Š®¢|įŲ║Ż╩Ūė╔Š®¢|║═ISV╣▓═¼║Žū„Ą──Ż╩Įī”╔╠╝ę╠ß╣®Ę■äšĪŻįŲ║Ż╠ß╣®╗∙ĄAĄ─Š®¢|POP(╔╠╝ęķ_Ę┼ŲĮ┼_)öĄ(sh©┤)ō■(j©┤)Ż¼░³└©╔╠ŲĘĪó╔╠╝ęĪó┐═Ę■┐āą¦ĪóŲĘ┼ŲĪóąąśI(y©©)Ą╚ų„Ņ}öĄ(sh©┤)ō■(j©┤)Ż¼─┐Ū░┐╔╠ß╣®T+1ģR┐éėŗ╦ŃĮY╣¹Ż¼ęį╝░╔Ž░┘éĆīŹĢrųĖś╦ėåķåĪŻISV═©▀^╔╠╝ę╩┌ÖÓ┐╔ęį½@╚Ī╔╠╝ę╗∙ĄAöĄ(sh©┤)ō■(j©┤)Ż¼ISV═©▀^JOSĄ─APIĮė┐┌╔Žé„ŽÓĻPŠS▒ĒöĄ(sh©┤)ō■(j©┤)Ż¼öĄ(sh©┤)ō■(j©┤)╔Žé„ĄĮöĄ(sh©┤)ō■(j©┤)é}Äņ║¾Ż¼ISV┐╔ęįį┌įŲ║Żķ_Ę┼ŲĮ┼_╔Žķ_░l(f©Ī)ŽÓĻPĄ─Hive SQLī”╔Žé„öĄ(sh©┤)ō■(j©┤)║═╔╠╝ę╗∙ĄAöĄ(sh©┤)ō■(j©┤)▀MąąĻP┬ō(li©ón)ėŗ╦ŃŻ¼ėŗ╦ŃĮY╣¹┐╔ęį═©▀^öĄ(sh©┤)ō■(j©┤)ķ_Ę┼API▓ķįāŻ¼ISV½@╚ĪĄĮöĄ(sh©┤)ō■(j©┤)║¾═©▀^æ¬ė├š╣¼F(xi©żn)Įo╔╠╝ę╩╣ė├ĪŻ
ąĶŪ¾ł÷Š░ę╗Ż║JOSķ_Ę┼APIš{ė├ŪķørĘų╬÷Ż©OLAPĘų╬÷Ż®
JOSķ_Ę┼ĮėĮ³500éĆAPIŻ¼├┐╠ņš{ė├┴┐į┌7ā|┤╬ū¾ėęĪŻßśī”APIĄ─š{ė├Ūķør▀MąąČÓŠSĘų╬÷Ż¼Ęų╬÷▓ķįāčė▀tę¬Ū¾▀_ĄĮ├ļ╝ēŻ¼▓ó╩╣ė├BI╣żŠ▀▀MąąĘų╬÷š╣¼F(xi©żn)ĪŻ
JOSĄ─APIįLå¢╚šųŠöĄ(sh©┤)ō■(j©┤)═©▀^Č©Ģrūź╚Ī┤µā”į┌HiveöĄ(sh©┤)ō■(j©┤)é}ÄņųąĪŻ╦∙ęįąĶę¬ę╗ĘN─▄ē“į┌┤¾öĄ(sh©┤)ō■(j©┤)┴┐ŪķørŽ┬▀MąąĮ╗╗ź╩ĮČÓŠSĘų╬÷Ą─SQL on Hadoopę²ŪµĪŻ▓óŪęę¬ų¦│ų║═BI╣żŠ▀Ą─╝»│╔Ż¼╠ß╣®ś╦£╩Ą─JDBCĪóODBCĮė┐┌ĪŻ
ąĶŪ¾ł÷Š░Č■Ż║įŲ║ŻĮY╣¹öĄ(sh©┤)ō■(j©┤)Ž┬▌dŻ©įŁ╩╝├„╝ÜöĄ(sh©┤)ō■(j©┤)▓ķįāŻ®
