c(di©Żn)ū„×ķ│§╩╝Š█ŅÉųąą─Ż©öĄ(sh©┤)┴┐C╩Ūį┌╦ŃĘ©▀\(y©┤n)ąąŪ░┤_Č©Ą─Ż®Ż¼╚╗║¾ī”(du©¼)╩ŻėÓĄ─├┐éĆ(g©©)ī”(du©¼)Ž¾Ż¼Ė∙ō■(j©┤)Ųõ┼cĖ„éĆ(g©©)┤žųąą─Ą─ŠÓļxŻ¼īó╦³┘xėĶūŅĮ³Ą─┤žŻ¼ųžą┬ėŗ(j©¼)╦Ń├┐éĆ(g©©)┤žĄ─ŲĮŠ∙ųĄĪŻ
▀@ę╗▀^│╠▓╗öÓųžÅ═(f©┤)Ż¼ų▒ĄĮ£╩(zh©│n)ät║»öĄ(sh©┤)╩šö┐ĪŻ
═©│Ż▓╔ė├ŲĮĘĮš`▓Ņ£╩(zh©│n)ätŻ¼ŲõČ©┴x╚ń╣½╩Į3.1╦∙╩ŠŻ║

3.2 īė┤╬Ęų╬÷Ę©
3.2.1 īė┤╬Ęų╬÷Ę©Ą─Üv╩Ę
īė┤╬Ęų╬÷Ę©Ż©AHPŻ®╩ŪīóøQ▓▀┐é╩ŪėąĻP(gu©Īn)Ą─į¬╦žĘųĮŌ│╔─┐ś╦(bi©Īo)Īó£╩(zh©│n)ätĪóĘĮ░ĖĄ╚īė┤╬Ż¼į┌┤╦╗∙ĄA(ch©│)ų«╔Ž▀M(j©¼n)ąąČ©ąį║═Č©┴┐Ęų╬÷Ą─øQ▓▀ĘĮĘ©ĪŻįōĘĮĘ©╩Ū├└ć°(gu©«)▀\(y©┤n)╗IīW(xu©”)╝ęŲź┤─▒ż┤¾īW(xu©”)Į╠╩┌╦_Ą┘ė┌▒Š╩└╝o(j©¼)70 ─Ļ┤·│§Ż¼æ¬(y©®ng)ė├ŠW(w©Żng)Įj(lu©░)ŽĄĮy(t©»ng)└Ēšō║═ČÓ─┐ś╦(bi©Īo)ŠC║Žįu(p©¬ng)ār(ji©ż)ĘĮĘ©Ż¼╠ß│÷Ą─ę╗ĘNīė┤╬ÖÓ(qu©ón)ųžøQ▓▀Ęų╬÷ĘĮĘ©ĪŻ
3.2.2 īė┤╬Ęų╬÷Ę©Ą─╠ž³c(di©Żn)
īė┤╬Ęų╬÷ĘĮĘ©Ą─╠ž³c(di©Żn)╩Ūį┌ī”(du©¼)Å═(f©┤)ļsĄ─øQ▓▀å¢Ņ}Ą─▒Š┘|(zh©¼)Īóė░Ēæę“╦ž╝░Ųõā╚(n©©i)į┌ĻP(gu©Īn)ŽĄĄ╚▀M(j©¼n)ąą╔Ņ╚ļĘų╬÷Ą─╗∙ĄA(ch©│)╔ŽŻ¼└¹ė├▌^╔┘Ą─Č©┴┐ą┼Žó╩╣øQ▓▀Ą─╦╝ŠS▀^│╠öĄ(sh©┤)īW(xu©”)╗»Ż¼Å─Č°×ķČÓ─┐ś╦(bi©Īo)ĪóČÓ£╩(zh©│n)ät╗“¤oĮY(ji©”)śŗ(g©░u)╠žąįĄ─Å═(f©┤)ļsøQ▓▀å¢Ņ}╠ß╣®║å(ji©Żn)▒ŃĄ─øQ▓▀ĘĮĘ©ĪŻė╚Ųõ▀m║Žė┌ī”(du©¼)øQ▓▀ĮY(ji©”)╣¹ļyė┌ų▒Įė£╩(zh©│n)┤_ėŗ(j©¼)┴┐Ą─ł÷(ch©Żng)║ŽĪŻ
k-means╦ŃĘ©║═īė┤╬Ęų╬÷Ę©ĮY(ji©”)║ŽŲüĒ×ķīŹ(sh©¬)¼F(xi©żn)į┌│¼╩ąĄ─CRMŻ©┐═æ¶╣▄└ĒŽĄĮy(t©»ng)─Żą═Ż®Ą─æ¬(y©®ng)ė├Ż¼╦∙ęįŽ┬├µš┬╣Ø(ji©”)Š═│¼╩ąCRMŻ©┐═æ¶ĻP(gu©Īn)ŽĄ╣▄└ĒŽĄĮy(t©»ng)Ż®▀M(j©¼n)ąąĮ©─ŻĪŻ
