ę²čį
į┌ć°ļHĮ╚┌╬ŻÖC╦┴┼░Īóć°ļHĖéĀÄ╚šęµ╝ż┴ęĪó«aŲĘąĶŪ¾╚šęµŠ½╝Ü╗»Ą─▒│Š░Ž┬Ż¼Ų¾śIę¬ö[├ō└¦Š│Īóū÷┤¾ū÷ÅŖŻ¼▓ó┘ÅųžĮM│╔×ķę╗ĘNųžę¬Ą─░lš╣æ┬įĪŻ
į┌Ų¾śI═Ļ│╔▓ó┘Å║¾Ż¼ū„×ķŲ¾śI▀\ĀI╣▄└Ē▌d¾wĄ─ą┼ŽóŽĄĮyĄ─š¹║Ž│╔×ķ┴╦▒ž╚╗Ą─ąĶŪ¾Ż¼╚ń║╬ėąą¦Ąž░č▀@ą®Ęų▓╝Ą─Īó«ÉśŗĄ─Īó▀\ąąį┌▓╗═¼▄øė▓╝■ŲĮ┼_╔ŽĄ─ą┼Žó╝»│╔Ż¼▀B═©Ī░ą┼Žó╣┬ŹuĪ▒Ż¼╣▓ŽĒöĄō■Ż¼×ķ╝»łFŲ¾śI╠ß╣®ę╗éĆ═Ļš¹Įyę╗Ą─öĄō■ęĢłDęį│õĘų└¹ė├¼FėąöĄō■┘Yį┤Ż¼│╔×ķ┴╦Ų¾śIĮń╚šęµĻPūóĄ─ą┬å¢Ņ}ĪŻ
1 «ÉśŗöĄō■į┤╝»│╔Ė┼╩÷
«ÉśŗöĄō■╝»│╔─┐Ą─Š═╩Ū╠ß╣®Įyę╗▓ķįāĮė┐┌Ż¼Ų┴▒╬ĄūīėöĄō■į┤Ą─«ÉśŗąįŻ¼╩╣ė├æ¶▓╗▒ž┐╝æ]ĄūīėöĄō■─Ż╩Į┼cĘų▓╝╬╗ų├Ą─▓╗═¼Ą╚å¢Ņ}Ż¼─▄ē“═©▀^ę╗éĆĮyę╗Ą─▓ķįāĮń├µīŹ¼Fī”«ÉśŗöĄō■į┤Ą─═Ė├„įLå¢ĪŻŲõųąĄ─ĻPµI╩Ū╚ń║╬ęįę╗ĘNĮyę╗Ą─öĄō■─Ż╩Į├Ķ╩÷Ė„«ÉśŗöĄō■į┤ųąĄ─öĄō■Ż¼Ų┴▒╬╦³éāĄ─ŲĮ┼_ĪóöĄō■ĮYśŗĄ╚«ÉśŗąįŻ¼īŹ¼FöĄō■Ą─¤o┐p╝»│╔ĪŻ
Į³─ĻüĒŻ¼ČÓĘNöĄō■╝»│╔─Ż╩Į▒╗╠ß│÷Ż¼Ųõųą▒╚▌^ėą┤·▒ĒąįĄ─ėąęįŽ┬ÄūĘN─Ż╩Į:
1) ³cī”³c─Ż╩ĮĪŻ
į┌ā╔ĘN▓╗═¼öĄō■į┤ų«ķgĮ©┴óŽÓ╗ź▐D╗»─Ż╩ĮŻ¼įōĘĮĘ©į┌«ÉśŗöĄō■į┤║▄╔┘Ą─ŪķørŽ┬Ż¼īŹ¼F╝╝ąg▒╚▌^║åå╬Ż¼Ą½ī”«ÉśŗöĄō■į┤▌^ČÓĄ─ŪķørŽ┬Ż¼īŹ¼FŲüĒśO▓╗ĘĮ▒ŃŻ¼ę“×ķī”ė┌ę╗éĆ░³║¼N éĆ«ÉśŗöĄō■į┤Ą─ŽĄĮyŻ¼ąĶę¬Į©┴óĄ─▐D╗»─Ż╩Į┐é║═×ķ: T = N( N ŻŁ 1) Ż¼ŽÓæ¬Ą─Į╗╗źÅ═ļsČ╚×ķ:O( n2 ) ĪŻ▓╔ė├įō─Ż╩ĮŻ¼ŽĄĮy├┐į÷╝ėę╗éĆą┬Ą─öĄō■į┤Ż¼Č╝▒žĒÜ×ķ▀@éĆą┬öĄō■į┤Į©┴óŲ┼cęčėąöĄō■į┤Ą─ČÓĘNįLå¢─Ż╩ĮŻ¼▀@Š═┤¾┤¾ĮĄĄ═┴╦ŽĄĮyĄ─┐╔öUš╣ąįŻ¼įōĘĮĘ©š²▒╗ą┬Ą─öĄō■╝»│╔ĘĮ╩Įų▓Į╚Ī┤·ĪŻ
2) ╝»ųąÅ═ųŲöĄō■─Ż╩ĮĪŻ