įŲ║Ż═©▀^JOSĄ─APIīóĮY╣¹▒ĒĄ─öĄ(sh©┤)ō■(j©┤)▓ķįāĘ■äšķ_Ę┼ĮoISVŻ¼ķ_Ę┼Ę■äšųąį╩įSISVČ©┴xś╦£╩SQL─Ż░ÕŻ¼į┌Įė┐┌š{ė├Ģré„▀f▓╗═¼ģóöĄ(sh©┤)üĒ▓ķįāöĄ(sh©┤)ō■(j©┤)Ż¼Įė┐┌å╬┤╬š{ė├ĘĄ╗žöĄ(sh©┤)ō■(j©┤)┴┐Ž▐ųŲ×ķ5000ŚlŻ¼Įė┐┌▓ķįāčė▀tę¬▒ŻūCį┌║┴├ļ╝ēäeŻ¼▓óų¦│ųĖ▀▓ó░l(f©Ī)š{ė├ĪŻĮY╣¹▒ĒöĄ(sh©┤)ō■(j©┤)┤µā”į┌HiveöĄ(sh©┤)ō■(j©┤)é}ÄņųąĪŻ╦∙ęįąĶę¬ę╗ĘNSQL on Hadoopę²Ūµ─▄ē“ų¦ō╬╗∙ė┌┤¾▒ĒĄ─įŁ╩╝├„╝ÜöĄ(sh©┤)ō■(j©┤)║┴├ļ╝ē▓ķįāĪŻ
ĻPė┌Apache Kylin
¼F(xi©żn)į┌ķ_į┤╔ńģ^(q©▒)Ė„ĘNā×(y©Łu)ąŃĄ─SQL on Hadoopę²Ūµ▓╗öÓė┐¼F(xi©żn)Ż¼▒╚╚ńImpalaŻ¼SparkSQLŻ¼PhoenixĄ╚Ą╚ĪŻĄ½╩Ūßśī”ė┌ęį╔Žł÷Š░Ą─┐╝æ]Ż║┤¾öĄ(sh©┤)ō■(j©┤)┴┐ŪķørŽ┬├ļ╝ēČÓŠSĘų╬÷Īóų¦│ų┼cé„Įy(t©»ng)BI╣żŠ▀¤o┐p╝»│╔Īóį┌┤¾öĄ(sh©┤)ō■(j©┤)┴┐╗∙ĄA╔Ž╩╣ė├ś╦£╩SQL▓ķįāąĪöĄ(sh©┤)ō■(j©┤)┴┐ĮY╣¹╝»─▄ē“▀_ĄĮ║┴├ļ╝ēĪó═Ļ╚½╗∙ė┌Hadoop╔·æB(t©żi)ŽĄĮy(t©»ng)ĪóT+1║═īŹĢr╠Ä└ĒöĄ(sh©┤)ō■(j©┤)Īóų¦│ų╦«ŲĮöUš╣Ą╚ĪŻūŅĮK╬ęéā░č─┐ś╦µiČ©į┌┴╦Apache KylinĪŻ
Apache Kylin╩Ūę╗éĆķ_į┤Ą─Ęų▓╝╩ĮĘų╬÷ę²ŪµŻ¼╠ß╣®Hadoopų«╔ŽĄ─SQL▓ķįāĮė┐┌╝░ČÓŠSĘų╬÷Ż©OLAPŻ®─▄┴”ęįų¦│ų│¼┤¾ęÄ(gu©®)─ŻöĄ(sh©┤)ō■(j©┤)Ż¼─▄ē“ų¦│ųTBĄĮPB╝ēäeĄ─öĄ(sh©┤)ō■(j©┤)┴┐Ż¼ūŅ│§ė╔eBay Incķ_░l(f©Ī)▓óė┌2014─Ļ10į┬žĢ½Ių┴ķ_į┤╔ńģ^(q©▒)Ż¼ė┌2014─Ļ11į┬╝ė╚ļApacheʧ╗»Ų„ĒŚ─┐Ż¼ė┌Į±─Ļ11į┬š²╩Į«ģśI(y©©)│╔×ķApache Ēö╝ēĒŚ─┐ĪŻ
