Ż▒ ę²čį
ūŅĮ³Äū─ĻŻ¼öĄ(sh©┤)ō■(j©┤)é}Äņėų│╔×ķöĄ(sh©┤)ō■(j©┤)╣▄└Ē蹊┐Ą─¤ß³cŅI(l©½ng)ė“Ż¼ų„ę¬įŁę“╩Ū«ö(d©Īng)Ū░öĄ(sh©┤)ō■(j©┤)é}ÄņŽĄĮy(t©»ng)├µ┼RĄ─ąĶŪ¾į┌öĄ(sh©┤)ō■(j©┤)į┤ĪóąĶ╠ß╣®Ą─öĄ(sh©┤)ō■(j©┤)Ę■äš(w©┤)║═╦∙╠ÄĄ─ė▓╝■Łh(hu©ón)Š│Ą╚ĘĮ├µ░l(f©Ī)╔·┴╦Ė∙▒ŠąįĄ─ūā╗»Ż©įöęŖŻ▒Ż«Ż▒╣Ø(ji©”)Ż®Ż¼▀@ą®ūā╗»╩Ū╬ęéā▒žĒÜ├µī”Ą─ĪŻ
▒Š╬─į┌┤¾öĄ(sh©┤)ō■(j©┤)Ą─Ģr┤·▒│Š░Ž┬Ż¼ī”¼F(xi©żn)ėąöĄ(sh©┤)ō■(j©┤)é}ÄņŽĄĮy(t©»ng)īŹ¼F(xi©żn)ĘĮ░ĖŻ©ų„ę¬╩Ū▓óąąöĄ(sh©┤)ō■(j©┤)Äņ║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕŻ®▀M(j©¼n)ąąųžą┬īÅęĢŻ¼Ų┌═¹─▄×ķįO(sh©©)ėŗØMūŃĢr┤·ąĶŪ¾Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņŽĄĮy(t©»ng)╠ß╣®└Ēšōģó┐╝Ż¼Ž▐ė┌Ų¬Ę∙Ż¼▒Š╬─ų„ę¬ĻP(gu©Īn)ūó▓╗═¼öĄ(sh©┤)ō■(j©┤)é}ÄņīŹ¼F(xi©żn)ĘĮ░ĖĄ─ų„¾w╝▄śŗ(g©░u)╝░Ųõ╚▒Ž▌į┌ūŅĮ³Äū─ĻĄ─Ė─▀M(j©¼n)ŪķørŻ¼ę└ō■(j©┤)蹊┐┴óūŃ³cĄ─▓╗═¼Ż¼▒Š╬─īóįōŅI(l©½ng)ė“Ą─蹊┐Üw×ķ╚²┤¾ŅÉŻ║▓óąąöĄ(sh©┤)ō■(j©┤)ÄņĪóŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĪó▓óąąöĄ(sh©┤)ō■(j©┤)Äņ║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╝╝ąg(sh©┤)Ą─╗ņ║Ž╝▄śŗ(g©░u)Ż¼ŲõųąĄ┌╚²ŅÉ蹊┐ėų╝Ü(x©¼)Ęų×ķŻ║▓óąąöĄ(sh©┤)ō■(j©┤)Äņų„ī¦(d©Żo)ą═ĪóŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕų„ī¦(d©Żo)ą═Īó▓óąąöĄ(sh©┤)ō■(j©┤)Äņ║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╝»│╔ą═╚²ĘNŻ¼╬─Ą┌Ż▒╣Ø(ji©”)Ęų╬÷┤¾öĄ(sh©┤)ō■(j©┤)Ģr┤·Ż¼öĄ(sh©┤)ō■(j©┤)é}Äņ╦∙├µ┼RĄ─å¢Ņ}╝░╠¶æ(zh©żn)Ż╗Ą┌Ż▓╣Ø(ji©”)┴ą│÷┤¾öĄ(sh©┤)ō■(j©┤)Ģr┤·Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņŲĮ┼_ąĶŠ▀éõĄ─ÄūéĆųžę¬╠žąįŻ╗Ą┌Ż│╣Ø(ji©”)ĄĮĄ┌ŻĄ╣Ø(ji©”)Š═▀@ÄūéĆ╠žąįī”Ė„ŅÉŲĮ┼_▀M(j©¼n)ąąÜw╝{Ęų╬÷Ż╗Ą┌ŻČ╣Ø(ji©”)ī”ūŅą┬蹊┐ū÷ę╗Ė·█ÖÜw╝{Ż╗Ą┌ŻĘ╣Ø(ji©”)ĮķĮBųąć°╚╦├±┤¾īW(xu©”)į┌┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷ĘĮ├µĄ─蹊┐╣żū„Ż╗Ą┌ŻĖ╣Ø(ji©”)ī”╬┤üĒ蹊┐ū÷│÷š╣═¹Ż╗Ą┌Ż╣╣Ø(ji©”)┐éĮY(ji©”)╚½╬─ĪŻ
Ż▒Ż«Ż▒ ╚²éĆūā╗»
Ż©Ż▒Ż®öĄ(sh©┤)ō■(j©┤)┴┐ĪŻė╔ŻįŻ┬╝ē╔²ų┴ŻąŻ┬╝ēŻ¼▓ó╚įį┌│ų└m(x©┤)▒¼š©╩Įį÷ķLŻ¼Ė∙ō■(j©┤)ŻūŻķŻŅŻ¶ŻÕŻ“Ż├Ż’Ż“ŻĄ─š{(di©żo)▓ķ’@╩ŠŻ¼ūŅ┤¾Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņųąĄ─öĄ(sh©┤)ō■(j©┤)┴┐Ż¼├┐ā╔─Ļį÷╝ėŻ│▒ČŻ█Ż▒Ż▌Ż©─ĻŠ∙į÷ķL┬╩×ķŻ▒ŻĘŻ│ŻźŻ®Ż¼Ųõį÷ķL╦┘Č╚▀h(yu©Żn)│¼─”Ā¢Č©┬╔į÷ķL╦┘Č╚Ż¼šš┤╦į÷ķL╦┘Č╚ėŗ╦ŃŻ¼Ż▓Ż░Ż▒ŻĄ─ĻūŅ┤¾öĄ(sh©┤)ō■(j©┤)é}ÄņųąĄ─öĄ(sh©┤)ō■(j©┤)┴┐īó▒ŲĮ³Ż▒Ż░Ż░ŻąŻ┬ĪŻ
Ż©Ż▓Ż®Ęų╬÷ąĶŪ¾ĪŻė╔│ŻęÄ(gu©®)Ęų╬÷▐D(zhu©Żn)Ž“╔ŅČ╚Ęų╬÷Ż©Ż─ŻÕŻÕŻŻ┴ŻŅŻßŻņŻ∙Ż¶ŻķŻŃŻ¾Ż®Ż¼öĄ(sh©┤)ō■(j©┤)Ęų╬÷╚šęµ│╔×ķŲ¾śI(y©©)└¹ØÖ▒ž▓╗┐╔╔┘Ą─ų¦ō╬³cŻ¼Ė∙ō■(j©┤)ŻįŻ─ŻūŻ╔ī”┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─ł¾ĖµŻ©╚ńłDŻ▒Ż®Ż¼Ų¾śI(y©©)ęčĮø(j©®ng)▓╗ØMūŃė┌ī”¼F(xi©żn)ėąöĄ(sh©┤)ō■(j©┤)Ą─Ęų╬÷║═▒O(ji©Īn)£yŻ¼Č°╩ŪĖ³Ų┌═¹─▄ī”╬┤üĒ┌ģä▌ėąĖ³ČÓĄ─Ęų╬÷║═ŅA(y©┤)£yŻ¼ęįį÷ÅŖŲ¾śI(y©©)ĖéĀÄ┴”Ż¼▀@ą®Ęų╬÷▓┘ū„░³└©ųT╚ńęŲäėŲĮŠ∙ŠĆĘų╬÷ĪóöĄ(sh©┤)ō■(j©┤)ĻP(gu©Īn)┬ō(li©ón)ĻP(gu©Īn)ŽĄĘų╬÷Īó╗žÜwĘų╬÷Īó╩ął÷╗@Ęų╬÷Ą╚Å═(f©┤)ļsĮy(t©»ng)ėŗĘų╬÷Ż¼╬ęéāĘQų«×ķ╔ŅČ╚Ęų╬÷Ż¼ųĄĄ├ča│õĄ─╩ŪŻ¼▒Š╬─ųąĄ─┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷▓╗āHāHųĖ╗∙ė┌┤¾öĄ(sh©┤)ō■(j©┤)╔ŽĄ─╔ŅČ╚Ęų╬÷Ż¼ę▓░³└©│ŻęÄ(gu©®)Ęų╬÷ĪŻ
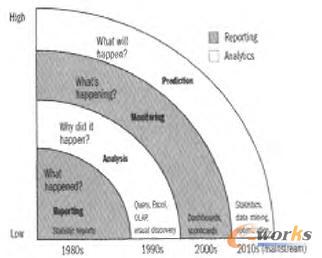
łDŻ▒ Ęų╬÷Ą─┌ģä▌
Ż©Ż│Ż®ė▓╝■ŲĮ┼_ĪŻė╔Ė▀Č╦Ę■äš(w©┤)Ų„▐D(zhu©Żn)Ž“ė╔ųąĄ═Č╦ė▓╝■śŗ(g©░u)│╔Ą─┤¾ęÄ(gu©®)─ŻÖC╚║ŲĮ┼_Ż¼ė╔ė┌öĄ(sh©┤)ō■(j©┤)┴┐Ą─čĖ╦┘į÷╝ėŻ¼▓óąąöĄ(sh©┤)ō■(j©┤)ÄņĄ─ęÄ(gu©®)─Ż▓╗Ą├▓╗ļSų«į÷┤¾Ż¼Å─Č°ī¦(d©Żo)ų┬Ųõ│╔▒ŠĄ─╝▒äĪ╔Ž╔²Ż¼│÷ė┌│╔▒ŠĄ─┐╝æ]Ż¼įĮüĒįĮČÓĄ─Ų¾śI(y©©)īóæ¬(y©®ng)ė├ė╔Ė▀Č╦Ę■äš(w©┤)Ų„▐D(zhu©Żn)Ž“┴╦ė╔ųąĄ═Č╦ė▓╝■śŗ(g©░u)│╔Ą─┤¾ęÄ(gu©®)─ŻÖC╚║ŲĮ┼_ĪŻ