öĄō■é}Äņ╩Ū▀@ę╗ĘĮĘ©Ą─Ąõą═┤·▒ĒŻ¼═©▀^ī”«ÉśŗöĄō■į┤Ą─Ęų╬÷┼c▐DōQŻ¼īó├┐éĆ«ÉśŗöĄō■į┤ųąĄ─öĄō■Å═ųŲĄĮę╗éĆĮyę╗Ą─öĄō■é}ÄņųąŻ¼įō─Ż╩ĮĄ─ā׳c╩Ū: ▓╗ŲŲē─įŁėąŽĄĮyŻ¼┐╔╝»│╔ČÓĘNöĄō■į┤║═╔╠śIęÄätŻ¼īŹ¼F┴╦öĄō■Ą─╝»ųą╩Į╣▄└ĒŻ¼öĄō■╝»│╔┘|┴┐║├ĪŻ╚▒³c╩Ū: ¤oĘ©īŹĢrĘ┤ė│öĄō■Ą─ūā╗»Ż¼ų╗─▄Č©Ų┌▀MąąöĄō■Ė³ą┬Ż¼├┐«öėąą┬Ą─öĄō■į┤╝ė╚ļĢrŻ¼╚½Šų─Ż╩Į▒žĒÜųžą┬╔·│╔Ż¼ŽĄĮy┐╔öUš╣ąį▌^▓ŅĪŻ
3) ųąķg╝■─Ż╩ĮĪŻ
ļSų°Ęų▓╝ī”Ž¾╝╝ągĄ─┼dŲŻ¼ųąķg╝■╝╝ągę▓▒╗ÅVĘ║Ąžæ¬ė├ĄĮöĄō■╝»│╔ųąŻ¼Ųõųą▒╚▌^ėą┤·▒ĒąįĄ─ėą╬ó▄øĄ─DCOM ║═OMG Ą─CORBA Ą╚Ż¼╦¹éāČ╝▓╔ė├░³čbĄ─╦╝ŽļŻ¼ęįĮyę╗Ą─Įė┐┌╠ß╣®š{ė├Ę■䚯¼Ų┴▒╬┴╦öĄō■Ą─«ÉśŗąįŻ¼īŹ¼F┴╦öĄō■Ą─═Ė├„ąįįLå¢ĪŻųąķg╝■╝╝ągį┌öĄō■į┤Ą─ūįų╬ąįĪó▓ķįāĄ─īŹĢrąįĪó┼õų├Ą─ņ`╗ŅąįĄ╚ĘĮ├µŻ¼ā׳c▒╚▌^├„’@Ż¼╩Ū─┐Ū░▓╔ė├▒╚▌^ÅVĘ║Ą─╝»│╔─Ż╩Įų«ę╗ĪŻ
4) ╗∙ė┌XML ╝╝ąg─Ż╩ĮĪŻ
XML(eXtensible Markup LanguageŻ¼┐╔öUš╣ś╦ėøšZčį) ╩Ūę╗ĘNį┌Web ╔Ž▒Ē╩Šą┼ŽóĄ─ś╦£╩╬─▒ŠĖ±╩ĮĪŻXMLæ{ĮĶŲõ┴╝║├Ą─┐╔╔ņ┐sąį║═ņ`╗ŅąįŻ¼▓╗āH─▄ē“╠ß╣®ī”┘Yį┤ā╚╚▌Ą─▒Ē╩ŠŻ¼ę▓┐╔╠ß╣®ī”┘Yį┤╦∙Š▀ėąĄ─ĮYśŗą┼ŽóĄ─▒Ē╩ŠŻ¼Ųõš²▒╗ÅVĘ║Ąžæ¬ė├ĄĮįSČÓŅIė“Ż¼ę▓╩ŪĮ³─ĻüĒöĄō■╝»│╔ŅIė“蹊┐¤ß³cų«ę╗ĪŻ
╬─ųąį┌ī”▀@ą®╝»│╔ĘĮĘ©Ęų╬÷Ą─╗∙ĄA╔ŽŻ¼╠ß│÷┴╦ę╗ĘN▓╔ė├SOA ╝▄śŗ╝░═©▀^Web Service ╝╝ągĘŌčböĄō■į┤Ą─▄ø╝■╝▄śŗĪŻ▓óßśī”─┐Ū░Web Ę■äš▀x╚Īų„ę¬╝»ųąė┌UUDI īėŻ¼╗∙▒Š╩Ū═©▀^ĻPµIūųŲź┼õ╗“š▀╗∙ė┌┐“╝▄Ą─ĘĮĘ©īŹ¼FŻ¼ę²╚ļšZ┴xWeb╝╝ągŻ¼üĒĮŌøQįŁĘĮĘ©▓ķ£╩┬╩śOŲõĄ═Ž┬Ą─▓╗ūŃĪŻį┌šZ┴xWeb ųąŻ¼├Ķ╩÷Ę■䚥─ą┼ŽóŠ∙▒╗┘xėĶ╠žČ©Ą─šZ┴xŻ¼─▄▒╗ėŗ╦ŃÖC└ĒĮŌ║═╠Ä└ĒŻ¼▀@╩╣Ą├╗∙ė┌šZ┴xĄ─Web Ę■䚥─░l¼F│╔×ķ┐╔─▄Ż¼śO┤¾Ąž╠ßĖ▀┴╦▓ķ£╩┬╩ĪŻ
2 ╗∙ė┌SOAĄ─ŽĄĮy╝»│╔╝▄śŗįOėŗ