Apache Kylinų╝į┌£p╔┘Hadoopį┌10ā|╝░░┘ā|ęÄ(gu©®)─Żęį╔ŽöĄ(sh©┤)ō■(j©┤)╝ēäeĄ─ŪķørŽ┬Ą─▓ķįāčė▀tŻ¼─┐Ū░ĄūīėöĄ(sh©┤)ō■(j©┤)┤µā”╗∙ė┌HBaseŻ¼Š▀ėą▌^ÅŖĄ─┐╔╔ņ┐sąįĪŻApache Kylin×ķHadoopöĄ(sh©┤)ō■(j©┤)╠ß╣®┴╦ANSI-SQLĮė┐┌Ż¼▓óŪęų¦│ų┤¾ČÓöĄ(sh©┤)Ą─ANSI-SQLĄ─║»öĄ(sh©┤)Ż╗─▄ē“ų¦│ųį┌├ļ╝ēäečė▀tĄ─ŪķørŽ┬═¼Hadoop▀MąąĮ╗╗ź╩Į▓ķįāŻ╗ų¦│ųČÓŠS┬ō(li©ón)ÖCĘų╬÷╠Ä└ĒöĄ(sh©┤)ō■(j©┤)é}ÄņŻ©MOLAP CubeŻ®Ż╗ė├æ¶─▄ē“Č©┴xöĄ(sh©┤)ō■(j©┤)─Żą═Ż╗▓óŪę═©▀^Apache Kylin─▄ē“ŅAĮ©│¼▀^10ČÓā|ąąįŁ╩╝öĄ(sh©┤)ō■(j©┤)ėøõøĄ─öĄ(sh©┤)ō■(j©┤)─Żą═Ż╗┐╔┼cŲõ╦¹BI╣żŠ▀¤o┐p╝»│╔Ż¼░³└©TableauŻ¼ExcelŻ¼PowerBIĄ╚Ż╗▓ó╠ß╣®┴╦JDBCŻ¼ODBCĮė┐┌Ż╗┐╔Ęų▓╝╩Į▓┐╩Ż¼Query Server┐╔ęį╦«ŲĮöUš╣Ż¼┤µā”╗∙ė┌HBaseę▓┐╔ęį╦«ŲĮöUš╣ĪŻ▓óŪęApache Kylinīóį┌║¾└m(x©┤)░µ▒Šų¦│ų┴„╩ĮĮ³īŹĢrCubeėŗ╦ŃŻ¼ų¦│ųīŹĢröĄ(sh©┤)ō■(j©┤)ČÓŠSĘų╬÷Ą╚Ė„ĘNł÷Š░ĪŻ
Ė³ČÓĻPė┌Apache KylinĄ─įö╝Üą┼Žó┐╔ęįįLå¢Ż║http://kylin.io
Apache Kylinį┌Š®¢|įŲ║ŻĄ─æ¬ė├▓┐╩╝░ąį─▄
ŽĄĮy(t©»ng)╝▄śŗ╝░╝»╚║▓┐╩
Apache Kylin╝»╚║Ż║
- 1éĆ╚╬äšĘ■äšŲ„Ż¼4éĆ▓ķįāĘ■äšŲ„ĪŻ
- Apache HBase╝»╚║ęÄ(gu©®)─ŻŻ║
- 27éĆ╣Ø(ji©”)³cŻ¼║═Ųõ╦¹śI(y©©)äš╣▓ė├ĪŻ
- ā╔ĘNł÷Š░╩╣ė├═¼ę╗éĆ╝»╚║ĪŻ
─ŻēKĻPŽĄłDŻ║
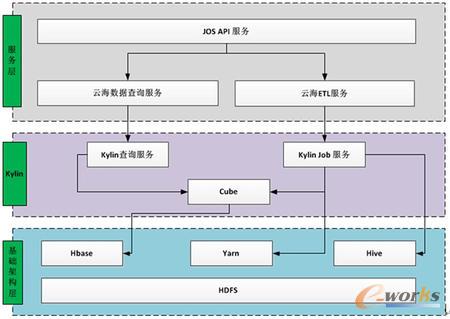
▓┐╩łDŻ║
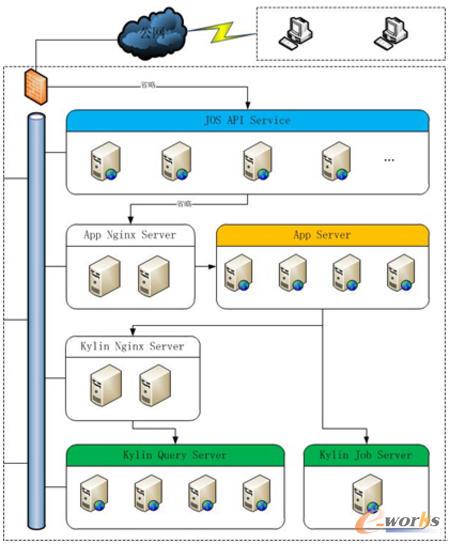
Apache Kylinąį─▄▒Ē¼F(xi©żn)Ż║
1.OLAPĘų╬÷
å╬éĆCubeūŅ┤¾ŠSČ╚16éĆŻ¼ūŅ┤¾öĄ(sh©┤)ō■(j©┤)ŚlöĄ(sh©┤)100ā|Ż¼ūŅ┤¾┤µā”┐šķg400GĪŻ
