1öĄ(sh©┤)ō■(j©┤)é}Äņ┼cOLAP
1·1Å─öĄ(sh©┤)ō■(j©┤)ÄņĄĮöĄ(sh©┤)ō■(j©┤)é}Äņ
▀^╚źÄū╩«─Ļųą,öĄ(sh©┤)ō■(j©┤)Äņ╝╝ąg(sh©┤),╠žäe╩ŪOLTP(į┌ŠĆ╩┬äš╠Ä└Ē)░l(f©Ī)š╣Ą├▌^×ķ│╔╩ņ,╦³Ą─Ė∙▒Š╚╬䚊═╩Ū╝░ĢrĄžĪó░▓╚½Ąžīó«öŪ░╩┬äš╦∙«a(ch©Żn)╔·Ą─ėøõø▒Ż┤µŽ┬üĒĪŻļSų°╔ńĢ■Ą─░l(f©Ī)š╣,╚╦éā╠ß│÷┴╦└¹ė├¼F(xi©żn)ėąĄ─öĄ(sh©┤)ō■(j©┤),▀MąąĘų╬÷║══Ų└Ē,ī¦ų┬┴╦øQ▓▀ų¦│ųŽĄĮy(t©»ng)(DSS)Ą─«a(ch©Żn)╔·.ļSų°öĄ(sh©┤)ō■(j©┤)┴┐Ą─čĖ╦┘į÷┤¾ęį╝░▓ķįāę¬Ū¾Ą─Å═ļs╗»,Į©┴óį┌OLTPĄ─öĄ(sh©┤)ō■(j©┤)Äņ╔ŽĄ─DSS,▒®┬Č│÷įSČÓļyęį┐╦Ę■Ą─└¦ļy:
1)╚▒Ę”ĮM┐ŚąįĪŻĖ„éĆ▓┐ķT│ķ╚ĪĄ─öĄ(sh©┤)ō■(j©┤)ø]ėąĮy(t©»ng)ę╗Ą─Ģrķg╗∙£╩,│ķ╚Ī╦ŃĘ©Īó│ķ╚Ī╝ēäeę▓Ė„▓╗ŽÓ═¼,▓óŪę┐╔─▄ģó┐╝┴╦▓╗═¼Ą─═Ō▓┐öĄ(sh©┤)ō■(j©┤)ĪŻ
2)ą¦┬╩śO×ķĄ═Ž┬,öĄ(sh©┤)ō■(j©┤)ļyęį▐D(zhu©Żn)╗»×ķėąė├Ą─ą┼ŽóĪŻįŁ╩╝ĀŅæB(t©żi)ųąĄ─┤¾┴┐öĄ(sh©┤)ō■(j©┤),═¼ę╗ūųČ╬į┌▓╗═¼æ¬ė├ųąėų┐╔─▄┤µį┌ų°═¼├¹«É┴xĪó«É├¹═¼┴xĪóŅÉą═▓╗═¼ĪóūųķL▓╗═¼Ą╚įSČÓļyęįūRäeĄ─┬ķ¤®ĪŻ
3)Ųõ╦¹└¦ö_ų°╗∙ė┌é„Įy(t©»ng)DBDSSĄ─å¢Ņ}ĪŻDSSī”OLTPąį─▄Ą─ė░Ēæ╩Ūļyęį╚╠╩▄Ą─ĪŻ┴Ē═Ō,OLTPĄ─DBĖ„éĆæ¬ė├ŅI(l©½ng)ė“Ą─öĄ(sh©┤)ō■(j©┤)▒Ż┤µŲ┌Ž▐Č╝▓╗ę╗śė,ļyęįØMūŃDSSąĶę¬ĪŻ
öĄ(sh©┤)ō■(j©┤)é}ÄņūŅų„ꬥ─╠žš„╩Ū:
l)öĄ(sh©┤)ō■(j©┤)é}Äņ╩Ū├µŽ“ų„Ņ}Ą─ĪŻ╦³┼cé„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)Äņ├µŽ“æ¬ė├ŽÓī”æ¬,ų„Ņ}╩Ūę╗éĆį┌▌^Ė▀īė┤╬īóöĄ(sh©┤)ō■(j©┤)ÜwŅÉĄ─ś╦£╩,├┐ę╗éĆų„Ņ}ī”æ¬ę╗éĆ║Ļė^Ą─Ęų╬÷ŅI(l©½ng)ė“ĪŻ
2)öĄ(sh©┤)ō■(j©┤)é}Äņ╩Ū╝»│╔Ą─ĪŻįŁ╩╝öĄ(sh©┤)ō■(j©┤)┼c▀m║ŽDSSĘų╬÷Ą─öĄ(sh©┤)ō■(j©┤)ų«ķg▓Ņäe║▄┤¾ĪŻę“┤╦,į┌öĄ(sh©┤)ō■(j©┤)▀M╚ļöĄ(sh©┤)ō■(j©┤)é}Äņų«Ū░,▒ž╚╗ę¬Įø(j©®ng)▀^╝ė╣ż┼c╝»│╔ĪŻ