├µŽ“Ę■äš╝▄śŗ( Service Oriented ArchitectureŻ¼SOA)Ą─Ė┼─Ņ╩ŪGartnerGroupŻ¼ė┌1996 ─Ļ╠ß│÷ĪŻĻPė┌SOAŻ¼─┐Ū░╔ą╬┤ėąę╗éĆĮyę╗Ą─ĪóśIĮńÅVĘ║Įė╩▄Ą─Č©┴xĪŻę╗░ŃšJ×ķ: SOAŻ¼├µŽ“Ę■äš╝▄śŗ╩Ūę╗éĆĮM╝■─Żą═Ż¼╦³īóæ¬ė├│╠ą“Ą─▓╗═¼╣”─▄å╬į¬( ĘQ×ķĘ■äš) Ż¼═©▀^Ę■äšķgČ©┴x┴╝║├Ą─Įė┐┌║═Ų§╝s┬ōŽĄŲüĒĪŻĮė┐┌▓╔ė├ųą┴óĄ─ĘĮ╩ĮČ©┴xŻ¼¬Ü┴óė┌Š▀¾wīŹ¼FĘ■䚥─ė▓╝■ŲĮ┼_Īó▓┘ū„ŽĄĮy║═ŠÄ│╠šZčįŻ¼╩╣Ą├śŗĮ©į┌▀@śėĄ─ŽĄĮyųąĄ─Ę■äš┐╔ęį╩╣ė├Įyę╗║═ś╦£╩Ą─ĘĮ╩Į▀Mąą═©ą┼ĪŻ
Web Service ╩Ūę╗ĘN┼cŲĮ┼_¤oĻPĄ─Ī░ūį░³║¼Ą─Īóūį├Ķ╩÷Ą─ĪóĮM╝■╗»Ą─æ¬ė├│╠ą“Ī▒Ż¼╩Ūę╗ĘNį┌Internet ╔Ž╩╣ė├Ą─╚½ą┬Ą─Ęų▓╝╩Įėŗ╦Ń╝╝ągĪŻ
ŽĄĮy╩ūŽ╚░┤ššWeb Services ś╦£╩░čöĄō■ĘŌčbŻ¼ęįĮŌøQŲĮ┼_«ÉśŗĪóĮYśŗ«Éśŗ┼cĘų▓╝ąįĄ╚å¢Ņ}Ż¼▒Š¾wĘ■äšīė╝░šZ┴xīė▀Mę╗▓Į░čöĄō■ĮŌ╬÷┼cųžĮMŻ¼ūŅ║¾ęį╠ōöMęĢłD╗“ęĢłD╝»║ŽĄ─ą╬╩ĮŻ¼╠ß╣®Įoæ¬ė├īėĪŻŲõ╠ž³c╩Ū─▄ē“ĮŌøQĖ„ĘN«Éśŗąįå¢Ņ}Ż¼Ūęųąķg▀^│╠ųą▓╗┤µā”╚╬║╬«ÉśŗöĄō■ÄņųąĄ─īŹļHöĄō■Ż¼īŹ¼F┴╦öĄō■Ą─īŹĢr«Éśŗ╝»│╔ĪŻš¹éĆŽĄĮy╝▄śŗ╚ńłD1 ╦∙╩ŠŻ¼ų„ę¬░³└©ęįŽ┬5 éĆīė┤╬:
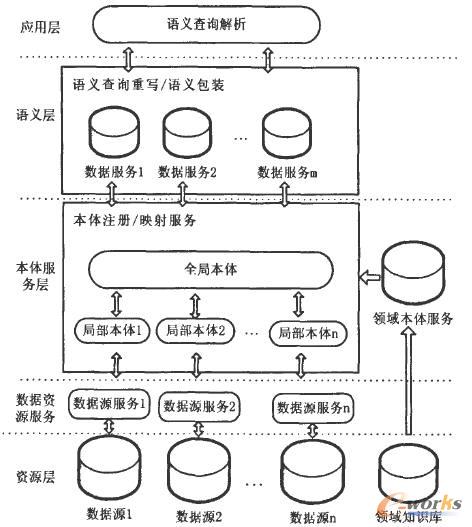
łD1 ╗∙ė┌SOA Ą─«ÉśŗöĄō■╝»│╔┐“╝▄łD
1) æ¬ė├īėĪŻ
╠ß╣®Įyę╗Ą─▓ķįāĮė┐┌Ż¼ė├æ¶┐╔ęį═Ė├„ĄžįLå¢ĄūīėöĄō■Ż¼Č°▓╗▒žų¬Ą└öĄō■Ą─╬’└Ē╬╗ų├┼cöĄō■Ą─«ÉśŗąįŻ¼ī”ė├æ¶Č°čįŻ¼Š═Ž±įLå¢å╬öĄō■į┤ę╗śė║åå╬ĪŻ
2) šZ┴xīėĪŻ
īóšZ┴x▓ķįāĮY╣¹┼cšZ┴xą┼ŽóĮY║Ž░³čb×ķšZ┴xą╬╩ĮĄ─ĮY╣¹╝»Ż¼▓óęįĘ■䚥─ą╬╩Į╠ß╣®Įoæ¬ė├īėš{ė├ĪŻ
3) ▒Š¾wĘ■äšīėĪŻ
▒Š¾wĘ■äš░³└©ŅIė“▒Š¾wĘ■äš┼cŽĄĮy▒Š¾wĘ■äšā╔▓┐ĘųĪŻŅIė“▒Š¾w╩ŪöĄō■─Ż╩ĮĄ─Įyę╗▒Ē▀_─Żą═║═ŅIė“ągšZś╦£╩ĪŻŅIė“▒Š¾wė╔ŅIė“īŻ╝ęČ©┴xŻ¼öĄō■╠ß╣®š▀ąĶę¬░čūį╝║Ą─öĄō■╝»┼cŅIė“▒Š¾w▀Mąąė│╔õą╬│╔ŽĄĮy▒Š¾wĪŻŽĄĮy▒Š¾w┼cŽĄĮyĄ─ČÓéĆĮŪ╔½┤µį┌ų°ŽÓ╗ź┬ōŽĄŻ¼╩Ūš¹éĆŽĄĮyšZ┴x╝»│╔Ą─║╦ą─ĪŻ