ąį─▄Ż║öĄ(sh©┤)ō■(j©┤)Ęų╬÷╚╦åT▓╔ė├BI╣żŠ▀▀Mąą▓ķįāŻ¼95%Ą─▓ķįāĒææ¬Ģrķgį┌15├ļęįā╚ĪŻ
2.įŁ╩╝├„╝ÜöĄ(sh©┤)ō■(j©┤)▓ķįā
å╬éĆCubeūŅ┤¾ŠSČ╚8éĆŻ¼ūŅ┤¾öĄ(sh©┤)ō■(j©┤)ŚlöĄ(sh©┤)4ā|Ż¼ūŅ┤¾┤µā”┐šķg800GĪŻ30éĆCubeš╝ė├┐é┐šķg4Tū¾ėęĪŻ
ąį─▄Ż║å╬┤╬▓ķįāĘĄ╗žöĄ(sh©┤)ō■(j©┤)ŚlöĄ(sh©┤)Ž▐ųŲį┌5000Ślęįā╚Ż¼▓ķįāQPSį┌50ū¾ėęŻ¼╦∙ėą▓ķįāŲĮŠ∙Ēææ¬Ģrķg200msŻ¼▓ķįāQPSį┌200ū¾ėęŲĮŠ∙Ēææ¬Ģrķg┐╔ęį▒Ż│ųį┌1sęįā╚ĪŻ
▓ķįāĄ─▓ó░l(f©Ī)─▄┴”║═Ēææ¬Ģrķg║═HBase╝»╚║ęÄ(gu©®)─ŻėąĻPŻ¼▀@ā╔éĆł÷Š░Ą─öĄ(sh©┤)ō■(j©┤)ų╗╩╣ė├┴╦ę╗éĆąĪ╝»╚║Ż¼┐╔ęįī”Apache Kylin Query Server║═HBase╝»╚║╦«ŲĮöU╚▌üĒ╠ßĖ▀▓ó░l(f©Ī)▓ķįā─▄┴”║═£pąĪĒææ¬ĢrķgĪŻ
Apache KylinįŁ▓╗ų¦│ų┤╦╣”─▄Ż¼Š®¢|ī”ŲõīŹ¼F(xi©żn)▀ē▌ŗū÷┴╦ą▐Ė─Ż¼▓óęčĮøžĢ½I╗ž╔ńģ^(q©▒)ĪŻ
Š®¢|ī”ė┌Apache KylinĄ─Č■┤╬ķ_░l(f©Ī)
ų„ꬥ─Ė─įņ╩Ūį÷╝ė┴╦ų¦│ųįŁ╩╝├„╝ÜöĄ(sh©┤)ō■(j©┤)▓ķįāĄ─īŹ¼F(xi©żn)ĪŻ
Apache Kylinį┌╩╣ė├SQL▓ķįāĢrŻ¼ų┴╔┘ąĶę¬ųĖČ©ę╗éĆGroup byŚl╝■Ż¼į┌ŅÉ╦ŲSelect dimension_column1,measure_column2,measure_column3 from fact_table▀@ĘN░³║¼ųĖś╦┴ą├„╝ÜöĄ(sh©┤)ō■(j©┤)Ą─▓ķįāĢr▓╗─▄ĘĄ╗žĮY╣¹ĪŻ
ė╔ė┌Apache KylinĄ─Cubeėŗ╦Ń╩ŪĖ∙ō■(j©┤)╦∙ėąŠ█║ŽŠSČ╚Ą─ĮM║Žėŗ╦ŃČ©┴xųĖś╦Ą─ųĄŻ¼į┌CubeČ©┴xļAČ╬▒žĒÜ░³║¼Š█║ŽŠSČ╚║═ėŗ╦ŃųĖś╦Ą─┼õų├ĪŻėŗ╦ŃųĖś╦─┐Ū░░³└©SUMŻ¼MAXŻ¼MINŻ¼COUNTŻ¼COUNT_DISTINCTĪŻ