3)öĄ(sh©┤)ō■(j©┤)é}Äņ╩ŪĘĆ(w©¦n)Č©Ą─ĪŻ╦³Ę┤ė│Ą─╩ŪÜv╩ĘöĄ(sh©┤)ō■(j©┤)Ą─ā╚(n©©i)╚▌,Č°▓╗╩Ū╠Ä└Ē┬ō(li©ón)ÖCöĄ(sh©┤)ō■(j©┤).ę“Č°,öĄ(sh©┤)ō■(j©┤)Įø(j©®ng)╝»│╔▀M╚╦öĄ(sh©┤)ō■(j©┤)é}Äņ║¾╩ŪśO╔┘╔§ų┴Ė∙▒Š▓╗Ė³ą┬Ą─ĪŻ
4)öĄ(sh©┤)ō■(j©┤)é}Äņ╩ŪļSĢrķgūā╗»Ą─ĪŻöĄ(sh©┤)ō■(j©┤)é}Äņā╚(n©©i)Ą─öĄ(sh©┤)ō■(j©┤)ĢrŽ▐ę¬▀h▀hķLė┌▓┘ū„ą═Łh(hu©ón)Š│ųąĄ─öĄ(sh©┤)ō■(j©┤)ĢrŽ▐;öĄ(sh©┤)ō■(j©┤)é}ÄņųąĄ─öĄ(sh©┤)ō■(j©┤)Č╝╩ŪÜv╩ĘöĄ(sh©┤)ō■(j©┤);öĄ(sh©┤)ō■(j©┤)é}ÄņöĄ(sh©┤)ō■(j©┤)Ą─┤aµIę╗░ŃČ╝░³║¼ĢrķgĒŚ,Å─Č°ś╦├„┴╦įōöĄ(sh©┤)ō■(j©┤)Ą─Üv╩ĘĢrŲ┌ĪŻ
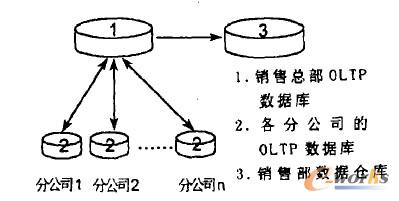
ę╗ĘNĄõą═Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņĮY(ji©”)śŗ(g©░u)╚ńłD1╦∙╩Š.╦³Ęų×ķ╦─╝ē:įńŲ┌╝Ü╣Ø(ji©”)╝ēĪó«öŪ░╝Ü╣Ø(ji©”)╝ēĪó▌pČ╚ŠC║Ž╝ē║═Ė▀Č╚ŠC║Ž╝ēĪŻįŁ╩╝öĄ(sh©┤)ō■(j©┤)Įø(j©®ng)╝»│╔ęį║¾,╩ūŽ╚▀M╚╦«öŪ░╝Ü╣Ø(ji©”)╝ē,▓óĖ∙ō■(j©┤)ąĶę¬▀Mę╗▓Į▀MąąŠC║Ž,▀M╚ļ▌pČ╚ŠC║Ž╝ē─╦ų┴Ė▀Č╚ŠC║Ž╝ē,└Ž╗»Ą─öĄ(sh©┤)ō■(j©┤)ät▀M╚ļįńŲ┌╝Ü╣Ø(ji©”)╝ēĪŻöĄ(sh©┤)ō■(j©┤)é}Äņųą┤µį┌ų°▓╗═¼Ą─╝Ü╣Ø(ji©”)╝ēäe,ĘQų«×ķ“┴ŻČ╚”.┴ŻČ╚įĮĖ▀▒Ē╩Š╝Ü╣Ø(ji©”)│╠Č╚įĮĄ═ĪóŠC║Ž│╠Č╚įĮĖ▀ĪŻöĄ(sh©┤)ō■(j©┤)é}ÄņĄ─┴Ēę╗éĆųžę¬╝╝ąg(sh©┤)╩Ū╚ń║╬Č©Ų┌Ž“öĄ(sh©┤)ō■(j©┤)é}ÄņūĘ╝ėöĄ(sh©┤)ō■(j©┤).│Żė├Ą─╝╝ąg(sh©┤)ūŌĘĮĘ©ėą:
łD1.öĄ(sh©┤)ō■(j©┤)é}ÄņĮY(ji©”)śŗ(g©░u)
Ģrś╦ĘĮĘ©:╚ń╣¹öĄ(sh©┤)ō■(j©┤)║¼ėąĢrś╦,ų╗ąĶĖ∙ō■(j©┤)Ģrś╦┼ąöÓ╝┤┐╔.
DELTA╬─╝■:ė╔æ¬ė├╔·│╔,ėøõøæ¬ė├╦∙Ė─ūāĄ─╦∙ėąā╚(n©©i)╚▌ĪŻ
Ū░║¾ė│Ž¾╬─╝■Ą─ĘĮĘ©:į┌│ķ╚ĪöĄ(sh©┤)ō■(j©┤)Ū░║¾ī”öĄ(sh©┤)ō■(j©┤)ÄņĖ„ū„ę╗┤╬┐ņšš,╚╗║¾▒╚▌^ā╔Ę∙┐ņššĄ─▓╗═¼Å─Č°┤_Č©ą┬öĄ(sh©┤)ō■(j©┤)ĪŻ
╚šųŠ╬─╝■:╦³▓╗Ģ■ė░ĒæOLTPĄ─ąį─▄.═¼Ģr,╦³▀ĆŠ▀ėąDELTA╬─╝■Ą─ā×(y©Łu)įĮąį┘|(zh©¼),╠ß╚ĪöĄ(sh©┤)ō■(j©┤)ų╗ꬊųŽ▐ė┌╚šųŠ╬─╝■.