Ż▒.Ż▓ ā╔éĆå¢Ņ}
łDŻ▓╩Ūę╗éĆĄõą═Ą─öĄ(sh©┤)ō■(j©┤)é}Äņ╝▄śŗ(g©░u)Ż¼Å─łDųą╬ęéā┐╔ęį┐┤│÷Ż¼é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)é}Äņīóš¹éĆīŹ¼F(xi©żn)äØĘų×ķŻ┤éĆīė┤╬Ż¼öĄ(sh©┤)ō■(j©┤)į┤ųąĄ─öĄ(sh©┤)ō■(j©┤)╩ūŽ╚═©▀^Ż┼ŻįŻ╠╣żŠ▀▒╗│ķ╚ĪĄĮöĄ(sh©┤)ō■(j©┤)é}Äņųą▀M(j©¼n)ąą╝»ųą┤µā”║═╣▄└ĒŻ¼į┘░┤ššąŪą═─Żą═╗“č®╗©─Żą═ĮM┐ŚöĄ(sh©┤)ō■(j©┤)Ż¼╚╗║¾ŻŽŻ╠Ż┴Żą╣żŠ▀Å─öĄ(sh©┤)ō■(j©┤)é}Äņųąūx╚ĪöĄ(sh©┤)ō■(j©┤)Ż¼╔·│╔öĄ(sh©┤)ō■(j©┤)┴óĘĮ¾wŻ©Ż═ŻŽŻ╠Ż┴ŻąŻ®╗“š▀ų▒ĮėįLå¢öĄ(sh©┤)ō■(j©┤)é}Äņ▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)Ęų╬÷Ż©ŻęŻŽŻ╠Ż┴ŻąŻ®Ż¼į┌┤¾öĄ(sh©┤)ō■(j©┤)Ģr┤·Ż¼┤╦ĘNėŗ╦Ń─Ż╩Į┤µį┌ā╔éĆå¢Ņ}Ż║
å¢Ņ}Ż▒Ż¼öĄ(sh©┤)ō■(j©┤)ęŲäė┤·ār▀^Ė▀Ż¼į┌öĄ(sh©┤)ō■(j©┤)į┤īė║═Ęų╬÷īėų«ķgę²╚ļę╗éĆ┤µā”╣▄└ĒīėŻ¼┐╔ęį╠ß╔²öĄ(sh©┤)ō■(j©┤)┘|(zh©¼)┴┐▓óßśī”▓ķįā▀M(j©¼n)ąąā×(y©Łu)╗»Ż¼Ą½ę▓ĖČ│÷┴╦▌^┤¾Ą─öĄ(sh©┤)ō■(j©┤)▀węŲ┤·ār║═ł╠(zh©¬)ąąĢrĄ─▀BĮė┤·ārŻ║öĄ(sh©┤)ō■(j©┤)╩ūŽ╚═©▀^Å═(f©┤)ļsŪę║─ĢrĄ─Ż┼ŻįŻ╠▀^│╠┤µā”ĄĮöĄ(sh©┤)ō■(j©┤)é}ÄņųąŻ¼į┌ŻŽŻ╠Ż┴ŻąĘ■äš(w©┤)Ų„ųą▐D(zhu©Żn)╗»×ķąŪą═─Żą═╗“š▀č®╗©─Żą═Ż╗ł╠(zh©¬)ąąĘų╬÷ĢrŻ¼ėų═©▀^▀BĮėĘĮ╩ĮīóöĄ(sh©┤)ō■(j©┤)Å─öĄ(sh©┤)ō■(j©┤)Äņųą╚Ī│÷Ż¼▀@ą®┤·ārį┌ŻįŻ┬╝ēĢrę▓įS┐╔ęįĮė╩▄Ż¼Ą½├µī”┤¾öĄ(sh©┤)ō■(j©┤)Ż¼Ųõł╠(zh©¬)ąąĢrķgų┴╔┘Ģ■į÷ķLÄūéĆöĄ(sh©┤)┴┐╝ēŻ¼Ė³×ķųžę¬Ą─╩ŪŻ¼ī”ė┌┤¾┴┐Ą─╝┤Ž»Ęų╬÷Ż¼▀@ĘNöĄ(sh©┤)ō■(j©┤)ęŲäėĄ─ėŗ╦Ń─Ż╩Į╩Ū▓╗┐╔╚ĪĄ─ĪŻ
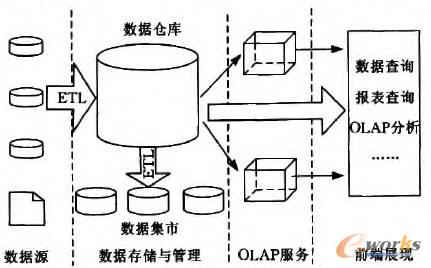
łDŻ▓ ę╗éĆĄõą═Ą─öĄ(sh©┤)ō■(j©┤)é}Äņ╝▄śŗ(g©░u)
å¢Ņ}Ż▓Ż¼▓╗─▄┐ņ╦┘▀mæ¬(y©®ng)ūā╗»Ż¼é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)é}Äņ╝┘įO(sh©©)ų„Ņ}╩Ū▌^╔┘ūā╗»Ą─Ż¼Ųõæ¬(y©®ng)ī”ūā╗»Ą─ĘĮ╩Į╩Ūī”öĄ(sh©┤)ō■(j©┤)į┤ĄĮŪ░Č╦š╣¼F(xi©żn)Ą─š¹éĆ┴„│╠ųąĄ─├┐éĆ▓┐Ęų▀M(j©¼n)ąąą▐Ė─Ż¼╚╗║¾į┘ųžą┬╝ė▌döĄ(sh©┤)ō■(j©┤)Ż¼╔§ų┴ųžą┬ėŗ╦ŃöĄ(sh©┤)ō■(j©┤)Ż¼ī¦(d©Żo)ų┬Ųõ▀mæ¬(y©®ng)ūā╗»Ą─ų▄Ų┌▌^ķLŻ¼▀@ĘN─Ż╩Į▒╚▌^▀m║Žī”öĄ(sh©┤)ō■(j©┤)┘|(zh©¼)┴┐║═▓ķįāąį─▄ę¬Ū¾▌^Ė▀ĪóČ°▓╗╠½ėŗ▌^ŅA(y©┤)╠Ä└Ē┤·ārĄ─ł÷║ŽŻ¼Ą½į┌┤¾öĄ(sh©┤)ō■(j©┤)Ģr┤·Ż¼Ęų╬÷╠Äį┌ūā╗»Ą─śI(y©©)äš(w©┤)Łh(hu©ón)Š│ųąŻ¼▀@ĘN─Ż╩Įīóļyęį▀mæ¬(y©®ng)ą┬Ą─ąĶŪ¾ĪŻ
Ż▒Ż«Ż│ ę╗éĆ°Ö£Ž
į┌┤¾öĄ(sh©┤)ō■(j©┤)Ģr┤·Ż¼Š▐┴┐öĄ(sh©┤)ō■(j©┤)┼cŽĄĮy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)╠Ä└Ē─▄┴”ų«ķgīóĢ■«a(ch©Żn)╔·ę╗éĆ°Ö£ŽŻ║ę╗▀ģ╩Ūų┴╔┘ŻąŻ┬╝ēĄ─öĄ(sh©┤)ō■(j©┤)┴┐Ż¼┴Ēę╗▀ģ╩Ū├µŽ“é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)Ęų╬÷─▄┴”įO(sh©©)ėŗĄ─öĄ(sh©┤)ō■(j©┤)é}Äņ║═Ė„ĘNŻ┬Ż╔╣żŠ▀Ż¼╚ń╣¹▀@ą®ŽĄĮy(t©»ng)╗“╣żŠ▀░l(f©Ī)š╣ŠÅ┬²Ż¼įō°Ö£ŽīóĢ■ļSų°öĄ(sh©┤)ō■(j©┤)┴┐Ą─│ų└m(x©┤)▒¼š©╩Įį÷ķLČ°ų▓Į└Ł┤¾ĪŻ
ļm╚╗Ż¼é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)é}Äņ┐╔ęį▓╔ė├╔ߌē▓╗ųžę¬öĄ(sh©┤)ō■(j©┤)╗“š▀Į©┴óöĄ(sh©┤)ō■(j©┤)╝»╩ąĄ─ĘĮ╩ĮüĒŠÅĮŌ┤╦å¢Ņ}Ż¼Ą½«ģŠ╣ų╗╩ŪÖÓ(qu©ón)ęµų«▓▀Ż¼▓óĘŪŽĄĮy(t©»ng)╝ēĮŌøQĘĮ░ĖŻ¼Č°ŪęŻ¼╔ߌēĄ─öĄ(sh©┤)ō■(j©┤)į┌╬┤üĒ┐╔─▄Ģ■ųžą┬╩╣ė├Ż¼ęį░l(f©Ī)Š“Ė³┤¾Ą─ārųĄĪŻ
Ż▓ Ų┌═¹╠žąį
▒Š╣Ø(ji©”)╬ęéā┴ą│÷ī”┤¾öĄ(sh©┤)ō■(j©┤)▀M(j©¼n)ąąĘų╬÷ĢrŻ¼öĄ(sh©┤)ō■(j©┤)é}ÄņŽĄĮy(t©»ng)ąĶŠ▀éõĄ─ÄūéĆųžę¬╠žąįŻ©▒ĒŻ▒╦∙╩ŠŻ®ĪŻ

▒ĒŻ▒ ┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷ŲĮ┼_ąĶŠ▀éõĄ─╠žąį