ė╔┤╦Žļę¬īŹ¼F(xi©żn)įŁ╩╝öĄ(sh©┤)ō■(j©┤)Ą─▓ķįāėąęįŽ┬ĘĮ░ĖŻ║
ĘĮ░Ėę╗
į┌įŁ╩╝öĄ(sh©┤)ō■(j©┤)▒Ēųąį÷╝ėę╗┴ą╬©ę╗ųĄ┴ąŻ¼▓óīó╦∙ėą┴ąČ╝┼õų├×ķŠSČ╚┴ąŻ¼╚ń╣¹─│┴ąĄ─╗∙öĄ(sh©┤)ĘŪ│ŻĖ▀Ż¼ät▓╗äō(chu©żng)Į©ūųĄõųĖČ©╣╠Č©┴ąķLČ╚Ą─ĘĮ╩ĮįOų├ŠSČ╚ī┘ąįĪŻ▀@śėĄ─Cubeėŗ╦ŃĮY╣¹ŽÓ«öė┌ī”╬©ę╗ųĄ┴ą▀MąąGroup byŻ¼Ģ■▓ķįāĄĮ╦∙ėąąąĄ─ųĄĪŻ
ĘĮ░ĖĄ─ā×(y©Łu)³cŻ║▓╗ė├ą▐Ė─Apache Kylin┤·┤aŻ¼ų╗ąĶę¬╠Ä└ĒįŁ╩╝öĄ(sh©┤)ō■(j©┤)į÷╝ė╬©ę╗┴ą╝┤┐╔ĪŻ
ĘĮ░ĖĄ─╚▒³cŻ║ļm╚╗╩Ūų¦│ų┴╦įŁ╩╝├„╝ÜöĄ(sh©┤)ō■(j©┤)Ą─▓ķįāŻ¼Ą½╩Ū╦∙ėą┴ąČ╝ū„×ķ┴╦ŠSČ╚Š█║ŽŻ¼į┌įŁ╩╝▒Ē┴ąĄ─öĄ(sh©┤)┴┐ĘŪ│ŻČÓĄ─ŪķørŽ┬Ż¼CubeĄ─┤¾ąĪĢ■┼“├øĄ─ĘŪ│Ż┤¾Ż¼śŗĮ©Ģrķgį÷ķLĪŻ╦∙ęįąĶę¬Ė³ā×(y©Łu)Ą─ĘĮĘ©üĒ╠Ä└ĒĪŻ
ĘĮ░ĖČ■
1Īóį┌įŁ╩╝öĄ(sh©┤)ō■(j©┤)▒Ēųąį÷╝ėę╗┴ą╬©ę╗ųĄ┴ąŻ¼▓ó░č┤╦┴ą┼õų├į┌ŠSČ╚ųąĪŻ
2Īóą▐Ė─į┤┤aį÷╝ėę╗éĆą┬Ą─Š█║Ž║»öĄ(sh©┤)Ż¼┤╦Š█║Ž║»öĄ(sh©┤)Ą─▌ö╚ļ║═▌ö│÷▒Ż│ųŽÓ═¼Ż¼▓╗ū÷╚╬║╬Š█║Žėŗ╦ŃĪŻ═©▀^▀@éĆŠ█║Ž║»öĄ(sh©┤)║═ī”╬©ę╗┴ąĄ─Š█║ŽüĒ▒ŻūC├┐ę╗éĆųĖś╦┴ąĄ─įŁ╩╝ųĄČ╝─▄▒╗½@╚ĪĄĮĪŻė╔ė┌Apache Kylin▒Š╔ĒĦėąĄ─Š█║Ž║»öĄ(sh©┤)ų╗ų¦│ųöĄ(sh©┤)ūųŅÉą═Ą─┴ąŻ¼╦∙ęįąĶę¬į÷╝ėą┬Ą─Š█║Ž║»öĄ(sh©┤)ų¦│ų╦∙ėąöĄ(sh©┤)ō■(j©┤)ŅÉą═Ą─▌ö╚ļ║═▌ö│÷ĪŻ▀@śė─▄ē“£p╔┘▓╗▒žę¬Ą─ŠSČ╚ĮM║ŽŻ¼£pąĪCubeĄ─┤¾ąĪŻ¼┐sČ╠śŗĮ©Ą─ĢrķgĪŻ
ĘĮ░ĖĄ─ā×(y©Łu)³cŻ║─▄ē“ĮŌøQĘĮ░Ėę╗ųąCube┼“├øĄ─å¢Ņ}║═śŗĮ©ĢrķgķLĄ─å¢Ņ}ĪŻ