4) öĄō■┘Yį┤Ę■äšīėĪŻ
ŠSūo╦∙ėą┼cöĄō■┘Yį┤ŽÓĻPĄ─ą┼ŽóĪŻ╦∙ėąų▒Įė┼cöĄō■┘Yį┤ėąĻPĄ─▓┘ū„Č╝ė╔▀@éĆĮM╝■╠ß╣®ų¦│ųĪŻ▀@ą®▓┘ū„░³└©öĄō■┘Yį┤Ą─äėæB░l▓╝Īó╝ė╚ļĪó═╦│÷Īóą┼ŽóŠSūoĪóą┼Žó▓ķįāĪóöĄō■Ą─ī¦╚ļ║═▓ķįāĄ╚ĪŻīŹļH╔ŽŻ¼▀@éĆ║╦ą─ĮM╝■×ķĖ„ĘN▓╗═¼ŅÉą═Ą─öĄō■┘Yį┤╠ß╣®┴╦Įyę╗Ą─Įė┐┌Ż¼╩╣Ą├▓ķįā─▄ē“┐ńįĮ▓╗═¼Ą─öĄō■┘Yį┤ŅÉą═ĪŻŽĄĮyŲĮ┼_į┌Ęų╬÷ė├æ¶Ą─▓ķįāšłŪ¾ĢrŻ¼š²╩ŪÅ─▀@éĆöĄō■┘Yį┤Ę■äšųą½@╚ĪöĄō■┘Yį┤Ą─ŽÓæ¬ą┼ŽóŻ¼▀MČ°╔·│╔▓ķįāėŗäØŻ¼▓ó░č▓ķįāĘų┼╔ĄĮĖ„éĆöĄō■┘Yį┤ĪŻ
5) ┘Yį┤īėĪŻ
Ų¾śI▀z┴¶╝░ą┬Į©Ą─Ė„ĘNöĄō■┘Yį┤ĪŻ
3 ĻPµI─ŻēKĄ─įOėŗ
3Ż«1 ▒Š¾wÄņ
Ų│§▒Š¾w╩Ūš▄īWĘČ«Ā╔ŽĄ─ę╗éĆĖ┼─ŅŻ¼StuderĄ╚═©▀^蹊┐šJ×ķĪ░▒Š¾w( ontology) ╩Ū╣▓ŽĒĖ┼─Ņ─Żą═Ą─├„┤_Ą─ą╬╩Į╗»ęÄĘČšf├„Ī▒Ż¼Ųõ░³║¼4 īė║¼┴x: Ė┼─Ņ─Żą═Īó├„┤_Īóą╬╩Į╗»║═╣▓ŽĒĪŻ▒Š¾w╩Ūī”ę╗éĆ┐═ė^┤µį┌ŽĄĮyĄ─ĮŌßī╗“šf├„Ż¼├Ķ╩÷Ą─╩Ūę╗éĆ┐═ė^ŽĄĮyĄ─│ķŽ¾▒Š┘|ĪŻš²╩Ūė╔ė┌▒Š¾wī”┐═ė^¼FīŹĄ─ÅŖ┤¾├Ķ╩÷─▄┴”Ż¼▒Š¾w▀@ę╗Ė┼─Ņ▒╗ÅVĘ║Ąžę²╚ļėŗ╦ŃÖCŅIė“Ż¼ė├üĒĮŌøQę╗ą®┼c¼FīŹ╩└ĮńŽÓĻPĄ─Ż¼ąĶę¬ī”¼FīŹ╩┬╬’▀Mąą│ķŽ¾├Ķ╩÷Ą─ŅIė“ĪŻį┌öĄō■╝»│╔▀^│╠ųąŻ¼╚╦éāąĶę¬ī”┤¾┴┐Ą─öĄō■▀Mąą▀ē▌ŗ├Ķ╩÷Ż¼ęįĮę╩ŠŲõųąĄ─ŽÓ╗źĻPŽĄŻ¼Ž¹│²šZ┴xĄ─«ÉśŗąįĄ╚å¢Ņ}Ż¼▒Š¾wĄ─│÷¼Fš²║├ĮŌøQ┴╦▀@ę╗å¢Ņ}ĪŻį┌öĄō■╝»│╔ŅIė“ųąŻ¼═©▀^ī”öĄō■Ą─ć└Ė±Č©┴x║═Į©┴óöĄō■ų«ķgĄ─ĻPŽĄŻ¼Įę╩ŠöĄō■ų«ķg╣▓═¼šJ┐╔Ą─Īó┐╔╣▓ŽĒĄ─ų¬ūRŻ¼▀_ĄĮĮŌøQšZ┴x«Éśŗąįå¢Ņ}Ą──┐Ą─ĪŻ
▀@└’Ż¼ĮĶė├├Ķ╩÷▀ē▌ŗ( DLŻ¼Description Logic) ųąī”TBox ║═ABox Ą─Č©┴xą╬╩ĮŻ¼üĒśŗĮ©▒Š¾wÄņĪŻ
1) ╝»║ŽC: Ė┼─Ņ╝»Ż¼ŅIė“ų¬ūRųąūŅ╗∙▒ŠūŅę╗░ŃĄ─Ė┼─Ņą╬│╔ūŅ│§Ą─Ė┼─Ņ╝»C;
2) ╝»║ŽR: ĻPŽĄ╝»Ż¼Ė┼─Ņų«ķgę╗ą®ūŅ╗∙▒ŠĄ─ĻPŽĄą╬│╔ĻPŽĄ╝»R;