Ė▀Č╚┐╔öUš╣ąįŻ¼ę╗éĆ├„’@Ą─╩┬īŹ╩ŪŻ¼öĄ(sh©┤)ō■(j©┤)Äņ▓╗─▄ę└┐┐ę╗┼_╗“╔┘öĄ(sh©┤)Äū┼_ÖCŲ„Ą─╔²╝ēŻ©Ż¾ŻŃŻßŻņŻÕ¬▓Ż§Ż┐vŽ“öUš╣Ż®ØMūŃöĄ(sh©┤)ō■(j©┤)┴┐Ą─▒¼š©╩Įį÷ķLŻ¼Č°╩ŪŽŻ═¹─▄ĘĮ▒ŃĄžū÷ĄĮÖMŽ“┐╔öUš╣Ż©Ż¾ŻŃŻßŻņŻÕ¬▓Ż’Ż§Ż¶Ż®üĒīŹ¼F(xi©żn)┤╦─┐ś╦(bi©Īo)Ż¼Ųš▒ķšJ(r©©n)×ķŻ¾ŻĶŻßŻ“ŻÕŻõ¬▓ŻŅŻ’Ż¶ŻĶŻķŻŅŻń¤o╣▓ŽĒĮY(ji©”)śŗ(g©░u)Ż©├┐éĆ╣Ø(ji©”)³cōĒėą╦Įėąā╚(n©©i)┤µ║═┤┼▒PŻ¼▓óŪę═©▀^Ė▀╦┘ŠW(w©Żng)Įj(lu©░)═¼Ųõ╦³╣Ø(ji©”)³c╗ź▀BŻ®Š▀éõ▌^║├Ą─öUš╣ąįŻ¼Ęų╬÷ą═▓┘ū„═∙═∙╔µ╝░┤¾ęÄ(gu©®)─ŻĄ─▓óąąÆ▀├ĶĪóČÓŠSŠ█╝»╝░ąŪą═▀BĮė▓┘ū„Ż¼▀@ą®▓┘ū„ę▓▒╚▌^▀m║Žį┌¤o╣▓ŽĒĮY(ji©”)śŗ(g©░u)Ą─ŠW(w©Żng)Įj(lu©░)Łh(hu©ón)Š│▀\ąąŻ¼ŻįŻÕŻ“ŻßŻõŻßŻ¶Żß╝┤▓╔ė├┤╦ĮY(ji©”)śŗ(g©░u)Ż¼ŻŽŻ“ŻßŻŃŻņŻÕį┌Ųõą┬«a(ch©Żn)ŲĘŻ┼Ż°ŻßŻõŻßŻ¶Żßųąę▓▓╔ė├┴╦┤╦ĮY(ji©”)śŗ(g©░u)ĪŻ
Ė▀ąį─▄Ż¼öĄ(sh©┤)ō■(j©┤)┴┐Ą─į÷ķL▓óø]ėąĮĄĄ═ī”öĄ(sh©┤)ō■(j©┤)Äņąį─▄Ą─ę¬Ū¾Ż¼Ę┤Č°ėą╦∙╠ßĖ▀Ż¼▄ø╝■ŽĄĮy(t©»ng)ąį─▄Ą─╠ß╔²┐╔ęįĮĄĄ═Ų¾śI(y©©)ī”ė▓╝■Ą─═Č╚ļ│╔▒ŠĪó╣Ø(ji©”)╩Īėŗ╦Ń┘Yį┤Ż¼╠ßĖ▀ŽĄĮy(t©»ng)═╠═┬┴┐Ż¼Š▐┴┐öĄ(sh©┤)ō■(j©┤)Ą─ą¦┬╩ā×(y©Łu)╗»Ż¼▓óąą╩Ū▒žė╔ų«┬ĘŻ¼Ż▒ŻąŻ┬öĄ(sh©┤)ō■(j©┤)į┌ŻĄŻ░Ż═Ż┬Ż»Ż¾╦┘Č╚Ž┬┤«ąąÆ▀├Ķę╗┤╬Ż¼ąĶ꬯▓Ż│Ż░╠ņŻ╗Č°į┌ŻČŻ░Ż░Ż░ēK┤┼▒P╔ŽŻ¼▓óąąÆ▀├ĶŻ▒ŻąŻ┬öĄ(sh©┤)ō■(j©┤)ų╗ąĶ꬯▒éĆąĪĢrĪŻ
Ė▀Č╚╚▌ÕeŻ¼┤¾öĄ(sh©┤)ō■(j©┤)Ą─╚▌Õeąįę¬Ū¾į┌▓ķįāł╠(zh©¬)ąą▀^│╠ųąŻ¼ę╗éĆģó┼c╣Ø(ji©”)³c╩¦ą¦ĢrŻ¼▓╗ąĶę¬ųžū÷š¹éĆ▓ķįāŻ¼Č°ÖC╚║╣Ø(ji©”)³cöĄ(sh©┤)Ą─į÷╝ėĢ■ĦüĒ╣Ø(ji©”)³c╩¦ą¦Ė┼┬╩Ą─į÷╝ėŻ¼į┌┤¾ęÄ(gu©®)─ŻÖC╚║Łh(hu©ón)Š│Ž┬Ż¼╣Ø(ji©”)³cĄ─╩¦ą¦īó▓╗į┘╩ŪŽĪėą╩┬╝■Ż©ŻŪŻ’Ż’ŻńŻņŻÕł¾ĖµŻ¼ŲĮŠ∙├┐éĆŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕöĄ(sh©┤)ō■(j©┤)╠Ä└Ē╚╬äš(w©┤)Š═ėąŻ▒.Ż▓éĆ╣żū„╣Ø(ji©”)³c╩¦ą¦Ż®Ż¼ę“┤╦į┌┤¾ęÄ(gu©®)─ŻÖC╚║Łh(hu©ón)Š│Ž┬Ż¼ŽĄĮy(t©»ng)▓╗─▄ę└┘ćė┌ė▓╝■üĒ▒ŻūC╚▌ÕeąįŻ¼ę¬Ė³ČÓĄž┐╝æ]▄ø╝■╝ē╚▌ÕeĪŻ
ų¦│ų«Éśŗ(g©░u)Łh(hu©ón)Š│Ż¼Į©įO(sh©©)═¼śŗ(g©░u)ŽĄĮy(t©»ng)Ą─┤¾ęÄ(gu©®)─ŻÖC╚║ļyČ╚▌^┤¾Ż¼įŁę“į┌ė┌ėŗ╦ŃÖCė▓╝■Ė³ą┬▌^┐ņŻ¼ę╗┤╬ąį┘Åų├┤¾┴┐═¼śŗ(g©░u)Ą─ėŗ╦ŃÖC╩Ū▓╗┐╔╚ĪĄ─Ż¼Č°Ūęę▓Ģ■į┌╬┤üĒ╠Ēų├«Éśŗ(g©░u)ėŗ╦Ń┘Yį┤Ż¼┤╦═ŌŻ¼▓╗╔┘Ų¾śI(y©©)ęčĮø(j©®ng)Ęe└█┴╦ę╗ą®ķeų├Ą─ėŗ╦ŃÖC┘Yį┤Ż¼┤╦ĘNŪķørŽ┬Ż¼ī”«Éśŗ(g©░u)Łh(hu©ón)Š│Ą─ų¦│ų┐╔ęįėąą¦Ąž└¹ė├▀@ą®ķeų├ėŗ╦Ń┘Yį┤Ż¼ĮĄĄ═ė▓╝■│╔▒ŠĄ─═Č╚ļŻ¼▀ĆąĶ╠žäeĻP(gu©Īn)ūóĄ─╩ŪŻ¼į┌«Éśŗ(g©░u)Łh(hu©ón)Š│Ž┬Ż¼▓╗═¼╣Ø(ji©”)³cĄ─ąį─▄╩Ū▓╗ę╗śėĄ─Ż¼┐╔─▄│÷¼F(xi©żn)“─Š═░ą¦æ¬(y©®ng)”Ż¼╝┤ūŅ┬²╣Ø(ji©”)³cĄ─ąį─▄øQČ©š¹¾w╠Ä└Ēąį─▄Ż¼ę“┤╦Ż¼«Éśŗ(g©░u)Ą─ÖC╚║ąĶę¬╠žäeĻP(gu©Īn)ūóžō(f©┤)▌dŠ∙║ŌĪó╚╬äš(w©┤)š{(di©żo)Č╚Ą╚ĘĮ├µĄ─įO(sh©©)ėŗĪŻ
▌^Ą═Ą─Ęų╬÷čė▀tŻ¼Ęų╬÷čė▀tųĖĄ─╩ŪĘų╬÷Ū░Ą─öĄ(sh©┤)ō■(j©┤)£╩(zh©│n)éõĢrķgŻ¼į┌┤¾öĄ(sh©┤)ō■(j©┤)Ģr┤·Ż¼Ęų╬÷╦∙╠ÄĄ─śI(y©©)äš(w©┤)Łh(hu©ón)Š│╩Ūūā╗»Ą─Ż¼ę“┤╦ę▓ę¬Ū¾ŽĄĮy(t©»ng)─▄äėæB(t©żi)Ąž▀mæ¬(y©®ng)śI(y©©)äš(w©┤)Ęų╬÷ąĶŪ¾Ż¼į┌Ęų╬÷ąĶŪ¾░l(f©Ī)╔·ūā╗»ĢrŻ¼£p╔┘öĄ(sh©┤)ō■(j©┤)£╩(zh©│n)éõĢrķgŻ¼ŽĄĮy(t©»ng)─▄▒M┐╔─▄┐ņĄžū÷│÷Ę┤æ¬(y©®ng)Ż¼┐ņ╦┘Ąž▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)Ęų╬÷ĪŻ
ęūė├Ūęķ_Ę┼Ą─Įė┐┌Ż¼ŻėŻčŻ╠Ą─ā×(y©Łu)³c╩Ū║åå╬ęūė├Ż¼Ą½Ųõų„ę¬ė├ė┌öĄ(sh©┤)ō■(j©┤)Ą─Öz╦„▓ķįāŻ¼ī”ė┌┤¾öĄ(sh©┤)ō■(j©┤)╔ŽĄ─╔ŅČ╚Ęų╬÷üĒųvŻ¼╩Ū▓╗ē“Ą─Ż¼įŁę“į┌ė┌Ż║Ż©Ż▒Ż®Ųõ╠ß╣®Ą─Ę■äš(w©┤)ĘĮ╩Įę└┘ćė┌öĄ(sh©┤)ō■(j©┤)ęŲäėüĒīŹ¼F(xi©żn)Ż║īóöĄ(sh©┤)ō■(j©┤)Å─öĄ(sh©┤)ō■(j©┤)Äņųą╚Ī│÷Ż¼╚╗║¾é„▀fĮoæ¬(y©®ng)ė├│╠ą“Ż¼įōīŹ¼F(xi©żn)ĘĮ╩Įį┌┤¾öĄ(sh©┤)ō■(j©┤)Ģr┤·┤·ār▀^Ė▀Ż╗Ż©Ż▓Ż®Å═(f©┤)ļsĄ─Ęų╬÷╣”─▄Ż¼╚ńŻę╗“Ż═ŻßŻ¶ŻņŻßŻŌųąĄ─Ęų╬÷╣”─▄Ż¼ŻėŻčŻ╠╩Ūļyęįä┘╚╬Ą─Ż¼ę“┤╦Ż¼│²ī”ŻėŻčŻ╠Ą─ų¦│ų═ŌŻ¼ŽĄĮy(t©»ng)▀Ćæ¬(y©®ng)─▄╠ß╣®ķ_Ę┼Ą─Įė┐┌Ż¼ūīė├æ¶ūį╝║ķ_░l(f©Ī)ąĶꬥ─╣”─▄Ż¼įO(sh©©)ėŗįōĮė┐┌ĢrŻ¼│²┴╦ĻP(gu©Īn)ūóŲõęūė├ąį║═ķ_Ę┼ąįŻ¼▀ĆąĶę¬╠žäeūóęŌā╔³cļ[▓žĄ─ę¬Ū¾Ż║Ż©Ż▒Ż®╗∙ė┌Įė┐┌ķ_░l(f©Ī)Ą─ė├æ¶ūįČ©┴x║»öĄ(sh©┤)Ż¼─▄ūįäėį┌ÖC╚║╔Ž▓óąął╠(zh©¬)ąąŻ╗Ż©Ż▓Ż®Ęų╬÷į┌öĄ(sh©┤)ō■(j©┤)Äņā╚(n©©i)▀M(j©¼n)ąąŻ¼╝┤Ęų╬÷▒M┐╔─▄┐┐Į³öĄ(sh©┤)ō■(j©┤)ĪŻ