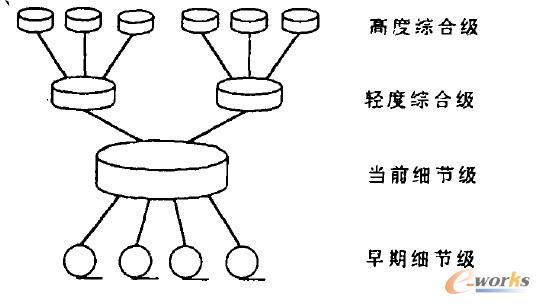
1.2Å─OLTPĄĮOLAP
OLAP(į┌ŠĆĘų╬÷╠Ä└Ē)╩ŪęįöĄ(sh©┤)ō■(j©┤)Äņ╗“öĄ(sh©┤)ō■(j©┤)é}Äņ×ķ╗∙ĄA(ch©│)Ą─,ŲõūŅĮKöĄ(sh©┤)ō■(j©┤)üĒį┤┼cOLTPę╗śė,Š∙üĒūįĄūīėĄ─öĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)ĪŻOLTP├µī”Ą─╩Ū▓┘ū„╚╦åT║═Ą═īė╣▄└Ē╚╦åT,Č°OLAP├µī”Ą─╩ŪøQ▓▀╚╦åT║═Ė▀īė╣▄└Ē╚╦åT,╦∙╩╣ė├Ą─Įø(j©®ng)ŠC║Ž╠ß¤ÆĄ─Üv╩ĘöĄ(sh©┤)ō■(j©┤)Š∙üĒūįO(sh©©)LTP╦∙ę└┘ćĄ─ĄūīėöĄ(sh©┤)ō■(j©┤)Äņ,OLAPöĄ(sh©┤)ō■(j©┤)▌^ų«OLTPų╗öĄ(sh©┤)ō■(j©┤)ę¬ČÓę╗▓ĮöĄ(sh©┤)ō■(j©┤)ČÓŠS╗»╗“ŅAŠC║Ž╠Ä└ĒĪŻ
öĄ(sh©┤)ō■(j©┤)─Żą═Ą─ĘųŅÉ╚ń▒Ē1╦∙╩ŠĪŻ
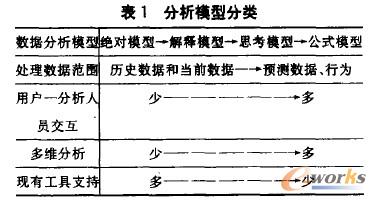
Į^ī”─Żą═(CategoriealModel):ī┘ė┌ņoæB(t©żi)öĄ(sh©┤)ō■(j©┤)Ęų╬÷ĪŻ╦³═©▀^▒╚▌^Üv╩ĘöĄ(sh©┤)ō■(j©┤)ųĄ╗“ąą×ķüĒ├Ķ╩÷▀^╚ź░l(f©Ī)╔·Ą─╩┬īŹĪŻ
ĮŌßī─Żą═(ExegetiealModel):ė├æ¶ę╗Ęų╬÷╚╦åT└¹ė├ŽĄĮy(t©»ng)ęčėąĄ─īė┤╬ŠC║Ž┬ĘÅĮīėīė╝Ü╗»,šę│÷╩┬īŹ░l(f©Ī)╔·Ą─įŁę“ĪŻ
╦╝┐╝─Żą═(ContemplativeModel):ī┘ė┌äėæB(t©żi)öĄ(sh©┤)ō■(j©┤)Ęų╬÷,╦³ų╝į┌šf├„į┌ę╗ŠS╗“ČÓŠS╔Žę²╚ļę╗ĮMŠ▀¾wūā▒P╗“ģóöĄ(sh©┤)║¾īóĢ■░l(f©Ī)╔·╩▓├┤ĪŻ
╣½╩Į─Żą═(FormulaicModel):╩ŪäėæB(t©żi)ąįūŅĖ▀Ą─ę╗ŅÉ─Żą═,▒Ē╩Šį┌ČÓéĆŠS╔Ž,ąĶę¬ę²╚ļ──ą®ūā┴┐╗“ģóöĄ(sh©┤),ęį╝░ę²╚ļ║¾╦∙«a(ch©Żn)╔·Ą─ĮY(ji©”)╣¹ĪŻ
OLAP╩Ūæ¬Ų¾śI(y©©)äėæB(t©żi)Ęų╬÷Č°«a(ch©Żn)╔·Ą─,Ųõ╣”─▄╩Ū═©▀^äō(chu©żng)Į©Īó▓┘ū„Īó╝ż╗Ņ╝░ŠC║ŽüĒūįĮŌßī─Żą═Īó╦╝┐╝─Żą═╝░╣½╩Į─Żą═ųąĄ─ą┼ŽóĪŻ╦³┐╔ęįūRäeūā┴┐ķgĄ─ą┬Ą─╗“▓╗┐╔ŅAų¬Ą─ĻP(gu©Īn)┬ō(li©ón),═©▀^äō(chu©żng)Į©┤¾┴┐Ą─ŠS(ŠC║Ž┬ĘÅĮ)╝░ųĖČ©ŠSķgĄ─ėŗ╦ŃŚl╝■║═▒Ē▀_╩ĮüĒ╠Ä└Ē┤¾┴┐öĄ(sh©┤)ō■(j©┤)ĪŻ
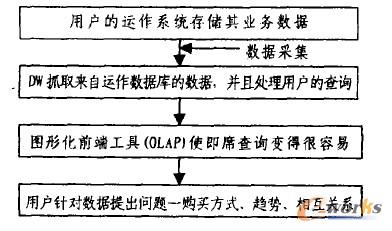
öĄ(sh©┤)ō■(j©┤)é}ÄņŽĄĮy(t©»ng)ė╔╚²▓┐ĘųĮM│╔:öĄ(sh©┤)ō■(j©┤)é}Äņ(Dw)ĪóöĄ(sh©┤)ō■(j©┤)é}Äņ╣▄└ĒŽĄĮy(t©»ng)(DWMS)║═öĄ(sh©┤)ō■(j©┤)é}Äņ╣żŠ▀ĪŻÅ─öĄ(sh©┤)ō■(j©┤)é}Äņ¾wŽĄĮY(ji©”)śŗ(g©░u)(łD2)┐╔ęįŪÕ│■Ąž┐┤ĄĮ▀@╚²▓┐ĘųĄ─ĻP(gu©Īn)ŽĄĪŻ