3) ░č1) ųąą╬│╔Ą─Ė┼─Ņ╝»C ║═2) ųą╔·│╔Ą─ĻPŽĄ╝»RŻ¼═©▀^▀ē▌ŗĻPŽĄ▀\╦ŃŻ¼╔·│╔ą┬Ą─Ė┼─ŅŻ¼▓ó░čą┬╔·│╔Ą─Ė┼─Ņ╠Ē╝ėĄĮ╝»║ŽC;
4) ųžÅ═Ą┌╚²▓ĮŻ¼ų▒ĄĮ╝»║ŽC ūŃē“Ė▓╔wæ¬ė├ųąĄ─ŅIė“ų¬ūRŻ¼╝»║ŽC Š═╩Ū╦∙ꬥ─TBox;
5) ė├īŹ└²╝»üĒ╠Ņ│õĖ┼─Ņ╝»C ųąĄ─Ė┼─Ņ║═ĻPŽĄ╝»RųąĄ─ĻPŽĄŻ¼▀@Ģrė├ė┌▒Ē╩Š╠Ņ│õ╩ĮūėĄ─╚½¾wŠ═ą╬│╔AboxĪŻ
▀@└’TBox ┼cABox Š═╩Ū▒ŠŽĄĮyųąę¬ė├ĄĮĄ─ŅIė“▒Š¾w┼cŽĄĮy▒Š¾wĪŻ
Ž┬├µšf├„ę╗Ž┬▒Š¾wĄ─äōĮ©▀^│╠Ż¼¼Fėąé}ÄņA ┼cé}ÄņBŻ¼ŲõĮYśŗ╚ńłD2 ╦∙╩ŠĪŻ
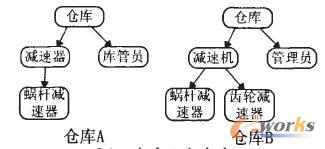
łD2 é}ÄņA ┼cé}ÄņB
Ųõ╔µ╝░ĄĮĄ─╗∙▒ŠĖ┼─Ņ╝░╦¹éāų«ķgĄ─ĻPŽĄŻ¼ė├MyoMyo Naing ╠ß│÷▓╔ė├┴∙į¬ĮMĘ©┐╔▒Ē╩Š×ķ{ CŻ¼ACŻ¼H} Ż¼Ųõųą:
é}ÄņA:
C = { é}ÄņĪó£p╦┘Ų„ĪóÄņ╣▄åTĪó╬üŚU£p╦┘Ų„}
AC = { ╣▄└Ē( Äņ╣▄åTŻ¼£p╦┘Ų„) Ż¼┤µĘ┼Ąž³c( £p╦┘Ų„Ż¼é}Äņ) Ż¼╣żū„Ąž³c( Äņ╣▄åTŻ¼é}Äņ) }
H = { ( ╬üŚU£p╦┘Ų„Ż¼£p╦┘Ų„) Ż¼£p╦┘Ų„ĪŁ}é}ÄņB:
C = { é}ÄņĪó£p╦┘ÖCĪó╣▄└ĒåTĪó╬üŚU£p╦┘Ų„Īó²X▌å£p╦┘Ų„}
AC = { ╣▄└Ē( ╣▄└ĒåTŻ¼£p╦┘ÖC) Ż¼┤µĘ┼Ąž³c( £p╦┘ÖCŻ¼é}Äņ) Ż¼╣żū„Ąž³c( ╣▄└ĒåTŻ¼é}Äņ) }
H = { ( ╬üŚU£p╦┘Ų„Ż¼£p╦┘ÖC) Ż¼( ²X▌å£p╦┘Ų„Ż¼£p╦┘ÖC) Ż¼£p╦┘ÖCĪŁ}
═©▀^š{čą╝░┼cŲ¾śIŽÓĻPīŻ╝ę╣┤═©Ż¼┐╔Ą├ĄĮ╗∙ė┌łD3 ▒Ē╩ŠĄ─ŅIė“▒Š¾wĪŻ
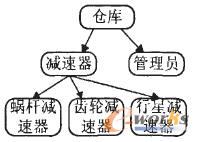
łD3 ŅIė“▒Š¾w
ė├Myo Myo Naing ╠ß│÷▓╔ė├┴∙į¬ĮMĘ©┐╔▒Ē╩Š×ķ{ CŻ¼ACŻ¼H} Ż¼Ųõųą:
C = { é}ÄņĪó£p╦┘Ų„Īó╣▄└ĒåTĪó╬üŚU£p╦┘Ų„Īó²X▌å£p╦┘Ų„}
AC = { ╣▄└Ē( ╣▄└ĒåTŻ¼£p╦┘Ų„) Ż¼┤µĘ┼Ąž³c( £p╦┘Ų„Ż¼é}Äņ) Ż¼╣żū„Ąž³c( ╣▄└ĒåTŻ¼é}Äņ) }
H = { ( ╬üŚU£p╦┘Ų„Ż¼£p╦┘Ų„) Ż¼( ²X▌å£p╦┘Ų„Ż¼£p╦┘Ų„) Ż¼£p╦┘Ų„ĪŁ}