▌^Ą═Ą─│╔▒ŠŻ¼į┌ØMūŃąĶŪ¾Ą─Ū░╠ߎ┬Ż¼─│╝╝ąg(sh©┤)│╔▒ŠįĮĄ═Ż¼Ųõ╔·├³┴”Š═įĮÅŖŻ¼ąĶę¬ųĖ│÷Ą─╩Ū│╔▒Š╩Ūę╗éĆŠC║ŽųĖś╦(bi©Īo)Ż¼▓╗āHāH╩Ūė▓╝■╗“▄ø╝■Ą─┤·ārŻ¼▀Ćæ¬(y©®ng)░³└©╚š│Ż▀\ŠS│╔▒ŠŻ©ŠW(w©Żng)Įj(lu©░)┘Mė├ĪóļŖ┘MĪóĮ©ų■Ą╚Ż®║═╣▄└Ē╚╦åT│╔▒ŠĄ╚Ż¼ō■(j©┤)ł¾ĖµŻ¼öĄ(sh©┤)ō■(j©┤)ųąą─Ą─ų„ę¬│╔▒Š▓╗╩Ūė▓╝■Ą─┘Åų├│╔▒ŠŻ¼Č°╩Ū╚š│Ż▀\ŠS│╔▒ŠŻ¼ę“┤╦Ż¼į┌įO(sh©©)ėŗŽĄĮy(t©»ng)ĢrąĶę¬Ė³ČÓĄžĻP(gu©Īn)ūó┤╦ĒŚā╚(n©©i)╚▌ĪŻ
Ž“Ž┬╝µ╚▌ąįŻ¼öĄ(sh©┤)ō■(j©┤)é}Äņ░l(f©Ī)š╣Ą─Ż│Ż░─ĻŻ¼«a(ch©Żn)╔·┴╦┤¾┴┐├µŽ“┐═æ¶śI(y©©)äš(w©┤)Ą─öĄ(sh©┤)ō■(j©┤)╠Ä└Ē╣żŠ▀Ż©╚ńŻ╔ŻŅŻµŻ’Ż“ŻĒŻßŻŃŻ¶ŻķŻŃŻßĪóŻ─ŻßŻ¶ŻßŻėŻ¶ŻßŻńŻÕĄ╚Ż®ĪóĘų╬÷▄ø╝■Ż©╚ńŻėŻąŻėŻėĪóŻęĪóŻ═ŻßŻ¶ŻņŻßŻŌĄ╚Ż®║═Ū░Č╦š╣¼F(xi©żn)╣żŠ▀Ż©╚ń╦«Š¦ł¾▒ĒŻ®Ą╚Ż¼▀@ą®▄ø╝■╩Ūę╗╣PīÜ┘FĄ─žöĖ╗Ż¼ęč▒╗Ęų╬÷╚╦åT╦∙╩ņŽżŻ¼╩Ū┤¾öĄ(sh©┤)ō■(j©┤)Ģr┤·ųąąĪęÄ(gu©®)─ŻöĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─▒žę¬ča│õŻ¼ę“┤╦Ż¼ą┬Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņąĶ┐╝æ]═¼é„Įy(t©»ng)╔╠äš(w©┤)ųŪ─▄╣żŠ▀Ą─╝µ╚▌ąįŻ¼ė╔ė┌▀@ą®ŽĄĮy(t©»ng)═∙═∙╠ß╣®ś╦(bi©Īo)£╩(zh©│n)“ī(q©▒)äė│╠ą“Ż¼╚ńŻŽŻ─Ż┬Ż├ĪóŻ╩Ż─Ż┬Ż├Ą╚Ż¼▀@ĒŚąĶŪ¾Ą─īŹļHę¬Ū¾╩Ūī”ŻėŻčŻ╠Ą─ų¦│ųĪŻ
┐éų«Ż¼ęį▌^Ą═Ą─│╔▒Š═Č╚ļĪóĖ▀ą¦Ąž▀M(j©¼n)ąąöĄ(sh©┤)ō■(j©┤)Ęų╬÷Ż¼╩Ū┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─╗∙▒Š─┐ś╦(bi©Īo)ĪŻ
Ż│ ▓óąąöĄ(sh©┤)ō■(j©┤)Äņ
▓óąąöĄ(sh©┤)ō■(j©┤)ÄņŲį┤ė┌Ż▓Ż░╩└╝o(j©¼)ŻĖŻ░─Ļ┤·Ż¼«ö(d©Īng)Ū░ų„┴„Ą─▓óąąöĄ(sh©┤)ō■(j©┤)ÄņČ╝═¼įńŲ┌Ą─ŻŪŻßŻĒŻĒŻß║═ŻŪŻ“ŻßŻŃŻÕĄ╚▓óąąöĄ(sh©┤)ō■(j©┤)ÄņŅÉ╦ŲŻ¼▀@ą®öĄ(sh©┤)ō■(j©┤)ÄņČ╝ų¦│ųś╦(bi©Īo)£╩(zh©│n)ŻėŻčŻ╠Ż¼▓óŪęīŹ¼F(xi©żn)┴╦öĄ(sh©┤)ō■(j©┤)ÄņĮń▀^╚źŻ│Ż░─Ļ╠ß│÷Ą─įSČÓŽ╚▀M(j©¼n)╝╝ąg(sh©┤)Ż¼Ųõų„ę¬▓╔ė├Ż¾ŻĶŻßŻ“ŻÕŻõ¬▓ŻŅŻ’Ż¶ŻĶŻķŻŅŻńĮY(ji©”)śŗ(g©░u)Ż¼īóĻP(gu©Īn)ŽĄ▒Ēį┌╣Ø(ji©”)³cķgÖMŽ“äØĘųŻ¼▓óŪę└¹ė├ā×(y©Łu)╗»Ų„üĒī”ł╠(zh©¬)ąą▀^│╠▀M(j©¼n)ąąš{(di©żo)Č╚║═╣▄└ĒŻ¼Ųõ─┐ś╦(bi©Īo)╩ŪĖ▀ąį─▄║═Ė▀┐╔ė├ąįĪŻ
▓óąąöĄ(sh©┤)ō■(j©┤)ÄņĄ─ūŅ┤¾ā×(y©Łu)ä▌į┌ė┌ąį─▄Ż¼▀@ų„ꬥ├ęµė┌öĄ(sh©┤)ō■(j©┤)ÄņĮńĮ³Äū╩«─ĻĄ─蹊┐│╔╣¹———įSČÓŽ╚▀M(j©¼n)Ą─╝╝ąg(sh©┤)╩ųČ╬╝░╦ŃĘ©Ż¼╚ń╦„ę²ĪóöĄ(sh©┤)ō■(j©┤)ē║┐sĪó╬’╗»ęĢłDĪóĮY(ji©”)╣¹ŠÅø_ĪóŻ╔Ż»ŻŽ╣▓ŽĒĪóā×(y©Łu)╗»Ą─öĄ(sh©┤)ō■(j©┤)▀BĮėĄ╚Ż¼Ą½╩Ūį┌┤¾öĄ(sh©┤)ō■(j©┤)Ģr┤·Ż¼╚ńŪ░čį╦∙╩÷Ż¼öĄ(sh©┤)ō■(j©┤)ęŲäėĄ─īŹ¼F(xi©żn)ĘĮ╩Įīóė░ĒæŲõąį─▄ĪŻ
▓óąąöĄ(sh©┤)ō■(j©┤)Äņ═©▀^ŻėŻčŻ╠Ž“═Ō╠ß╣®öĄ(sh©┤)ō■(j©┤)įLå¢Ę■äš(w©┤)Ż¼ŻėŻčŻ╠ę“Ųõ║åå╬ęūė├Ą─╠ž³cČ°▒╗ÅVĘ║╩╣ė├Ż¼ę“┤╦Ż¼┤¾ČÓŻ┬Ż╔╣żŠ▀Č╝ų¦│ų╗∙ė┌ś╦(bi©Īo)£╩(zh©│n)ŻėŻčŻ╠Ą─öĄ(sh©┤)ō■(j©┤)Į╗╗źĘĮ╩ĮŻ¼╩╣Ą├ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņ─▄▌^║├Ąž╝µ╚▌«ö(d©Īng)Ū░ČÓöĄ(sh©┤)Ż┬Ż╔╣żŠ▀Ż¼─│ą®öĄ(sh©┤)ō■(j©┤)ÄņŻ¼╚ńŻ╔Ż┬Ż═Ż─Ż┬Ż▓▀Ćßśī”ę╗ą®Ż┬Ż╔╣żŠ▀▀M(j©¼n)ąą┴╦ā×(y©Łu)╗»Ż¼Ą½į┌┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷├µŪ░Ż¼ŻėŻčŻ╠Įė┐┌├µ┼RŠ▐┤¾╠¶æ(zh©żn)Ż¼ŻėŻčŻ╠Ą─ā×(y©Łu)ä▌į┤ė┌Ųõī”ĄūīėöĄ(sh©┤)ō■(j©┤)įLå¢Ą─ĘŌčbŻ¼Ą½ĘŌčbį┌ę╗Č©│╠Č╚╔Žė░Ēæ┴╦Ųõķ_Ę┼ąįŻ¼Č°Ūę▓óąąöĄ(sh©┤)ō■(j©┤)Äņ╠ß╣®Ą─ė├æ¶ūįČ©┴x║»öĄ(sh©┤)┤¾Č╝╩Ū╗∙ė┌å╬öĄ(sh©┤)ō■(j©┤)ÄņīŹ└²įO(sh©©)ėŗĄ─Ż¼Å─Č°▓╗─▄į┌ÖC╚║╔Ž▓óąął╠(zh©¬)ąąŻ¼ę▓╝┤ęŌ╬Čų°é„Įy(t©»ng)Ą─īŹ¼F(xi©żn)ĘĮ╩Į▓╗▀m║Ž┤¾öĄ(sh©┤)ō■(j©┤)Ą─╠Ä└Ē╝░Ęų╬÷Ż¼Č°ŪęŻ¼į┌▓óąąöĄ(sh©┤)ō■(j©┤)ÄņųąīŹ¼F(xi©żn)ė├æ¶ūįČ©┴x║»öĄ(sh©┤)═∙═∙ąĶę¬Įø(j©®ng)▀^Å═(f©┤)ļsĄ─ŽĄĮy(t©»ng)Į╗╗źŻ¼╔§ų┴ę¬╩ņŽżöĄ(sh©┤)ō■(j©┤)ÄņĄ─ā╚(n©©i)▓┐ĮY(ji©”)śŗ(g©░u)╝░ŽĄĮy(t©»ng)š{(di©żo)ė├Ą╚Ż¼Å─Č°ļyęį╩╣ė├ĪŻ