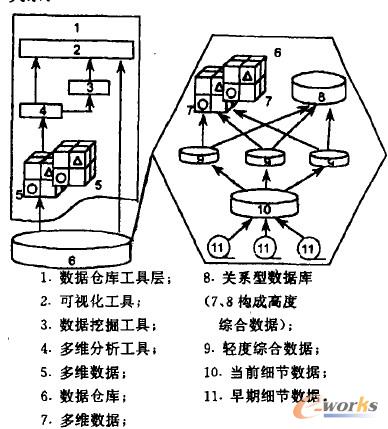
łD2.öĄ(sh©┤)ō■(j©┤)é}Äņ¾wŽĄĮY(ji©”)śŗ(g©░u)
į┌š¹éĆŽĄĮy(t©»ng)ųąöĄ(sh©┤)ō■(j©┤)é}ÄņŠėė┌║╦ą─Ąž╬╗,╩Ūą┼Žó═┌Š“Ą─╗∙ĄA(ch©│);öĄ(sh©┤)ō■(j©┤)é}Äņ╣▄└ĒŽĄĮy(t©»ng)žō┘F╣▄└Ēš¹éĆŽĄĮy(t©»ng)Ą─▀\▐D(zhu©Żn),Ųų°│ą╔ŽåóŽ┬Ą─ū„ė├;Č°öĄ(sh©┤)ō■(j©┤)Ęų╬÷╣żŠ▀ät╩Ūš¹éĆŽĄĮy(t©»ng)░l(f©Ī)ō]ū„ė├Ą─ĻP(gu©Īn)µI,ų╗ėą═©▀^Ė▀ą¦Ą─╣żŠ▀,öĄ(sh©┤)ō■(j©┤)é}Äņ▓┼─▄šµš²░l(f©Ī)ō]öĄ(sh©┤)ō■(j©┤)īÜÄņĄ─ū„ė├ĪŻ
ą┼Žó╠Ä└ĒĄ─ČÓīė┤╬ę¬Ū¾ī¦ų┬┴╦ę╗ĘNą┬Ą─öĄ(sh©┤)ō■(j©┤)Łh(hu©ón)Š│ę╗▓┘ū„öĄ(sh©┤)ō■(j©┤)ÄņODSĄ─Į©┴ó.ODSę╗ĘĮ├µ░³║¼╝Ü╣Ø(ji©”)Ą─Īó«öŪ░╗“ĮėĮ³«öŪ░Ą─öĄ(sh©┤)ō■(j©┤),┐╔▀Mąą┬ō(li©ón)ÖC▓┘ū„ą═╠Ä└Ē;┴Ēę╗ĘĮ├µ,ėų╩Ūę╗ĘN├µŽ“ų„Ņ}Īó╝»│╔Ą─öĄ(sh©┤)ō■(j©┤)Łh(hu©ón)Š│,┐╔ęį▌oų·Ų¾śI(y©©)═Ļ│╔╚š│ŻøQ▓▀ĪŻ
2öĄ(sh©┤)ō■(j©┤)é}Äņį┌¼F(xi©żn)┤·Ų¾śI(y©©)ųąĄ─æ¬ė├
2.1ę╗éĆõN╩█ŽĄĮy(t©»ng)Ą─ĮY(ji©”)śŗ(g©░u)┼c╣żū„įŁ└Ē
łD3.öĄ(sh©┤)ō■(j©┤)ÄņĮY(ji©”)śŗ(g©░u)
Č„═■╣½╦ŠõN╩█ĘųŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)ÄņĮY(ji©”)śŗ(g©░u)╚ńłD3╦∙╩ŠĪŻŲõųą:Ė„Ęų╣½╦ŠĄ─OLTPöĄ(sh©┤)ō■(j©┤)Äņ╬╗ė┌Ė„Ęų╣½╦ŠĄ─Ė▀ąį─▄PCÖC╔Ž,ė╔SQLAnywherĪŻ╣▄└ĒĪŻų„ę¬ė├ė┌Ė„Ęų╣½╦ŠĄ─╚š│Ż╩┬äš╠Ä└Ē,╔µ╝░ĄĮ╚š│ŻõN╩█Īó╗ž┐ŅĪóé}ā”╣▄└ĒĄ╚ųTČÓĘĮ├µĪŻ═©▀^X.25╗“ļŖįÆō▄╠¢╔ŽŠW(w©Żng)┼c┐é▓┐OLTPöĄ(sh©┤)ō■(j©┤)Äņ▀MąąöĄ(sh©┤)ō■(j©┤)Į╗ōQ.õN╩█┐é▓┐OLTPöĄ(sh©┤)ō■(j©┤)Äņ╬╗ė┌╣½╦Š┐é▓┐Ą─öĄ(sh©┤)ō■(j©┤)Ę■äšŲ„╔Ž,ė╔SybaseSQLServor╣▄└ĒĪŻų„ę¬ė├ė┌╣½╦ŠõN╩█┐é▓┐Ą─╚š│Ż╩┬äš╠Ä└Ē,░³└©õN╩█╚╦åTÖn░Ė╣▄└ĒĪóśI(y©©)┐ā┐╝║╦Īó╚š│ŻėŗäØĄ─ųŲČ©ęį╝░õN╩█┐é▓┐ūį╔ĒĄ─õN╩█śI(y©©)䚥╚ĪŻįōöĄ(sh©┤)ō■(j©┤)ÄņĄ─Ąž╬╗║═ū„ė├į┌║▄┤¾│╠Č╚╔ŽŽÓ«öė┌ę╗éĆODSĪŻ