ė├é}ÄņA ┼cé}ÄņB ųąĄ─Ė┼─Ņ╝»CAĪóCB╚ź╠Ņ│õŅIė“▒Š¾wĖ┼─Ņ╝»C ųąĄ─Ė┼─ŅŻ¼ė├é}ÄņA ┼cé}ÄņB ųąĄ─ĻPŽĄ╝»RAĪóRB╚ź╠Ņ│õŅIė“▒Š¾wųąĄ─ĻPŽĄ╝»RŻ¼▓óŪÕ│²ČÓėÓĖ┼─Ņ┼cĻPŽĄŻ¼Š═Ą├ĄĮŽĄĮy▒Š¾wŻ¼╚ńłD4 ╦∙╩ŠĪŻ
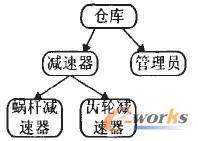
łD4 ╚½Šų▒Š¾w
ė├OWL šZčį┐╔▒Ē╩Š×ķ:
Ż╝ owl: Class rdf: ID = " é}Äņ" ŻŠ Ż╝ /owl: Class ŻŠ
Ż╝ owl: Class rdf: ID = " £p╦┘Ų„" ŻŠ Ż╝ /owl: Class ŻŠ
Ż╝ owl: Class rdf: ID = " ╣▄└ĒåT" ŻŠ Ż╝ /owl: Class ŻŠ
Ż╝ owl: Class rdf: ID = " ╬üŚU£p╦┘Ų„" ŻŠ
Ż╝ rdfs: subClass ŻŠ
Ż╝ owl: Class rdf: about = " #£p╦┘Ų„" / ŻŠ Ż╝ /owl: Class ŻŠ
Ż╝ /rdfs: subClass ŻŠ
Ż╝ /owl: Class ŻŠ
Ż╝ owl: Class rdf: ID = " ²X▌å£p╦┘Ų„" ŻŠ
Ż╝ rdfs: subClass ŻŠ
Ż╝ owl: Class rdf: about = " #£p╦┘Ų„" / ŻŠ
Ż╝ /owl: Class ŻŠ
Ż╝ /rdfs: subClass ŻŠ
Ż╝ /owl: Class ŻŠ
Ż╝ owl: OProperty rdf: ID = " ╣▄└Ē" ŻŠ
Ż╝ rdfs: domain rdf: resource = " #╣▄└ĒåT" / ŻŠ
Ż╝ rdfs: range rdf: resource = " #£p╦┘Ų„" / ŻŠ
Ż╝ /owl: OProperty ŻŠ
Ż╝ owl: OProperty rdf: ID = " ┤µĘ┼Ąž³c" ŻŠ
Ż╝ rdfs: domain rdf: resource = " #£p╦┘Ų„" / ŻŠ
Ż╝ rdfs: range rdf: resource = " #é}Äņ" / ŻŠ
Ż╝ /owl: OProperty ŻŠ
Ż╝ owl: OProperty rdf: ID = " ╣żū„Ąž³c" ŻŠ
Ż╝ rdfs: domain rdf: resource = " #Äņ╣▄åT" / ŻŠ
Ż╝ rdfs: range rdf: resource = " #é}Äņ" / ŻŠ
Ż╝ /owl: OProperty ŻŠ
3Ż«2 ▓ķįā─ŻēK