▓óąąöĄ(sh©┤)ō■(j©┤)Äņį┌öUš╣ąįĪó╚▌ÕeąįĪó│╔▒ŠĪóī”«Éśŗ(g©░u)Łh(hu©ón)Š│Ą─ų¦│ųĄ╚ÄūĒŚ╔Žėą╦∙ŪĘ╚▒Ż¼▀@ÄūĒŚīŹļH╩ŪŽÓ╗źė░ĒæĄ─Ż¼╬ęéāęįŲõūŅ┤¾å¢Ņ}———öUš╣ąį×ķų„ŠĆš╣ķ_ėæšōŻ¼▓óąąöĄ(sh©┤)ō■(j©┤)Äņ┤¾ČÓų¦│ųėąŽ▐öUš╣Ż¼ę╗░Ń┐╔öUų┴öĄ(sh©┤)░┘╣Ø(ji©”)³cĄ─ęÄ(gu©®)─ŻŻ¼╔ą╬┤ėąöĄ(sh©┤)Ū¦╣Ø(ji©”)³cęÄ(gu©®)─ŻĄ─æ¬(y©®ng)ė├░Ė└²Ż¼▓óąąöĄ(sh©┤)ō■(j©┤)ÄņöUš╣ąįėąŽ▐ų„ę¬ę“×ķ╚ńŽ┬Äū³cŻ║Ż©Ż▒Ż®▓óąąöĄ(sh©┤)ō■(j©┤)Äņ▄ø╝■╝ē╚▌Õe─▄┴”▌^▓ŅŻ¼▓óąąöĄ(sh©┤)ō■(j©┤)Äņ╗∙ė┌Ė▀Č╦ė▓╝■įO(sh©©)ėŗŻ¼▓óŪę╝┘įO(sh©©)▓ķįā╩¦öĪī┘ė┌ŽĪėą╩┬╝■Ż¼ę“┤╦«ö(d©Īng)▓ķįā╩¦öĪĢrŻ¼ę╗░Ń▓╔╚Īųžū÷▓ķįāĄ─ĘĮ╩ĮŻ¼Č°į┌┤¾ęÄ(gu©®)─ŻÖC╚║Łh(hu©ón)Š│Ž┬Ż¼▓ķįā╩¦öĪīóĢ■ūā?y©Łu)ķę╗éĆŲš═©╩┬╝■Ż¼śOČ╦ŪķørŽ┬Ż¼▓óąąöĄ(sh©┤)ō■(j©┤)ėą┐╔─▄│÷¼F(xi©żn)▓╗═Żųžū÷▓ķįāĄ─Šų├µŻ╗Ż©Ż▓Ż®▓óąąöĄ(sh©┤)ō■(j©┤)Äņī”«Éśŗ(g©░u)ė▓╝■Ą─ų¦│ųĘŪ│ŻėąŽ▐Ż¼Ūęī”ė┌╠Ä└Ē▌^┬²Ą─╣Ø(ji©”)³cĘ┤æ¬(y©®ng)├¶ĖąŻ¼╚▌ęū│÷¼F(xi©żn)“─Š═░ą¦æ¬(y©®ng)”Ż¼╚ńĄ┌Ż▓╣Ø(ji©”)ųą╦∙šō╩÷Ą─Ż¼═Ļ╚½╗∙ė┌═¼śŗ(g©░u)ė▓╝■┤ŅĮ©┤¾ęÄ(gu©®)─ŻÖC╚║į┌¼F(xi©żn)īŹųą╩Ū▌^ļyīŹ¼F(xi©żn)Ą─Ż¼ę“Č°Ż¼ī”«Éśŗ(g©░u)ė▓╝■Ą─ų¦│ų─▄┴”ė░Ēæ┴╦ŲõöUš╣ąįŻ╗Ż©Ż│Ż®▓óąąöĄ(sh©┤)ō■(j©┤)Äņ╚¶ū÷ĄĮ┤¾ęÄ(gu©®)─Ż┐╔öUš╣Ż¼Ųõ┤·ārīóĢ■▌^Ė▀Ż©ąĶ╗∙ė┌Ė▀Č╦ė▓╝■üĒ▒ŻūC┐╔┐┐ąįŻ¼ąĶ┘Å┘I░║┘FĄ─▄ø╝■ŽĄĮy(t©»ng)Ż®Ż¼Å─Č°Ž▐ųŲ┴╦ŲõöUš╣ąįŻ╗Ż©Ż┤Ż®Ė∙ō■(j©┤)Ż├Ż┴Żą└Ēšōó┘Ż¼į┌Ęų▓╝╩ĮŽĄĮy(t©»ng)ųąŻ¼öĄ(sh©┤)ō■(j©┤)ę╗ų┬ąįŻ©Ż├Ż’ŻŅŻ¾ŻķŻ¾Ż¶ŻÕŻŅŻŃŻ∙Ż®Īó┐╔ė├ąįŻ©Ż┴Ż÷ŻßŻķŻņŻßŻŌŻķŻņŻķŻ¶Ż∙Ż®ĪóūėŠW(w©Żng)┐╔ĘųĮŌąįŻ©Ż╬ŻÕŻ¶Ż„Ż’Ż“ŻļŻąŻßŻ“Ż¶ŻķŻ¶ŻķŻ’ŻŅŻķŻŅŻńŻ®▓╗┐╔═¼Ģr╝µĄ├Ż¼▀xō±Ųõųą╚╬ā╔ĒŚŻ¼▒ŃĢ■ōp║”┴Ēę╗ĒŚŻ¼▓óąąöĄ(sh©┤)ō■(j©┤)ÄņūĘŪ¾Ą─╩ŪöĄ(sh©┤)ō■(j©┤)ę╗ų┬ąį║═ŽĄĮy(t©»ng)Ą─┐╔ė├ąįŻ¼Å─Č°ė░Ēæ┴╦╦³Ą─öUš╣─▄┴”ĪŻ
┤╦═ŌŻ¼╚ńŻ▒.Ż▓╣Ø(ji©”)╦∙ėæšōĄ─Ż¼╗∙ė┌▓óąąöĄ(sh©┤)ō■(j©┤)ÄņīŹ¼F(xi©żn)Ą─é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)é}ÄņĮĶų·ė┌═Ōć·╣żŠ▀Ż©Ż┼ŻįŻ╠╣żŠ▀ĪóŻŽŻ╠Ż┴Żą«a(ch©Żn)ŲĘĪóŻ┬Ż╔ł¾▒Ē╣żŠ▀ĪóĮy(t©»ng)ėŗĘų╬÷▄ø╝■Ą╚Ż®üĒ═Ļ│╔öĄ(sh©┤)ō■(j©┤)Ą─ŅA(y©┤)╠Ä└Ē║═Ęų╬÷š╣¼F(xi©żn)╚╬äš(w©┤)Ż¼ī¦(d©Żo)ų┬ŲõöĄ(sh©┤)ō■(j©┤)╠Ä└Ē╝░Ęų╬÷▀^│╠╔µ╝░┤¾┴┐Ą─öĄ(sh©┤)ō■(j©┤)▀węŲ║═ėŗ╦ŃŻ¼Ęų╬÷čė▀t═∙═∙▌^Ė▀ĪŻ
Ż┤MapReduce
Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╩ŪŻ▓Ż░Ż░Ż┤─Ļė╔ŻŪŻ’Ż’ŻńŻņŻÕ╠ß│÷Ą─├µŽ“┤¾öĄ(sh©┤)ō■(j©┤)╝»╠Ä└ĒĄ─ŠÄ│╠─Żą═Ż¼Ų│§ų„ę¬ė├ū„╗ź┬ō(li©ón)ŠW(w©Żng)öĄ(sh©┤)ō■(j©┤)Ą─╠Ä└ĒŻ¼└²╚ń╬─Önūź╚ĪĪóĄ╣┼┼╦„ę²Ą─Į©┴óĄ╚Ż¼Ą½ė╔ė┌Ųõ║åå╬Č°ÅŖ┤¾Ą─öĄ(sh©┤)ō■(j©┤)╠Ä└ĒĮė┐┌║═ī”┤¾ęÄ(gu©®)─Ż▓óąął╠(zh©¬)ąąĪó╚▌Õe╝░žō(f©┤)▌dŠ∙║ŌĄ╚īŹ¼F(xi©żn)╝Ü(x©¼)╣Ø(ji©”)Ą─ļ[▓žŻ¼įō╝╝ąg(sh©┤)ę╗Įø(j©®ng)═Ų│÷▒ŃčĖ╦┘į┌ÖCŲ„īW(xu©”)┴Ģ(x©¬)ĪóöĄ(sh©┤)ō■(j©┤)═┌Š“ĪóöĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą╚ŅI(l©½ng)ė“Ą├ĄĮÅVĘ║æ¬(y©®ng)ė├ĪŻ
Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕīóöĄ(sh©┤)ō■(j©┤)╠Ä└Ē╚╬äš(w©┤)│ķŽ¾×ķę╗ŽĄ┴ąĄ─Ż═ŻßŻŻ©ė│╔õŻ®¬▓ŻęŻÕŻõŻ§ŻŃŻÕŻ©╗»║åŻ®▓┘ū„ī”Ż¼Ż═ŻßŻų„ę¬═Ļ│╔öĄ(sh©┤)ō■(j©┤)Ą─▀^×V▓┘ū„Ż¼ŻęŻÕŻõŻ§ŻŃŻÕų„ę¬═Ļ│╔öĄ(sh©┤)ō■(j©┤)Ą─Š█╝»▓┘ū„Ż¼▌ö╚ļ▌ö│÷öĄ(sh©┤)ō■(j©┤)Š∙ęįĪ┤ŻļŻÕŻ∙Ż¼Ż÷ŻßŻņŻ§ŻÕĪĄĖ±╩Į┤µā”Ż¼ė├æ¶į┌╩╣ė├įōŠÄ│╠─Żą═ĢrŻ¼ų╗ąĶ░┤ššūį╝║╩ņŽżĄ─šZčįīŹ¼F(xi©żn)Ż═ŻßŻ║»öĄ(sh©┤)║═ŻęŻÕŻõŻ§ŻŃŻÕ║»╝┤┐╔Ż¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ┐“╝▄Ģ■ūįäėī”╚╬äš(w©┤)▀M(j©¼n)ąąäØĘųęįū÷ĄĮ▓óąął╠(zh©¬)ąąĪŻ
Ž┬├µ▒Š╬─īóęį╗∙ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─ķ_į┤īŹ¼F(xi©żn)Ż╚ŻßŻõŻ’Ż’Ż×ķų„Ż¼ī”Ųõų„ę¬╠žąį▀M(j©¼n)ąąĮķĮBĪŻ
Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╩Ū├µŽ“ė╔öĄ(sh©┤)Ū¦┼_ųąĄ═Č╦ėŗ╦ŃÖCĮM│╔Ą─┤¾ęÄ(gu©®)─ŻÖC╚║Č°įO(sh©©)ėŗĄ─Ż¼ŲõöUš╣─▄┴”Ą├ęµė┌ŲõŻ¾ŻĶŻßŻ“ŻÕŻõ¬▓ŻŅŻ’Ż¶ŻĶŻķŻŅŻńĮY(ji©”)śŗ(g©░u)ĪóĖ„éĆ╣Ø(ji©”)³cķgĄ─╦╔±Ņ║Žąį║═▌^ÅŖĄ─▄ø╝■╝ē╚▌Õe─▄┴”Ż║╣Ø(ji©”)³c┐╔ęį▒╗╚╬ęŌĄžÅ─ÖC╚║ųąęŲ│²Ż¼Č°Äū║§▓╗ė░Ēæ¼F(xi©żn)ėą╚╬äš(w©┤)Ą─ł╠(zh©¬)ąąŻ¼įō╝╝ąg(sh©┤)▒╗ĘQ×ķŻęŻ┴Ż╔Ż╬Ż©ŻęŻÕŻõŻ§ŻŅŻõŻßŻŅŻ¶Ż»ŻęŻÕŻņŻķŻßŻŌŻņŻÕŻ┴Ż“Ż“ŻßŻ∙Ż’ŻµŻ╔ŻŅŻõŻÕŻŻÕŻŅŻõŻÕŻŅŻ¶Ż©ŻßŻŅŻõŻ╔ŻŅŻÕŻ°ŻŻÕŻŅŻ¾ŻķŻ÷ŻÕŻ®Ż╬Ż’ŻõŻÕŻ¾Ż®Ż¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕū┐įĮĄ─öUš╣─▄┴”ęčį┌╣żśI(y©©)ĮńŻ©ŻŪŻ’Ż’ŻńŻņŻÕĪóŻŲŻßŻŃŻÕŻŌŻ’Ż’ŻļĪóŻ┬ŻßŻķŻõŻ§ĪóŻįŻßŻ’ŻŌĄ╚Ż®Ą├ĄĮ┴╦│õĘų“×ūCŻ¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕī”ė▓╝■Ą─ę¬Ū¾▌^Ą═Ż¼┐╔ęį╗∙ė┌«Éśŗ(g©░u)Ą─┴«ārė▓╝■üĒ┤ŅĮ©ÖC╚║Ż¼Ūę├Ō┘Mķ_į┤Ż¼ę“┤╦Ųõśŗ(g©░u)Į©│╔▒ŠĄ═ė┌▓óąąöĄ(sh©┤)ō■(j©┤)ÄņŻ¼Ą½╗∙ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─æ¬(y©®ng)ė├▄ø╝■ŽÓī”▌^╔┘Ż¼įSČÓöĄ(sh©┤)ō■(j©┤)Ęų╬÷╣”─▄ąĶę¬ė├æ¶ūįąąķ_░l(f©Ī)Ż¼Å─Č°Ģ■ī¦(d©Żo)ų┬╩╣ė├│╔▒ŠĄ─į÷╝ėĪŻ
ū„×ķķ_į┤ŽĄĮy(t©»ng)Ż¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕŠ▀ėą═Ļ╚½Ą─ķ_Ę┼ąįŻ║ŲõĪ┤ŻļŻÕŻ∙Ż¼Ż÷ŻßŻņŻ§ŻÕĪĄ┤µā”─Żą═Š▀ėą▌^ÅŖĄ─▒Ē¼F(xi©żn)┴”Ż¼┐╔ęį┤µā”╚╬ęŌĖ±╩ĮĄ─öĄ(sh©┤)ō■(j©┤)Ż╗Ż═ŻßŻ║═ŻęŻÕŻõŻ§ŻŃŻÕā╔éĆ╗∙▒ŠĄ─║»öĄ(sh©┤)Įė┐┌ę▓Įoė├æ¶╠ß╣®┴╦ūŃē“Ą─░l(f©Ī)ō]┐šķgŻ¼┐╔ęįīŹ¼F(xi©żn)Ė„ĘNÅ═(f©┤)ļsĄ─öĄ(sh©┤)ō■(j©┤)╠Ä└Ē╣”─▄Ż¼Ą½▀@ĘNķ_Ę┼ąįę▓ĦüĒę╗éĆå¢Ņ}Ż¼Š═╩Ūīó▒ŠüĒæ¬(y©®ng)ė╔öĄ(sh©┤)ō■(j©┤)Äņ╣▄└ĒŽĄĮy(t©»ng)═Ļ│╔Ą─╣żū„Ż¼ųT╚ń╬─╝■┤µā”Ė±╩ĮĄ─įO(sh©©)ėŗĪó─Ż╩Įą┼ŽóĄ─ėøõøĪóöĄ(sh©┤)ō■(j©┤)╠Ä└Ē╦ŃĘ©Ą─īŹ¼F(xi©żn)Ą╚Ż¼▐D(zhu©Żn)ęŲĮo┴╦│╠ą“åTŻ¼Å─Č°ī¦(d©Żo)ų┬│╠ą“åTžō(f©┤)ō·(d©Īn)▀^ųžŻ¼│╠ą“åT╦«ŲĮī”ŽĄĮy(t©»ng)╠Ä└Ēąį─▄ŲøQČ©ąįū„ė├Ż¼į┌─│ą®ŪķørŽ┬Ż¼īæŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ│╠ą“Ą─Ģrķg▀h(yu©Żn)┤¾ė┌īæŻėŻčŻ╠šZŠõĄ─ĢrķgŻ¼▓┐ĘųÅ═(f©┤)ļsĄ─Ż┬Ż╔ł¾▒ĒĘų╬÷Ż¼┐╔─▄āH│╠ą“Ą─ŠÄīæ║═š{(di©żo)įćŠ═ę¬║─┘MÄū╠ņĄ─ĢrķgĪŻ
╗∙ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕŲĮ┼_Ą─Ęų╬÷Ż¼¤oąĶÅ═(f©┤)ļsĄ─öĄ(sh©┤)ō■(j©┤)ŅA(y©┤)╠Ä└Ē║═īæ╚ļöĄ(sh©┤)ō■(j©┤)ÄņĄ─▀^│╠Ż¼Č°╩Ū┐╔ęįų▒Įė╗∙ė┌ŲĮ├µ╬─╝■▀M(j©¼n)ąąĘų╬÷Ż¼▓óŪęŲõ▓╔ė├Ą─ėŗ╦Ń─Ż╩Į╩ŪęŲäėėŗ╦ŃČ°ĘŪęŲäėöĄ(sh©┤)ō■(j©┤)Ż¼ę“┤╦┐╔ęįīóĘų╬÷čė▀tūŅąĪ╗»ĪŻ
į┌═¼Ą╚ė▓╝■Śl╝■Ž┬Ż¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕąį─▄▀h(yu©Żn)Ą═ė┌▓óąąöĄ(sh©┤)ō■(j©┤)ÄņŻ¼▀@╩Ūė╔ŲõūŅ│§Ą─įO(sh©©)ėŗČ©╬╗øQČ©Ą─Ż¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─įO(sh©©)ėŗ│§ųį╩Ū├µŽ“ĘŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ą─╠Ä└ĒŻ¼▀@ą®öĄ(sh©┤)ō■(j©┤)Š▀ėąöĄ(sh©┤)ō■(j©┤)┴┐┤¾Ż¼╠Ä└ĒÅ═(f©┤)ļsĄ╚╠ž³cŻ¼Č°Ūę═∙═∙╩Ūę╗┤╬ąį╠Ä└ĒŻ¼×ķ┴╦½@Ą├▌^║├Ą─öUš╣─▄┴”║═╚▌Õe─▄┴”Ż¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ▓╔╚Ī┴╦╗∙ė┌Æ▀├ĶĄ─╠Ä└Ē─Ż╩Į║═ī”ųąķgĮY(ji©”)╣¹▓Į▓Į╬’╗»Ą─ł╠(zh©¬)ąą▓▀┬įŻ¼Å─Č°ī¦(d©Żo)ų┬▌^Ė▀Ą─Ż╔Ż»ŻŽ┤·ārŻ¼×ķ┴╦£p╔┘öĄ(sh©┤)ō■(j©┤)ŅA(y©┤)╠Ä└ĒĢrķgŻ¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕø]ėą╩╣ė├─Ż╩ĮĪó╦„ę²Īó╬’╗»ęĢłDĄ╚╝╝ąg(sh©┤)╩ųČ╬Ż¼ŲõöĄ(sh©┤)ō■(j©┤)ŅA(y©┤)╠Ä└ĒāH╩Ūę╗┤╬öĄ(sh©┤)ō■(j©┤)╝ė▌d▓┘ū„Ż¼Ą½ė╔┤╦ī¦(d©Żo)ų┬┴╦ę╗éĆå¢Ņ}———▌^Ė▀Ą─į¬ĮMĮŌ╬÷┤·ārĪŻŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕŁh(hu©ón)Š│Ž┬Ż¼├┐éĆ▓ķįāČ╝╩Ūų▒ĮėÅ─╬─╝■ŽĄĮy(t©»ng)ųąūx╚ļįŁ╩╝öĄ(sh©┤)ō■(j©┤)╬─╝■Ż¼Č°ĘŪé„Įy(t©»ng)Ą─Å─öĄ(sh©┤)ō■(j©┤)Äņųąūx╚ļĮø(j©®ng)╠Ä└Ē▀^Ą─╬─╝■Ż¼ę“┤╦Ųõį¬ĮMĮŌ╬÷┤·ār▀h(yu©Żn)Ė▀ė┌ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņŻ¼ī”öĄ(sh©┤)ō■(j©┤)Ęų╬÷ŅI(l©½ng)ė“üĒšfŻ¼▀BĮė╩ŪĻP(gu©Īn)µI▓┘ū„Ż©╚ńé„Įy(t©»ng)Ą─ąŪą═▓ķįā║═č®╗