õN╩█öĄ(sh©┤)ō■(j©┤)é}Äņ═Ļš¹Ą─╣żū„▀^│╠╚ńłD4╦∙╩ŠĪŻŲõųąĄ─OLAP╣żŠ▀▓┐Ęųė╔╠ōŠĆ┐“ĮńČ©,▒Ē╩Šį┌įōŽĄĮy(t©»ng)ųą╔ąŪę╚▒Ę”,─┐Ū░į┌▀@éĆ╬╗ų├╔Ž╣żū„Ą─ų╗╩Ūę╗ą®─Żą═╗»Ą─╣żŠ▀ĪŻČ°į┌IT▄ø╝■╩ął÷╔Ž╝║Įø(j©®ng)│÷¼F(xi©żn)┴╦įSČÓīŹė├Ą─OLAP«a(ch©Żn)ŲĘ,═©▀^┐╝▓ņ║═ę²▀M,ŽÓą┼▀@éĆå¢Ņ}į┌▓╗▀hĄ─īóüĒ╝┤┐╔Ą├ĄĮ═Ļ╔ŲĄ─ĮŌøQĪŻ
łD4.DW╣żū„┴„│╠╩ŠęŌ
2.2õN╩█öĄ(sh©┤)ō■(j©┤)é}ÄņĄ─▀ē▌ŗįO(sh©©)ėŗ
į┌õN╩█öĄ(sh©┤)ō■(j©┤)é}ÄņĄ─▀ē▌ŗįO(sh©©)ėŗųą,╬ęéā▓╔ė├┴╦┴„ąąĄ─ąŪą═─Ż╩Į(StarSchema)ĪŻąŪą═─Ż╩Į╩Ū╗∙ė┌ĻP(gu©Īn)ŽĄą═öĄ(sh©┤)ō■(j©┤)Äņ,├µŽ“OLAPĄ─ę╗ĘNČÓŠS╗»Ą─öĄ(sh©┤)ō■(j©┤)ĮM┐ŚĘĮ╩ĮĪŻ
2.2.1ąŪą═─Ż╩ĮĄ─ėąĻP(gu©Īn)╣„─ŅĪŻĻP(gu©Īn)ŽĄą═ĮY(ji©”)śŗ(g©░u)─▄▌^║├Ąž▀mæ¬ČÓŠSöĄ(sh©┤)ō■(j©┤)Ą─▒Ē╩Š║═┤µā”.ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņīóČÓŠSöĄ(sh©┤)ō■(j©┤)ÄņųąĄ─ČÓŠSĮY(ji©”)śŗ(g©░u)äØĘų×ķā╔ŅÉ▒Ē:ę╗ŅÉ╩Ū╩┬īŹ(Fact)▒Ē,ė├üĒ┤µā”╩┬īŹĄ─Č╚┴┐ųĄ╝░Ė„éĆŠSĄ─┤aųĄŻ╗┴Ēę╗ŅÉ╩ŪŠS▒Ē,ī”├┐ę╗éĆŠSüĒšf,ų┴╔┘ėąę╗éĆ▒Ēė├üĒ▒Ż┤µįōŠSĄ─į¬öĄ(sh©┤)ō■(j©┤),╝┤ŠSĄ─├Ķ╩÷ą┼Žó,░³└©ŠSĄ─īė┤╬╝░│╔åTŅÉäeĄ╚ĪŻį┌ŽÓĻP(gu©Īn)╩┬īŹ▒Ēųą,▀@ą®ųĄĢ■č▄╔·│÷įōŠSĄ─┴ąĪŻ╩┬īŹ▒Ē╩Ū═©▀^├┐ę╗éĆŠSĄ─┤aųĄ═¼ŠS▒Ē┬ō(li©ón)ŽĄį┌ę╗ŲĄ─,įōĮY(ji©”)śŗ(g©░u)╝┤▒╗ĘQ×ķ“ąŪą═─Ż╩Į”(╚ńłD5)ĪŻ.
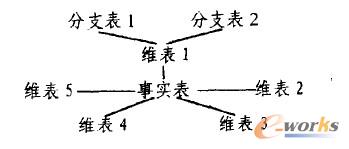
łD5.ąŪą═─Ż╩Į╩ŠęŌłD
ėąĢr,ī”ė┌ā╚(n©©i)▓┐īė┤╬Å═ļsĄ─ŠS,┐╔ęįė├ČÓÅł▒ĒüĒ├Ķ╩÷ę╗éĆŠSĪŻ▒╚╚ń,«a(ch©Żn)ŲĘŠS┐╔ęį▀Mę╗▓ĮäØĘų×ķŅÉą═▒ĒĪóŅü╔½▒ĒĪó╔╠ś╦▒ĒĄ╚,▀@śė,į┌“ąŪ”Ą─ĮŪ╔Žėų│÷¼F(xi©żn)┴╦Ęųų¦ĪŻ▀@ĘNūāĘNĄ─ąŪą═─Żą═▒╗ĘQ×ķ“č®Ų¼─Ż╩Į”(SnowFlakeSehema)ĪŻī”īė┤╬Å═ļsĪó│╔åTŅÉ▌^ČÓĄ─ŠS▓╔ė├ČÓÅł▒ĒüĒ├Ķ╩÷,Č°ī”ė┌▌^×ķ║åå╬Ą─ŠS┐╔ęįė├ę╗Åł▒ĒüĒ├Ķ╩÷ĪŻ
łD6.ąŪą═─Ż╩ĮīŹ└²
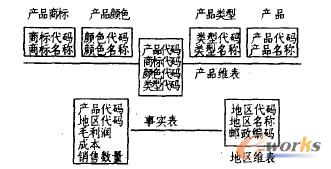
2.2.2Ųõ¾wįO(sh©©)ėŗĘĮ░ĖĪŻ╗∙ė┌õN╩█▓┐Ą─╚š│ŻśI(y©©)äš,╬ęéā▀xō±┴╦õN╩█ĮŅ~┼c╗ž┐ŅĮŅ~▀@ā╔éĆ─╣▒Š╩┬īŹĪŻ▓ó▀xČ©┴╦┼cų«ŽÓĻP(gu©Īn)Ą─╦─éĆŠSę╗ĢrķgĪó╩ął÷(Ąžģ^(q©▒))Īó«a(ch©Żn)ŲĘ║═┐═æ¶.