▓ķįā─ŻēK╩Ūų▒Įė├µŽ“öĄō■╩╣ė├š▀Ą─Įė┐┌Ż¼žōž¤īóė├æ¶╠ßĮ╗Ą─▓ķįāĘųĮŌ│╔ßśī”Ė„Ęų▓╝öĄō■Ą─ūė▓ķįāŻ¼▓ó╠ßĮ╗ĮoŽÓæ¬Ą─öĄō■į┤Ę■äš─ŻēKĪŻšZ┴x▓ķįāĘ■äš╩Ūš¹éĆŽĄĮyĄ─ĻPµI▓┐╝■ų«ę╗Ż¼ŲõĮYśŗ╚ńłD5 ╦∙╩ŠŻ¼╦³ėų┐╔į┘╝ÜĘų×ķ:
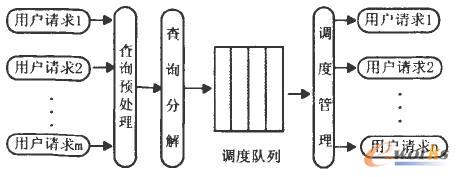
łD5 ▓ķįā─ŻēKŽĄĮyĮYśŗ
1) ▓ķįā╔·│╔─ŻēKĪŻ
▓ķįā╔·│╔─ŻēKų„꬞ōž¤▓ķįāŅA╠Ä└ĒĪŻĮė╩šė├æ¶╠ßĮ╗Ą─Ė„ĘN▓ķįāšłŪ¾Ż¼▓ó▀Mąą▒žę¬Ą─“×ūC╠Ä└ĒŻ¼░³└©“×ūC▒Š¾wĄ─ėąą¦ąįĪó“×ūCöĄō■┘Yį┤Ą─┐╔ė├ąįĪó“×ūC▓ķįāĄ─║ŽĘ©ąį║══Ļš¹ąįĄ╚ę╗ŽĄ┴ą╣żū„Ż¼ūŅ║¾Ė∙ō■╚½Šų▒Š¾wĄ─Č©┴xīóė├涚łŪ¾▐D╗»×ķĮyę╗Ą─Īó┐╔ūRäeĄ─╚½Šų▓ķįāšZŠõĪŻ
2) ▓ķįāĮŌ╬÷─ŻēKĪŻ
žōž¤Ęų╬÷šZ┴x▓ķįā▓ó▀MąąĘųĮŌ╣żū„ĪŻīóÅ─▓ķįā╔·│╔─ŻēKĮė╩šĄĮĄ─šZ┴x▓ķįāšZŠõŻ¼Ė∙ō■╚½Šų▒Š¾w╗“Šų▓┐▒Š¾wųąČ©┴xĄ─▒Š¾wą┼Žó╔·│╔ŽÓæ¬Ą─▓ķįāšZŠõĪŻ▀@ą®▓ķįāšZŠõ├Ķ╩÷┴╦╦∙ę¬▓ķįāĄ─öĄō■üĒūį──ą®öĄō■┘Yį┤ĪóŠ▀¾wĄ─▒Ē├¹ĪóöĄō■┴ąĪó▓ķįāŚl╝■ĪóĖ„éĆöĄō■▒Ēų«ķgĄ─▀BĮėĻPŽĄęį╝░Ė„Śl▓ķįāėŗäØų«ķgĄ─ł╠ąąę└┘ćĻPŽĄĪŻ
3) ▓ķįāł╠ąą─ŻēKĪŻ
ŲõŠ▀¾w░³└©ĻĀ┴ą╣▄└Ē║═š{Č╚╣▄└Ēā╔éĆūė─ŻēKŻ¼╩ūŽ╚Įė╩šüĒūį▓ķįāĮŌ╬÷─ŻēKųąĄ─▓ķįāšZŠõŻ¼ąą│╔ę╗éĆĻĀ┴ąŻ¼╚╗║¾š{Č╚╣▄└Ē─ŻēK╗∙ė┌FIFO( Ž╚▀MŽ╚│÷) š{Č╚▓▀┬įŻ¼Ęų╬÷Ųõī┘ąįģóöĄŻ¼▓ó╦══∙ŽÓæ¬Ą─öĄō■į┤Ę■äš─ŻēKł╠ąąŠ▀¾w▓┘ū„ĪŻ
3Ż«3 öĄō■╚┌║Ž─ŻēK
īóįŁūė▓ķįāėŗäØĄ─ł╠ąąĮY╣¹▀Mąą╚┌║ŽŻ¼Ą├ĄĮĘ¹║Žė├æ¶ę¬Ū¾Ą─ūŅĮK▓ķįāĮY╣¹╝»ĪŻė╔öĄō■į┤Ę■äš─ŻēKĘĄ╗žĄ─ĮY╣¹╝»Ż¼░³║¼┴╦Ė„éĆ▓╗═¼öĄō■į┤Ą─▓ķįāĮY╣¹Ż¼▀@ą®▓ķįāĮY╣¹ė╔ę╗ą®öĄō■ąąĮM│╔Ż¼ī”▀@ą®öĄō■ąą▒žĒÜ▀MąąŽÓæ¬Ą─┼ąöÓ╚┌║ŽŻ¼▓┼─▄Ą├ĄĮ╦∙ąĶĮY╣¹Ż¼öĄō■╚┌║Žų„ę¬ėąęįŽ┬╚²ĘNŪķør:
1) ųžÅ═öĄō■ąąŻ¼║Ž▓ó▀^×VŻ¼ĘĄ╗ž╬©ę╗ųĄ;