©▓ķįāŠ∙╩Ūę└┘ćė┌▀BĮėüĒ╠Ä└Ē▓ķįāŻ®Ż¼Ą½Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╠Ä└Ē▀BĮėĄ─ąį─▄ė╚Ųõ▓╗▒M╚ń╚╦ęŌŻ¼įŁę“į┌ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕūŅ│§╩Ūßśī”å╬öĄ(sh©┤)ō■(j©┤)╝»įO(sh©©)ėŗĄ─╠Ä└Ē─Żą═Ż¼Č°▀BĮė▓┘ū„═∙═∙╔µ╝░ČÓéĆöĄ(sh©┤)ō■(j©┤)╝»Ż¼į┌└¹ė├Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕīŹ¼F(xi©żn)▀BĮėĢrŻ¼ūŅų▒ĮėĄ─ĘĮ╩Į╩Ū├┐éĆ╚╬äš(w©┤)ł╠(zh©¬)ąąę╗éĆī┘ąį╔ŽĄ─▀BĮė▓┘ū„Ż¼╚╗║¾īóČÓéĆŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╚╬äš(w©┤)═©▀^╬’╗»Ą─ųąķgĮY(ji©”)╣¹┤«ĮėŲüĒŻ¼▀@ĘNīŹ¼F(xi©żn)ĘĮ╩Į═∙═∙╔µ╝░ųąķgĮY(ji©”)╣¹Ą─ūxīæŻ¼Å─Č°ī¦(d©Żo)ų┬┤¾┴┐Ą─Ż╔Ż»ŻŽ▓┘ū„║═ŠW(w©Żng)Įj(lu©░)é„▌öĪŻ
Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ─┐Ū░╗∙▒Š▓╗╝µ╚▌¼F(xi©żn)ėąĄ─Ż┬Ż╔╣żŠ▀Ż¼įŁę“į┌ė┌Ųõ│§ųį▓ó▓╗╩Ūę¬│╔×ķöĄ(sh©┤)ō■(j©┤)ÄņŽĄĮy(t©»ng)Ż¼ę“┤╦╦³▓ó╬┤╠ß╣®ŻėŻčŻ╠Įė┐┌Ż¼Ą½ęčėąčąŠ┐ų┬┴”ė┌ŻėŻčŻ╠šZŠõ┼cŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╚╬äš(w©┤)Ą─▐D(zhu©Żn)ōQ╣żū„Ż©└²╚ńŻ╚ŻķŻ÷ŻÕŻ®Ż¼▀M(j©¼n)Č°ėą┐╔─▄īŹ¼F(xi©żn)Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ┼c¼F(xi©żn)┤µŻ┬Ż╔╣żŠ▀Ą─╝µ╚▌ĪŻ
ŻĄ ▓óąąöĄ(sh©┤)ō■(j©┤)Äņ║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─╗ņ║Ž╝▄śŗ(g©░u)
╗∙ė┌ęį╔ŽĘų╬÷Ż¼╬ęéā┐╔ęįŪÕ│■Ąž┐┤│÷Ż¼╗∙ė┌▓óąąöĄ(sh©┤)ō■(j©┤)Äņ║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕīŹ¼F(xi©żn)Ą─öĄ(sh©┤)ō■(j©┤)é}ÄņŽĄĮy(t©»ng)Č╝▓╗╩Ū┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─└ĒŽļĘĮ░ĖŻ¼ßśī”ā╔š▀──éĆĖ³▀m║ŽĢr┤·ąĶŪ¾Ą─å¢Ņ}Ż¼śI(y©©)ĮńĮ³─Ļš╣ķ_┴╦╝ż┴ęĀÄšōŻ¼«ö(d©Īng)Ū░╗∙▒Š▀_(d©ó)│╔╚ńŽ┬╣▓ūRŻ║▓óąąöĄ(sh©┤)ō■(j©┤)Äņ║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╩Ū╗źčaĻP(gu©Īn)ŽĄŻ¼æ¬(y©®ng)įōŽÓ╗źīW(xu©”)┴Ģ(x©¬)Ż¼╗∙ė┌įōė^³cŻ¼┤¾┴┐蹊┐ų°╩ųīóā╔š▀ĮY(ji©”)║ŽŲüĒŻ¼Ų┌═¹įO(sh©©)ėŗ│÷╝µŠ▀ā╔š▀ā×(y©Łu)³cĄ─öĄ(sh©┤)ō■(j©┤)Ęų╬÷ŲĮ┼_Ż¼▀@ĘN╝▄śŗ(g©░u)ėų┐╔ęįĘų×ķ╚²ŅÉŻ║▓óąąöĄ(sh©┤)ō■(j©┤)Äņų„ī¦(d©Żo)ą═ĪóŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕų„ī¦(d©Żo)ą═ĪóŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ║═▓óąąöĄ(sh©┤)ō■(j©┤)Äņ╝»│╔ą═Ż©▒ĒŻ▓ī”Ż│ĘN╝▄śŗ(g©░u)▀M(j©¼n)ąą┴╦ī”▒╚Ęų╬÷Ż®ĪŻ
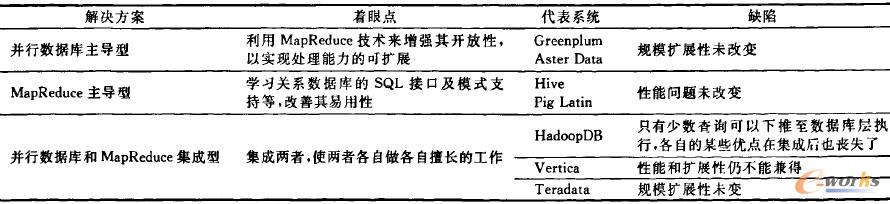
▒ĒŻ▓ ╗ņ║Ž╝▄śŗ(g©░u)ą═ĮŌøQĘĮ░Ėī”▒╚Ęų╬÷
ŻĄŻ«Ż▒ ▓óąąöĄ(sh©┤)ō■(j©┤)Äņų„ī¦(d©Żo)ą═
įōĘNĘĮ╩ĮĻP(gu©Īn)ūóė┌╚ń║╬└¹ė├Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕüĒį÷ÅŖ▓óąąöĄ(sh©┤)ō■(j©┤)ÄņĄ─öĄ(sh©┤)ō■(j©┤)╠Ä└Ē─▄┴”Ż¼┤·▒ĒąįŽĄĮy(t©»ng)╩ŪŻŪŻ“ŻÕŻÕŻŅŻŻņŻ§ŻĒŻ©ęč▒╗Ż┼Ż═Ż├╩š┘ÅŻ®║═Ż┴Ż¾Ż¶ŻÕŻ“Ż─ŻßŻ¶ŻßŻ©ęč▒╗ŻįŻÕŻ“ŻßŻõŻßŻ¶Żß╩š┘ÅŻ®Ż¼Ż┴Ż¾Ż¶ŻÕŻ“Ż─ŻßŻ¶ŻßīóŻėŻčŻ╠║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ▀M(j©¼n)ąąĮY(ji©”)║ŽŻ¼ßśī”┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷╠ß│÷┴╦ŻėŻčŻ╠Ż»Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ┐“╝▄ĪŻ
įō┐“╝▄į╩įSė├æ¶╩╣ė├Ż├Ż½Ż½ĪóŻĻŻßŻ÷ŻßĪ󯹯∙Ż¶ŻĶŻ’ŻŅĄ╚šZčįŠÄīæŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ║»öĄ(sh©┤)Ż¼ŠÄīæĄ─║»öĄ(sh©┤)┐╔ęįū„×ķę╗éĆūė▓ķįāį┌ŻėŻčŻ╠ųą╩╣ė├Ż¼Å─Č°═¼Ģr½@Ą├ŻėŻčŻ╠Ą─ęūė├ąį║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─ķ_Ę┼ąįŻ¼▓╗āH╚ń┤╦Ż¼Ż┴Ż¾Ż¶ŻÕŻ“Ż─ŻßŻ¶Żß╗∙ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕīŹ¼F(xi©żn)┴╦Ż│Ż░ČÓéĆĮy(t©»ng)ėŗ▄ø╝■░³Ż¼Å─Č°īóöĄ(sh©┤)ō■(j©┤)Ęų╬÷═ŲŽ“öĄ(sh©┤)ō■(j©┤)Äņā╚(n©©i)▀M(j©¼n)ąąŻ©öĄ(sh©┤)ō■(j©┤)Äņā╚(n©©i)Ęų╬÷Ż®Ż¼┤¾┤¾╠ß╔²┴╦öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─ąį─▄ĪŻ