ė┌╩Ū,╩┬īŹ▒ĒĄ─ĮY(ji©”)śŗ(g©░u)┐╔ęį▒Ē╩Š╚ńŽ┬:
×ķ┴╦╠ß╣®įö▒MĄ─õN╩█śI(y©©)äšą┼Žó,įō╩┬īŹ▒ĒĄ─ĢrķgŠS▓╔ė├┴╦_▒╚▌^ąĪĄ─┴ŻČ╚,Š½┤_ĄĮ├┐╠ņĪŻė╔ė┌┐═æ¶║═╩ął÷╩ŪŠo├▄┬ō(li©ón)ŽĄĄ─,ę“┤╦,įō╩┬īŹ▒ĒĄ─┤¾ąĪāH┼c«a(ch©Żn)ŲĘĪó┐═æ¶ęį╝░ĢrķgĄ─┴ŻČ╚ėąĻP(gu©Īn)ĪŻ
╩ął÷ŠS╩ŪūŅ×ķÅ═ļsĄ─ę╗éĆŠS,įōŠS╩Ūīė┤╬ĮY(ji©”)śŗ(g©░u)Ą─ĪŻŠ▀¾wĘų×ķĘų╣½╦ŠĪóąĪĮM║═╗∙▒Š╩ął÷╚²éĆīė┤╬ĪŻį┌DWųą,╩ął÷ŠS▒Ēų„ę¬ėą╚ńŽ┬ę╗ą®ą┼ŽóŻ║┐╔ęį┐┤│÷,╔Ž▒ĒųąĄ─öĄ(sh©┤)ō■(j©┤)ų╗─▄üĒūįĮy(t©»ng)ėŗŠųĄ──Ļ
Ķb,Ė³ą┬ų▄Ų┌×ķę╗─ĻĪŻ╬ęéāīó╩ął÷ŠS▒ĒĄ─Ģrķg┴ŻČ╚Č©×ķę╗─ĻĪŻ╩ął÷┤·┤a×ķ6╬╗,Ę¹║Žć└Ė±Ą─ĘųČ╬ŠÄ┤aįŁät,Š▀¾węÄ(gu©®)ät╚ńłD7╦∙╩ŠĪŻ
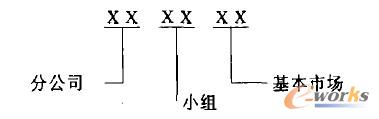
łD7.╩ął÷ŠÄ┤aęÄ(gu©®)ät
š{(di©żo)š¹Ū░║¾Ą─┤·┤a╩Ūę╗ę╗ī”æ¬Ą─Īó«ö╚╗,į┌╩┬īŹ▒ĒųąĄ─╩ął÷┤·┤aę▓▒žĒÜū„ŽÓæ¬Ą─š{(di©żo)š¹,ʱät,Dwīó¤oĘ©╣żū„ĪŻ
«a(ch©Żn)ŲĘŠS▒Ē│²┴╦«a(ch©Żn)ŲĘ┤·┤aĪóĢrķg═Ō,▀Ć║¼ėą├¹ĘQĪóęÄ(gu©®)Ė±Īóå╬ārĪó䮹═(Ų¼ä®Īó╦ÄĖÓĪó╦Äę║)Ą╚ą┼ŽóĪŻ╬ęéāīó«a(ch©Żn)ŲĘŠS▒ĒĄ─Ģrķg┴ŻČ╚ę▓Č©×ķę╗─Ļ.
┐═涊S▒Ēų▒Įė└¹ė├╣½╦ŠõN╩█▓┐Ą─┐═æ¶Ön░Ė,×ķ┴╦▓╗ė░ĒæOLTPŽĄĮy(t©»ng)Ą─ą¦┬╩,DWųąīŹļH▒Ńė├Ą─╩ŪįōÖn░ĖĄ─ę╗éĆ┐ĮžÉ,įō┐ĮžÉČ©Ų┌Ė∙ō■(j©┤)OLTPöĄ(sh©┤)ō■(j©┤)ÄņųąĄ─┐═æ¶Ön░Ė▀Mąą╦óą┬ĪŻ-
┴Ē═Ō,DWųą▀Ć┤µĘ┼ėąõN╩█╚╦åTĪóīŻ╝ęŅÖå¢║═┐═æ¶Ą─ę╗ą®Įy(t©»ng)ėŗą┼ŽóĪŻ▀@ą®ą┼Žó─┐Ū░┐╔╣®▓ķįā║═╔·│╔ŽÓæ¬Ą─ł¾▒Ē,Č°į┌▓╗▀hĄ─īóüĒ,«öDW═žš╣ų„Ņ}Īó╝ė┤¾ęÄ(gu©®)─ŻĢr,▀@ą®öĄ(sh©┤)ō■(j©┤)Š═│╔×ķ│õīŹDWĄ─┘Yį┤ĪŻ
2·3öĄ(sh©┤)ō■(j©┤)▓╔╝»Ą─īŹ¼F(xi©żn)
öĄ(sh©┤)ō■(j©┤)▓╔╝»╩ŪöĄ(sh©┤)ō■(j©┤)é}ÄņĮ©įO(sh©©)ļAČ╬Ą─ĻP(gu©Īn)µI╦∙į┌,ęÓ╩ŪöĄ(sh©┤)ō■(j©┤)é}ÄņŠSūoļAČ╬Ą─ų„ę¬╣żū„ų«ę╗ĪŻį┌öĄ(sh©┤)ō■(j©┤)▓╔╝»Ą─īŹ¼F(xi©żn)ųąėąā╔éĆķgŅ}▒žĒÜėĶęįųžęĢ:ę╗╩Ū▓╔╝»Ą─ų▄Ų┌║═ĢrÖCĪŻČ■╩Ūā¶╗»Īó╝»│╔öĄ(sh©┤)ō■(j©┤),╔·│╔╝āā¶ĪóĮy(t©»ng)ę╗Ą─Ų¾śI(y©©)öĄ(sh©┤)ō■(j©┤)ęĢłDĪŻ