2) öĄō■ąąąąöĄō■Ą─╚┌║ŽĪŻę¬▓ķįā£p╦┘Ų„Ą─Äņ┤µŪķørŻ¼ĘųÅS1 ┼cĘųÅS2 ĘĄ╗žĄ─ĮY╣¹ĘųłD╚ń▒Ē1Īó2 ╦∙╩ŠŻ¼ätūŅ║¾öĄō■╚┌║Ž║¾Ą─ĮY╣¹╚ń▒Ē3 ╦∙╩Š;

▒Ē1 ĘųÅS1 ĘĄ╗žĮY╣¹

▒Ē2 ĘųÅS2 ĘĄ╗žĮY╣¹

▒Ē3 öĄō■╚┌║Ž║¾Ą─ĮY╣¹
3) öĄō■ąą┴ąöĄō■Ą─╚┌║ŽĪŻ╚ń╣¹2 ąąöĄō■│²ĻPµIī┘ąįĮM═ŌĄ─ī┘ąį╚ĪųĄ▓╗═¼Ż¼Ė∙ō■ąĶę¬ätę¬░čę╗ąąöĄō■ųąĄ─▓╗ŽÓ═¼ī┘ąįųĄ▀BĮėĄĮ┴Ēę╗ąąöĄō■Ą──®╬▓│╔×ķ═¼ę╗ąąöĄō■▌ö│÷ĪŻ
4 ĮY╩°šZ
ļSų°ą┼Žó╗»░lš╣╝░Ų¾śIęÄ─ŻĄ─▓╗öÓöU┤¾Ż¼Ī░ą┼Žó╣┬ŹuĪ▒å¢Ņ}ęčĮø│╔×ķūĶĄKŲ¾śIą┼Žó╗»▀M│╠Ą─ų„ę¬ę“╦žŻ¼öĄō■╝»│╔╩ŪĮŌøQĪ░ą┼Žó╣┬ŹuĪ▒å¢Ņ}Ą─Ė∙▒ŠĘĮĘ©ĪŻ╬─ųą═©▀^ī”▒╚ęčėąöĄō■╝»│╔ĘĮĘ©Ż¼ĮY║Ž¼F┤·Ų¾śIĄ─Š▀¾wæ¬ė├ąĶŪ¾Ż¼╠ß│÷┴╦ę╗ĘN╗∙ė┌SOA ╝▄śŗ║═▒Š¾w╝╝ągĄ─öĄō■╝»│╔┐“╝▄ĪŻŽĄĮyīó«ÉśŗöĄō■į┤ęįWeb Service Ą─ą╬╩Į▀MąąĘŌčbŻ¼═¼Ģrę²╚ļ▒Š¾w╝╝ągŻ¼└¹ė├▒Š¾w├Ķ╩÷ŅIė“Ė┼─ŅĄ─ā×ä▌Ż¼▌^║├ĮŌøQ┴╦öĄō■╝»│╔ųąöĄō■Ą─«Éśŗąįå¢Ņ}Ż¼īŹ¼F┴╦öĄō■įLå¢Ą─═Ė├„ąįĪŻ
Ž┬ę╗▓ĮĄ─ų„ę¬╣żū„╩Ū: Ė─▀M▒Š¾wĄ─╔·│╔ęÄätŻ¼£p╔┘╚╦╣żĖ╔ŅAŻ¼╠ßĖ▀▒Š¾w╔·│╔Ą─ūįäė╗»│╠Č╚ĪŻ
║╦ą─ĻPūóŻ║═ž▓ĮERPŽĄĮyŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śIäšŅIė“ĪóąąśIæ¬ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śIäš╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśIäšŅIė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śIĻPūóERP╣▄└ĒŽĄĮyĄ─║╦ą─ŅIė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śIą┼Žó╗»Į©įO╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠWhttp://m.hanmeixuan.com/
▒Š╬─ś╦Ņ}Ż║╗∙ė┌SOAĄ─«ÉśŗöĄō■╝»│╔▄ø╝■╝▄śŗ蹊┐
▒Š╬─ŠWųĘŻ║http://m.hanmeixuan.com/html/solutions/1401932670.html