4 ╗∙ė┌Š█ŅÉ╦ŃĘ©║═īė┤╬Ęų╬÷Ę©į┌CRMŽĄĮy(t©»ng)Ą─æ¬(y©®ng)ė├
K-meansŠ█ŅÉ╦ŃĘ©į┌│¼╩ąCRMĄ─īŹ(sh©¬)└²Ęų╬÷
Ż©1Ż®╦ŃĘ©Ż║K-meansŠ█ŅÉ╦ŃĘ©ĪŻäØĘųĄ─K-means╦ŃĘ©╗∙ė┌┤žųąī”(du©¼)Ž¾Ą─ŲĮŠ∙ųĄĪŻ
Ż©2Ż®▌ö╚ļ:┤žĄ─öĄ(sh©┤)─┐k║═░³║¼néĆ(g©©)ī”(du©¼)Ž¾Ą─öĄ(sh©┤)ō■(j©┤)ÄņĪŻ
Ż©3Ż®▌ö│÷:kéĆ(g©©)┤žŻ¼ØMūŃŲĮĘĮš`▓Ņ£╩(zh©│n)ätūŅąĪĪŻ
Ż©4Ż®ī”(du©¼)ė┌öĄ(sh©┤)ō■(j©┤)ī”(du©¼)Ž¾╝»{x1,x2,x3......xn}Ż¼ļS╝┤▀x╚Īk éĆ(g©©)│§╩╝╗»ųąą─{y1,y2,y3......yn}ū„×ķ│§╩╝┤žĄ─ųąą─ĪŻ
repeat ėŗ(j©¼)╦ŃĖ„śė▒ŠĄĮŠ█ŅÉųąą─Ą─ŠÓļxŻ¼ī”(du©¼)ė┌╚╬ęŌ³c(di©Żn)x,┤µį┌Y,Ż¼╩╣Ą├ŲõØMūŃ╩Į

Ż©8Ż®until▓╗į┘░l(f©Ī)╔·ūā╗»ĪŻ
K-means Š█ŅÉ╦ŃĘ©×ķę╗ĘNĮŌøQŠ█ŅÉå¢Ņ}Ą─Įø(j©®ng)Ąõ╦ŃĘ©Ż¼▀@ĘN╦ŃĘ©║å(ji©Żn)å╬Īó┐ņ╦┘ĪŻćLįćšę│÷╩╣ŲĮĘĮš`▓Ņ║»öĄ(sh©┤)ųĄūŅąĪĄ─kéĆ(g©©)äØĘų.ū„«ö(d©Īng)ĮY(ji©”)╣¹┤ž╩Ū├▄╝»Ą─Ż¼Č°┤ž┼c┤žų«ķgģ^(q©▒)äe├„’@Ģr(sh©¬)Ż¼╦³Ą─ą¦╣¹▌^║├ĪŻī”(du©¼)ė┌╠Ä└Ē┤¾öĄ(sh©┤)ō■(j©┤)╝»Ż¼įō╦ŃĘ©╩ŪŽÓī”(du©¼)┐╔╔ņ┐sĄ─║═Ė▀ą¦Ą─Ż¼ę“?y©żn)ķ╦³Ą─Å?f©┤)ļsČ╚╩ŪOŻ©nktŻ®Ż¼ŲõųąŻ¼n╩Ū╦∙ėąī”(du©¼)Ž¾Ą─öĄ(sh©┤)─┐Ż¼k╩Ū┤žĄ─öĄ(sh©┤)─┐Ż¼C╩ŪĄ³┤·Ą─┤╬öĄ(sh©┤)ĪŻ
═©│ŻĄžŻ¼Č°Ūęt<nĪŻ▀@éĆ(g©©)╦ŃĘ©Įø(j©®ng)│ŻęįŠų▓┐ūŅā×(y©Łu)ĮŌĮY(ji©”)╩°ĪŻ
╔Ž╩÷Ą─ŽĄ┴ąłDšf├„┴╦æ¬(y©®ng)ė├k-means ╦ŃĘ©║═īė┤╬Ęų╬÷Ę©Ą├│÷ė├æ¶Øōį┌ār(ji©ż)ųĄĄ─▀^│╠ĪŻŽĄĮy(t©»ng)į┌╠Ä└Ē║Ż┴┐Ą─ŅÖ┐═öĄ(sh©┤)ō■(j©┤)║¾Ż¼┐╔½@Ą├┐╔┐┐Ą─ą┼Žóų¦│ų▓▀┬į║═╔╠śI(y©©)øQ▓▀Ż¼Ėé(j©¼ng)ĀÄ(zh©źng)ī”(du©¼)╩ų║▄ļyą¦Ę┬▀@ą®øQ▓▀Ż¼ę“┤╦│¼╩ą┐╔ęįį┌Ėé(j©¼ng)ĀÄ(zh©źng)ųą▒Ē¼F(xi©żn)│÷ā×(y©Łu)ä▌(sh©¼)ĪŻ