─┐Ū░,öĄ(sh©┤)ō■(j©┤)▓╔╝»Ą─╣żū„╩Ū═©▀^Ū░Č╦æ¬ė├üĒ═Ļ│╔Ą─,Ųõ╝╝ąg(sh©┤)╗∙ĄA(ch©│)╩ŪPowerBuilder╠ß╣®Ą─öĄ(sh©┤)ō■(j©┤)Äņ┐ž╝■“╣▄Ą└”ĪŻöĄ(sh©┤)ō■(j©┤)▓╔╝»─ŻēKĄ─┴„│╠╚ńłD8╦∙╩ŠĪŻ
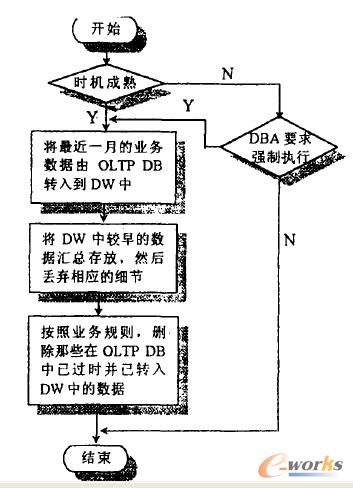
łD8.öĄ(sh©┤)ō■(j©┤)▓╔╝»┴„│╠
ų«╦∙ęįę¬ĮoDBA‘Č■éĆÅŖąął╠(zh©¬)ąąĄ─ÖCĢ■╩Ū╗∙ė┌▀@śėĄ─┐╝æ]:ą┬┼fā╔╠ūŽĄĮy(t©»ng)ļp▄ē▀\ū„Ą─ĢrŲ┌,▒žĒÜį╩įSDBA▓╔╚Īę╗ą®ĘŪ│Ż┤ļ╩®,ęį┤_▒ŻöĄ(sh©┤)ō■(j©┤)▓╔L╝»Ą─▀B└m(x©┤)ąįĪŻ┴Ē═Ō,ęį╔Ž┴„│╠łDųąĖ„▓┐ĘųĄ─Š▀¾w╝Ü╣Ø(ji©”),ė╚Ųõ╩Ū┼cśI(y©©)䚊o├▄ŽÓĻP(gu©Īn)Ą──Ū▓┐Ęųę╗└²╚ńõN╩█║Ž═¼OLTPDBųąĄ─öĄ(sh©┤)ō■(j©┤)║╬Ģr┐╔ęįüGŚē,║╬Ģrįō«öū„ē─┘~╠Ä└Ē,ėųį§śė╗ž╩šē─┘~Ą╚ę╗ąĶę¬į┌ŽĄĮy(t©»ng)įć▀\ąąųąųØuĄžėĶęį├„┤_║═īŹ¼F(xi©żn)Ż¼Ųõųą║▄ČÓĄ─╣żū„▀Ćėą┘ćė┌žöäšĪóā”▀\Īó╚╦╩┬Ą╚▓┐ķTĄ─ų¦│ų┼c║Žū„ĪŻ
2. 4öĄ(sh©┤)ō■(j©┤)Ą─┐╔ęĢ╗»│╩¼F(xi©żn)
ų▒ė^Ą─ĪóČÓśė╗»Ą─öĄ(sh©┤)ō■(j©┤)│╩¼F(xi©żn)╩ŪOLAPŅÉ╣żŠ▀╦∙▒ž▓╗┐╔╔┘Ą─╠žš„ų«ę╗ĪŻę╗░ŃĄžŻ¼╣▄└Ē╚╦åTė╔┐╔ęĢ╗»Ą─Įy(t©»ng)ėŗłDųą─▄ē“Ė³┐ņĄž½@Ą├Ė„ĘN┌ģä▌ą┼ŽóŻ¼ę“┤╦▒M┐╔─▄Ąž╩╣öĄ(sh©┤)ō■(j©┤)│╩¼F(xi©żn)┐╔ęĢ╗»īó╩Ū▓®Ą├╣▄└Ē╚╦åTšJ┐╔Ą─ėąą¦═ŠÅĮĪŻį┌īó║¾Č╦öĄ(sh©┤)ō■(j©┤)▐D(zhu©Żn)╗»×ķ┐╔ęŖĄ─Įy(t©»ng)ėŗłDĄ─▀^│╠ųą▒žĒÜĮŌøQ╚ńŽ┬ā╔éĆĻP(gu©Īn)µIąįå¢Ņ}:
1)ųžĮMöĄ(sh©┤)ō■(j©┤)ĪŻė╔ė┌║¾Č╦öĄ(sh©┤)ō■(j©┤)į┌ĄĮ▀_Įy(t©»ng)ėŗłDų«Ū░▒žĒÜ═©▀^ę╗Č©Ą─▐D(zhu©Żn)ōQ,ą╬│╔ę╗ĘNČÓŠSĄ─öĄ(sh©┤)ō■(j©┤)ęĢłD,ė├OLAPĄ─ąg(sh©┤)šZüĒšfŠ═╩ŪöĄ(sh©┤)ō■(j©┤)Ą─ČÓŠS╗»ę╗░ŃšfüĒ,ųT╚ńõN╩█Īó╔·«a(ch©Żn)ĪóėŗäØĄ╚īæĢr║╬Šo├▄ŽÓĻP(gu©Īn)Ą─öĄ(sh©┤)ō■(j©┤)▒ž╚╗║¼ėąĢrķgŠS,Č°╚╦åTśŗ(g©░u)│╔Īó┐═æ¶Ön░ĖĄ╚öĄ(sh©┤)ō■(j©┤)ät▓╗Ģ■ėąĢrķgŠSĪŻČÓŠS╗»Ą─═ŠÅĮ╚į╚╗╩Ū═©▀^SQLšZŠõüĒųžĮMöĄ(sh©┤)ō■(j©┤)ĪŻ
2)ŠSĄ─▓┘ū„ĪŻų„ę¬ėąŪąŲ¼║═ŪąēK,╩┬īŹ╔ŽŠ═╩Ūī”öĄ(sh©┤)ō■(j©┤)Ą─▀^×VĪŻ«öī”─│ę╗ŠSų╗▒Ż┴¶å╬ę╗ųĄĢr╝┤ĘQ×ķī”įōŠSŪąŲ¼,└²╚ńųĖČ©╚šŲ┌Č■1997/ĪŻ7/24╝┤╩Ūī”░ūŲ┌Ą─ŪąŲ¼ĪŻĘ┤ų«,ųĖČ©╚ń‘┼fŲ┌į┌1997/ĪŻ6/01ĄĮ1997/ĪŻ6/3ĪŻų«ķg”ę╗ŅÉĘČć·Ą─▀^×V╝┤▒╗ĘQ×ķŪąēK.▒žĒÜūą╝ÜĄžĘų╬÷Ė„öĄ(sh©┤)ō■(j©┤)ŠSĄ─┐╔▓┘ū„ąįęį╝░╣╠ėąĄ─ŽÓĻP(gu©Īn)│╠Č╚,ėąĢrĮy(t©»ng)ėŗłDŅÉą═(š█ŠĆłDĪóŚlą╬łDĪóČčĘełDĪó’׳Dęį╝░╔ó³cłDĄ╚)ę▓▓╗Ą├▓╗ū„×ķę╗éĆŠSüĒī”┤²ĪŻ