ĘĮ░ĖĄ─╚▒³cŻ║╚ń╣¹öĄ(sh©┤)ō■(j©┤)▒Ēųą▓╗┤µį┌╬©ę╗┴ąĄ─ŪķørĢrŻ¼▓╗─▄ē“▓ķįāĄĮ╦∙ėąĄ─├„╝ÜöĄ(sh©┤)ō■(j©┤)ĪŻĖ³║├Ą─ĮŌøQĘĮ░Ė╩Ūį┌ø]ėą╬©ę╗┴ąĄ─ŪķørŽ┬═¼śėę▓─▄ē“ų¦│ų├„╝ÜöĄ(sh©┤)ō■(j©┤)▓ķįāĪŻ
╬ęéā╩Ūī”ĘĮ░ĖČ■▀Mąą┴╦īŹ¼F(xi©żn)Ż¼▓óŪęīóPatchžĢ½I╗ž╔ńģ^(q©▒)Ż¼─┐Ū░š²į┌║═╔ńģ^(q©▒)ę╗Ųā×(y©Łu)╗»Ż║╝┤ĘĮ░Ė╚²ĪŻ
ĘĮ░Ė╚²
1Īó▓╗ąĶę¬į┌įŁ╩╝▒Ēųąį÷╝ė╬©ę╗┴ąĪŻ
2Īóą▐Ė─į┤┤aį÷╝ėą┬Ą─Š█║Ž║»öĄ(sh©┤)Ż¼┤╦Š█║Ž║»öĄ(sh©┤)─▄╩╣▒╗Š█║ŽĄ─├„╝ÜöĄ(sh©┤)ō■(j©┤)┤µā”į┌HBaseųąĄ─ę╗ąąĪŻį┌▓ķįāĢrīóöĄ(sh©┤)ō■(j©┤)▀Mąąš╣ķ_ĪŻ
3Īóą▐Ė─į┤┤aį÷╝ėī”Š█║Ž║»öĄ(sh©┤)ųĄĄ─ūųĄõų¦│ųŻ¼ęį£p╔┘┤µā”öĄ(sh©┤)ō■(j©┤)┤¾ąĪĪŻ
┤╦ĘĮ░Ė╩ŪĖ─▀MĘĮ░ĖŻ¼╬ęéāš²į┌║═╔ńģ^(q©▒)╣▓═¼▀Mąąā×(y©Łu)╗»Ė─įņŻ¼šłĻPūóKYLIN-1122ęįĖ·█ÖūŅą┬▀Mš╣ĪŻ
╩╣ė├Apache KylinĄ─īŹ█`┐éĮY
1Īó┤¾Ą─╩┬īŹ▒Ē▓╔ė├╠ņĘųģ^(q©▒)į÷┴┐śŗĮ©Ż¼×ķ┴╦▓╗ė░Ēæ▓ķįāąį─▄Ż¼┐╔ęįČ©Ų┌ū÷║Ž▓ó(Merge)Ż¼ų▄Ų┌┐╔ęįĖ∙ō■(j©┤)īŹļHŪķør┤_Č©Ż¼╬ęéāę╗ų▄▀Mąąę╗┤╬║Ž▓óĪŻ
2Īóī”ė┌ŠS▒Ē▒╚▌^┤¾Ą─ŪķørŻ¼╗“š▀▓ķįāSelect▓┐Ęų┤µį┌Å═ļsĄ─▀ē▌ŗ┼ąöÓŻ¼┤µį┌Apache Kylin▓╗ų¦│ųĄ─║»öĄ(sh©┤)╗“šZŠõĢrŻ¼┐╔ęįīó╩┬īŹ▒Ē║═ŠS▒ĒĄ─ĻP┬ō(li©ón)╠Ä└Ēäō(chu©żng)Į©×ķHiveęĢłDŻ¼ų«║¾Ė∙ō■(j©┤)ęĢłDäō(chu©żng)Į©Cube─Żą═ĪŻ
3Īó├┐┤╬▓ķįā▒ž╚╗ĦėąĄ─Śl╝■Į©ūhį┌ūųĄõįOų├▓Į¾EīóŲõįOų├×ķMandatoryĪŻ▀@śėĢ■ūŅĮK Build│÷üĒCubeĄ─┤¾ąĪĢ■£p╔┘ę╗░ļĪŻ
4ĪóCubeĄ─ŠSČ╚╚ń╣¹│¼▀^10éĆŻ¼Į©ūhīó│Żė├Ą─Š█║ŽūųČ╬ū÷ĘųĮMŻ¼╬ęéāī”ė┌ūŅ┤¾Ą─16éĆŠSČ╚Ęų┴╦╚²éĆĮMŻ¼├┐ĮM┤¾Ė┼į┌5éĆŠSČ╚ū¾ėęĪŻ