5 ĮY(ji©”)╩°šZ
öĄ(sh©┤)ō■(j©┤)═┌Š“╩Ūą┼Žó╝╝ąg(sh©┤)░l(f©Ī)š╣ĄĮę╗Č©ļAČ╬║¾«a(ch©Żn)╔·Ą─ą┬┼d╝╝ąg(sh©┤)Ż¼╦³╩ŪÅ─┤¾┴┐Ą─īŹ(sh©¬)ļHæ¬(y©®ng)ė├öĄ(sh©┤)ō■(j©┤)ųąŻ¼╠ß╚Īļ[║¼į┌ŲõųąĄ─ėąė├Ą─ą┼Žó║═ų¬ūR(sh©¬)ĪŻū„×ķę╗ĒŚ(xi©żng)øQ▓▀ų¦│ųĄ─ą┬╝╝ąg(sh©┤)Ż¼─┐Ū░į┌ć°(gu©«)ļH╔Žī”(du©¼)įōŅI(l©½ng)ė“Ą─蹊┐ŽÓ«ö(d©Īng)╗Ņ▄SĪŻŠ█ŅÉĘų╬÷╩ŪöĄ(sh©┤)ō■(j©┤)═┌Š“Ą─ųžę¬ā╚(n©©i)╚▌Ż¼ę▓╩ŪöĄ(sh©┤)ō■(j©┤)═┌Š“ŅI(l©½ng)ė“ā╚(n©©i)ūŅ×ķ│ŻęŖĄ─╝╝ąg(sh©┤)ų«ę╗Ż¼╦³╝╚┐╔ęįū„×ķå╬¬Ü(d©▓)Ą─╣żŠ▀ęį░l(f©Ī)¼F(xi©żn)öĄ(sh©┤)ō■(j©┤)į┤Ą─öĄ(sh©┤)ō■(j©┤)Ęų▓╝ą┼ŽóŻ¼ę▓┐╔ęįū„×ķŲõ╦¹öĄ(sh©┤)ō■(j©┤)═┌Š“╦ŃĘ©Ą─ę╗éĆ(g©©)ŅA(y©┤)╠Ä└Ē▓Į¾EŻ¼ę“┤╦蹊┐Š█ŅÉ╦ŃĘ©Ą─ąį─▄Š▀ėąųžę¬Ą─ęŌ┴xĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_(t©ói)╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N(y©┤n)║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšł(q©½ng)ūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.hanmeixuan.com/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║╗∙ė┌öĄ(sh©┤)ō■(j©┤)═┌Š“╝░Ųõį┌│¼╩ąCRMĄ─æ¬(y©®ng)ė├
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.hanmeixuan.com/html/consultation/10839311529.html



▀xą═ųąą─")
¾w“×(y©żn)ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")