3öĄ(sh©┤)ō■(j©┤)═┌Š“┼cøQ▓▀ų¦│ųŽĄĮy(t©»ng)
öĄ(sh©┤)ō■(j©┤)═┌Š“╩Ūę╗ĘNÅ─┤¾ą═öĄ(sh©┤)ō■(j©┤)Äņ╗“öĄ(sh©┤)ō■(j©┤)é}Äņųą╠ß╚Īļ[▓žĄ─ŅA£yąįą┼ŽóĄ─ą┬╝╝ąg(sh©┤),╦³─▄═┌Š“│÷öĄ(sh©┤)ō■(j©┤)ķgØōį┌Ą──Ż╩Į,šę│÷ūŅėąārųĄĄ─ą┼ŽóĪŻöĄ(sh©┤)ō■(j©┤)═┌Š“Ą─╦╝Žļę└┘ćė┌ęįŽ┬╚²éĆ╝╝ąg(sh©┤)Ą─ų¦│ų│╠Č╚;‘┤¾ęĢ─ŻöĄ(sh©┤)ō■(j©┤)▓╔╝»Īó╣”─▄ÅŖ┤¾Ą─▓óąąČÓ╠Ä└ĒŲ„ėŗ╦ŃÖCĪóĮ╠ō■(j©┤)═┌Š“╦ŃĘ©.öĄ(sh©┤)ō■(j©┤)═┌Š“┐╔īŹ¼F(xi©żn)Ą─╣”─▄ėą:ūįäėŅAé╚(c©©)┌ģä▌║═ąą×ķ;ūįäė░l(f©Ī)¼F(xi©żn)ęįŪ░╬┤ų¬Ą──Ż╩ĮĪŻ
ļm╚╗öĄ(sh©┤)ō■(j©┤)é}ÄņĪóOLAP║═öĄ(sh©┤)ō■(j©┤)═┌Š“ūŅ│§╩Ūū„×ķ╚²ĘN¬Ü┴óĄ─ą┼Žó╠Ä└Ē╝╝ąg(sh©┤)│÷¼F(xi©żn)Ą─,Ą½╩Ū,ė╔ė┌╦³éāā╚(n©©i)į┌Ą─┬ō(li©ón)ŽĄ║═╗źčaąį,Į±╠ņ,pw+OLAP╩«DMĄ─ĮY(ji©”)śŗ(g©░u)╝║▒╗śI(y©©)ā╚(n©©i)╚╦╩┐╣½šJ×ķ╩ŪDSSĄ─ėąą¦ĮŌøQĘĮ░ĖĪŻ▀@ĘN╚½ą┬Ą─DSSśŗ(g©░u)╝▄Ą─šµš²ęŌ┴xį┌ė┌ųžą┬š╣╩Š┴╦ą┼ŽóĄ─▒Š┘|(zh©¼),▒Ē├„┴╦ą┼ŽóŽĄĮy(t©»ng)Ą─įO(sh©©)ėŗė^─ŅÅ─╠Ä└Ē“ī(q©▒)äėĄĮöĄ(sh©┤)ō■(j©┤)“ī(q©▒)äėĄ─▐D(zhu©Żn)ūāĪŻį┌╬┤üĒĄ─Ģr┤·,ą┼ŽóĄ─ųž³cīó▐D(zhu©Żn)ęŲĄĮöĄ(sh©┤)ō■(j©┤)─Ż╩ĮĘų╬÷,╠Ä└Ē╝╝ąg(sh©┤)ät╩Ūæ¬öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─ąĶę¬Č°«a(ch©Żn)╔·Ą─ĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äšŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äšŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.hanmeixuan.com/
▒Š╬─ś╦Ņ}Ż║öĄ(sh©┤)ō■(j©┤)é}Äņ蹊┐╝░Ųõį┌¼F(xi©żn)┤·Ų¾śI(y©©)ųąĄ─æ¬ė├
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.hanmeixuan.com/html/news/10515516135.html



▀xą═ųąą─")
¾w“×ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")