ŻŪŻ“ŻÕŻÕŻŅŻŻņŻ§ŻĒę▓į┌ŲõöĄ(sh©┤)ō■(j©┤)Äņųąę²╚ļ┴╦Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╠Ä└Ē╣”─▄Ż¼Ųõł╠(zh©¬)ąąę²Ūµ┐╔ęį═¼Ģr╠Ä└ĒŻėŻčŻ╠▓ķįā║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╚╬äš(w©┤)Ż¼▀@ĘNĘĮ╩Įį┌┤·┤a╝ēš¹║Ž┴╦ŻėŻčŻ╠║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕŻ║ŻėŻčŻ╠┐╔ęįų▒Įė╩╣ė├Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╚╬äš(w©┤)Ą─▌ö│÷Ż¼═¼ĢrŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╚╬äš(w©┤)ę▓┐╔ęį╩╣ė├ŻėŻčŻ╠Ą─▓ķįāĮY(ji©”)╣¹ū„×ķ▌ö╚ļĪŻ
┐éĄ─üĒšfŻ¼▀@ą®ŽĄĮy(t©»ng)Č╝╝»ųąė┌└¹ė├Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕüĒĖ─▀M(j©¼n)▓óąąöĄ(sh©┤)ō■(j©┤)ÄņĄ─öĄ(sh©┤)ō■(j©┤)╠Ä└Ē╣”─▄Ż¼ŲõĖ∙▒Šąįå¢Ņ}———┐╔öUš╣─▄┴”║═╚▌Õe─▄┴”▓ó╬┤Ė─ūāĪŻ
ŻĄŻ«Ż▓Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕų„ī¦(d©Żo)ą═
įōĘĮŽ“Ą─蹊┐ų„ę¬╝»ųąė┌└¹ė├ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─ŻėŻčŻ╠Įė┐┌║═ī”─Ż╩ĮĄ─ų¦│ųĄ╚╝╝ąg(sh©┤)üĒĖ─╔ŲŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─ęūė├ąįŻ¼┤·▒ĒŽĄĮy(t©»ng)╩ŪŻ╚ŻķŻ÷ŻÕĪ󯹯ķŻńŻ╠ŻßŻ¶ŻķŻŅĄ╚ĪŻ
Ż╚ŻķŻ÷ŻÕ╩ŪŻŲŻßŻŃŻÕŻŌŻ’Ż’Żļ╠ß│÷Ą─╗∙ė┌Ż╚ŻßŻõŻ’Ż’ŻĄ─┤¾ą═öĄ(sh©┤)ō■(j©┤)é}ÄņŻ¼Ųõ─┐ś╦(bi©Īo)╩Ū║å╗»Ż╚ŻßŻõŻ’Ż’Ż╔ŽĄ─öĄ(sh©┤)ō■(j©┤)Š█╝»ĪóŻßŻõ¬▓ŻĶŻ’ŻŃ▓ķįā╝░┤¾öĄ(sh©┤)ō■(j©┤)╝»Ą─Ęų╬÷Ą╚▓┘ū„Ż¼ęį£p▌p│╠ą“åTĄ─žō(f©┤)ō·(d©Īn)Ż¼╦³ĮĶĶbĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ──Ż╩Į╣▄└ĒĪóŻėŻčŻ╠Įė┐┌Ą╚╝╝ąg(sh©┤)Ż¼░čĮY(ji©”)śŗ(g©░u)╗»Ą─öĄ(sh©┤)ō■(j©┤)╬─╝■ė│╔õ×ķöĄ(sh©┤)ō■(j©┤)Äņ▒ĒŻ¼╠ß╣®ŅÉ╦Ųė┌ŻėŻčŻ╠Ą─├Ķ╩÷ąįšZčįŻ╚ŻķŻ÷ŻÕŻčŻ╠╣®│╠ą“åT╩╣ė├Ż¼┐╔ūįäėīóŻ╚ŻķŻ÷ŻÕŻčŻ╠šZŠõĮŌ╬÷│╔ę╗ā×(y©Łu)╗»Ą─Ż═Żß¬▓ŻŻęŻÕŻõŻ§ŻŃŻÕ╚╬äš(w©┤)ł╠(zh©¬)ąąą“┴ąŻ¼┤╦═ŌŻ¼╦³ę▓ų¦│ųė├æ¶ūįČ©┴xĄ─Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ║»öĄ(sh©┤)ĪŻ
ŻąŻķŻńŻ╠ŻßŻ¶ŻķŻŅ╩ŪŻ┘ŻßŻĶŻ’Ż’ŻĪ╠ß│÷Ą─ŅÉ╦Ųė┌Ż╚ŻķŻ÷ŻÕĄ─┤¾öĄ(sh©┤)ō■(j©┤)╝»Ęų╬÷ŲĮ┼_Ż¼ā╔š▀Ą─ģ^(q©▒)äeų„ę¬į┌ė┌šZčįĮė┐┌ĪŻ
Ż╚ŻķŻ÷ŻÕ╠ß╣®┴╦ŅÉ╦ŲŻėŻčŻ╠Ą─Įė┐┌Ż¼ŻąŻķŻńŻ╠ŻßŻ¶ŻķŻŅ╠ß╣®Ą─╩Ūę╗ĘN╗∙ė┌▓┘ū„Ę¹Ą─öĄ(sh©┤)ō■(j©┤)┴„╩ĮĄ─Įė┐┌Ż¼łDŻ│╩ŪŻąŻķŻńŻ╠ŻßŻ¶ŻķŻŅį┌╠Ä└Ē▓ķįāĢrĄ─ę╗éĆ▓┘ū„īŹ└²Ż¼įō▓ķįāĄ──┐Ą─╩Ūšę│÷“─Ļ²gį┌Ż▒ŻĖĪ½Ż▓ŻĄų▄Üqų«ķgĄ─ė├æ¶Ż©ŻšŻ¾ŻÕŻ“Ż¾Ż®ūŅŅlĘ▒įLå¢Ą─ŻĄéĆĒō├µŻ©ŻąŻßŻńŻÕŻ¾Ż®”Ż¼Å─łDŻ│┐╔ęį┐┤│÷Ż¼ŻąŻķŻń╠ß╣®Ą─▓┘ū„Įė┐┌ŅÉ╦Ųė┌ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─▓┘ū„Ę¹Ż©ī”æ¬(y©®ng)łDųąėęé╚(c©©)▓┐ĘųųąĄ─├┐ę╗ąą├³┴ŅŻ®Ż¼ė├æ¶▓ķįāĄ──_▒ŠŅÉ╦Ųė┌▀ē▌ŗ▓ķįāėŗäØŻ©ī”æ¬(y©®ng)łDųąū¾é╚(c©©)▓┐ĘųŻ®Ż¼ę“┤╦Ż¼ę▓┐╔ęįšfŻąŻķŻń└¹ė├▓┘ū„Ę¹üĒī”Ż╚ŻßŻõŻ’Ż’Ż▀M(j©¼n)ąąĘŌčbŻ¼Ż╚ŻķŻ÷ŻÕ└¹ė├ŻėŻčŻ╠▀M(j©¼n)ąąĘŌčbĪŻ
ŻĄŻ«Ż│Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ║═▓óąąöĄ(sh©┤)ō■(j©┤)Äņ╝»│╔ą═
įōĘĮŽ“Ą─┤·▒Ēąį蹊┐╩Ū꫶ö┤¾īW(xu©”)╠ß│÷Ą─Ż╚ŻßŻõŻ’Ż’ŻŻ─Ż┬Ż©ęčė┌Ż▓Ż░Ż▒Ż▒─Ļ╔╠śI(y©©)╗»×ķŻ╚ŻßŻõŻßŻŻ¶Ż®ŻėŻ¶Ż’ŻŅŻÕŻŌŻ“ŻßŻļŻÕŻ“Ą╚╚╦įO(sh©©)ėŗĄ─ŻųŻÕŻ“Ż¶ŻķŻŃŻßöĄ(sh©┤)ō■(j©┤)Äņ║═Ż╬Ż├Żę╣½╦ŠĄ─ŻįŻÕŻ“ŻßŻõŻßŻ¶ŻßöĄ(sh©┤)ō■(j©┤)ÄņĪŻ

łDŻ│ ŻąŻķŻńŻ╠ŻßŻ¶ŻķŻŅĄ─ę╗éĆ▓ķįā╩Š└²Ż©ėę▀ģ×ķīŹļH─_▒ŠŻ®
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.hanmeixuan.com/
▒Š╬─ś╦(bi©Īo)Ņ}Ż║╝▄śŗ(g©░u)┤¾öĄ(sh©┤)ō■(j©┤)Ż║╠¶æ(zh©żn)Īó¼F(xi©żn)ĀŅ┼cš╣═¹(╔Ž)
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.hanmeixuan.com/html/support/1112158844.html



▀xą═ųąą─")
¾w“×ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")