5ĪóCubeČ©┴xųąRowKeyĒśą“Ż║MandatoryŠSČ╚Ż¼Where▀^×VŚl╝■ųą│÷¼F(xi©żn)Ņl┬╩▌^ČÓĄ─ŠSČ╚Ż¼Ė▀╗∙öĄ(sh©┤)ŠSČ╚Ż¼Ą═╗∙öĄ(sh©┤)ŠSČ╚ĪŻ
6Īóī”ė┌HierarchiesŻ¼DerivedŠSČ╚ĘĮ├µ┼õų├ā×(y©Łu)╗»┐╔ęįģó┐╝╔ńģ^(q©▒)╬─ÖnŻ║http://kylin.incubator.apache.org/docs/howto/howto_optimize_cubes.html
7Īó▓┐╩īė├µŻ¼┐╔ęį═©▀^Nginxį┌Ū░Č╦ū÷žō▌dŠ∙║ŌŻ¼║¾Č╦åóäėČÓéĆQuery ServerĮė╩š▓ķįāšłŪ¾╠Ä└ĒĪŻ
├¹į~ĮŌßīŻ║
įŲ║ŻŻ║Š®¢|įŲ║ŻöĄ(sh©┤)ō■(j©┤)ķ_Ę┼ŲĮ┼_
ISV Ż║┼cŠ®¢|įŲ║Žū„Ą─Ą┌╚²ĘĮĘ■äšÅS╔╠
JOSŻ║Š®¢|APIķ_Ę┼Ę■äš
ĻPė┌ū„š▀Ż║═§ĢįėĻŻ¼Apache Kylin CommitterŻ¼Š®¢|┤¾öĄ(sh©┤)ō■(j©┤)┘Y╔Ņ╝▄śŗĤŻ¼▒▒Š®Ó]ļŖ┤¾īW▄ø╝■╣ż│╠┤T╩┐Ż¼2014─Ļ╝ė╚ļŠ®¢|įŲŲĮ┼_-öĄ(sh©┤)ō■(j©┤)ŲĮ┼_▓┐Ż¼ģó┼cŠ®¢|╣½ėąįŲöĄ(sh©┤)ō■(j©┤)Ęų╬÷ŲĮ┼_Ą─š¹¾w╝▄śŗįOėŗ╝░ķ_░l(f©Ī)Ż¼ų┬┴”ė┌ī”┐═æ¶╠ß╣®įŲ╔ŽĄ─īŹĢröĄ(sh©┤)ō■(j©┤)é}ÄņĄ─╠Į╦„ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äšŅIė“ĪóąąśI(y©©)æ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻPūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.hanmeixuan.com/
▒Š╬─ś╦Ņ}Ż║Š®¢|═§ĢįėĻŻ║Apache Kylinį┌įŲ║ŻĄ─īŹ█`
▒Š╬─ŠWųĘŻ║http://m.hanmeixuan.com/html/news/10515318948.html



▀xą═ųąą─")
¾w“×ųąą─")
«aŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")