Ż╚ŻßŻõŻ’Ż’ŻŻ─Ż┬Ą─║╦ą─╦╝Žļ╩Ū└¹ė├Ż╚ŻßŻõŻ’Ż’Żū„×ķš{(di©żo)Č╚īė║═ŠW(w©Żng)Įj(lu©░)£Ž═©īėŻ¼ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņū„×ķł╠(zh©¬)ąąę²ŪµŻ¼▒M┐╔─▄Ąžīó▓ķįāē║╚ļöĄ(sh©┤)ō■(j©┤)Äņīė╠Ä└ĒŻ¼─┐ś╦╩ŪŽļĮĶų·Ż╚ŻßŻõŻ’Ż’Ż┐“╝▄üĒ½@Ą├▌^║├Ą─╚▌Õeąį║═ī”«Éśŗ(g©░u)Łh(hu©ón)Š│Ą─ų¦│ųŻ╗═©▀^īó▓ķįā▒M┐╔─▄═Ų╚ļöĄ(sh©┤)ō■(j©┤)Äņųął╠(zh©¬)ąąüĒ½@Ą├ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─ąį─▄ā×(y©Łu)ä▌Ż¼Ż╚ŻßŻõŻ’Ż’ŻŻ─Ż┬Ą─╦╝Žļ╩Ū╔Ņ▀hĄ─Ż¼Ą½─┐Ū░╔ą¤oæ¬(y©®ng)ė├░Ė└²Ż¼įŁę“į┌ė┌Ż║
Ż©Ż▒Ż®ŲõöĄ(sh©┤)ō■(j©┤)ŅA(y©┤)╠Ä└Ē┤·ār▀^Ė▀Ż║öĄ(sh©┤)ō■(j©┤)ąĶę¬▀Mąąā╔┤╬ĘųĮŌ║═ę╗┤╬öĄ(sh©┤)ō■(j©┤)Äņ╝ė▌d▓┘ū„║¾▓┼─▄╩╣ė├Ż╗
Ż©Ż▓Ż®īó▓ķįā═ŲŽ“öĄ(sh©┤)ō■(j©┤)Äņīėų╗╩Ū╔┘öĄ(sh©┤)ŪķørŻ¼┤¾ČÓöĄ(sh©┤)ŪķørŽ┬Ż¼▓ķįā?n©©i)įė╔Ż╚ŻķŻ÷ŻÕ═Ļ│╔Ż¼ę“×?a href="http://m.hanmeixuan.com/" title="" target="_blank" >öĄ(sh©┤)ō■(j©┤)é}Äņ▓ķįā═∙═∙╔µ╝░ČÓ▒Ē▀BĮėŻ¼ė╔ė┌▀BĮėĄ─Å═(f©┤)ļsąįŻ¼ļyęįū÷ĄĮį┌▒Ż│ų▀BĮėöĄ(sh©┤)ō■(j©┤)Šų▓┐ąįĄ─Ū░╠ߎ┬īóģó─│ĘN─Ż╩ĮäØĘųŻ╗
Ż©Ż│Ż®ŠSūo┤·ār▀^Ė▀Ż¼▓╗āHꬊSūoŻ╚ŻßŻõŻ’Ż’ŻŽĄĮy(t©»ng)Ż¼▀ĆꬊSūo├┐éĆöĄ(sh©┤)ō■(j©┤)Äņ╣Ø(ji©”)³cŻ╗
Ż©Ż┤Ż®─┐Ū░╔ą▓╗ų¦│ųöĄ(sh©┤)ō■(j©┤)Ą─äėæB(t©żi)äØĘųŻ¼ąĶę¬╩ų╣żĘĮ╩ĮīóöĄ(sh©┤)ō■(j©┤)ę╗┤╬ąįäØĘų║├Ż¼┐éĄ─üĒšfŻ¼Ż╚ŻßŻõŻ’Ż’ŻŻ─Ż┬į┌─│ą®ŪķørŽ┬Ż¼┐╔ęį═¼ĢrīŹ¼F(xi©żn)ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─Ė▀ąį─▄╠žąį║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─öUš╣ąįĪó╚▌ÕeąįŻ¼Ą½═¼Ģrę▓å╩╩¦┴╦ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņ║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ──│ą®ā×(y©Łu)³cŻ¼▒╚╚ńŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ▌^Ą═Ą─ŅA(y©┤)╠Ä└Ē┤·ār║═ŠSūo┤·ārĪóĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─äėæB(t©żi)öĄ(sh©┤)ō■(j©┤)ųžĘų▓╝Ą╚ĪŻ
ŻųŻÕŻ“Ż¶ŻķŻŃŻß▓╔ė├Ą─╩Ū╣▓┤µ▓▀┬įŻ║Ė∙ō■(j©┤)Ż╚ŻßŻõŻ’Ż’Ż║═ŻųŻÕŻ“Ż¶ŻķŻŃŻßĖ„ūįĄ─╠Ä└Ēā×(y©Łu)ä▌Ż¼ī”öĄ(sh©┤)ō■(j©┤)╠Ä└Ē╚╬äš(w©┤)▀MąąäØĘųŻ¼▒╚╚ńŻ╚ŻßŻõŻ’Ż’Żžōž¤ĘŪĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ą─╠Ä└ĒŻ¼ŻųŻÕŻ“Ż¶ŻķŻŃŻßžōž¤ĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)Ą─╠Ä└ĒŻ╗Ż╚ŻßŻõŻ’Ż’Żžōž¤║─ĢrĄ─┼·┴┐Å═(f©┤)ļs╠Ä└ĒŻ¼ŻųŻÕŻ“Ż¶ŻķŻŃŻßžōž¤Ė▀ąį─▄Ą─Į╗╗ź╩Į▓ķįāĄ╚Ż¼Å─Č°īóā╔š▀ĮY(ji©”)║ŽŲüĒŻ¼ŻųŻÕŻ“Ż¶ŻķŻŃŻßīŹļH▓╔ė├Ą─╩Ūā╔╠ūŽĄĮy(t©»ng)Ż¼═¼Ģrų¦│ųį┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╚╬äš(w©┤)ųąų▒ĮėįLå¢ŻųŻÕŻ“Ż¶ŻķŻŃŻßöĄ(sh©┤)ō■(j©┤)ÄņųąĄ─öĄ(sh©┤)ō■(j©┤)Ż¼ė╔ė┌ĮY(ji©”)śŗ(g©░u)╗»öĄ(sh©┤)ō■(j©┤)╚įį┌ŻųŻÕŻ“Ż¶ŻķŻŃŻßųą╠Ä└ĒŻ¼į┌╠Ä└ĒĮY(ji©”)śŗ(g©░u)╗»┤¾öĄ(sh©┤)ō■(j©┤)╔ŽĄ─▓ķįāĘų╬÷ĢrŻ¼╚į├µ┼RöUš╣ąįå¢Ņ}Ż╗╚ń╣¹īó▓ķįā═ŲŽ“Ż╚ŻßŻõŻ’Ż’Ż▀MąąŻ¼ėųīó├µ┼Rąį─▄å¢Ņ}Ż¼ę“┤╦Ż¼ŻųŻÕŻ“Ż¶ŻķŻŃŻßĄ─öUš╣ąįå¢Ņ}║═Ż╚ŻßŻõŻ’Ż’ŻĄ─ąį─▄å¢Ņ}į┌įōŽĄĮy(t©»ng)ųą╣▓┤µĪŻ
┼cŪ░ā╔š▀ŽÓ▒╚Ż¼ŻįŻÕŻ“ŻßŻõŻßŻ¶ŻßĄ─╝»│╔ŽÓī”║åå╬Ż¼ŻįŻÕŻ“ŻßŻõŻßŻ¶Żß▓╔ė├┴╦┤µā”īėĄ─š¹║ŽŻ║Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╚╬äš(w©┤)┐╔ęįÅ─ŻįŻÕŻ“ŻßŻõŻßŻ¶ŻßöĄ(sh©┤)ō■(j©┤)Äņųąūx╚ĪöĄ(sh©┤)ō■(j©┤)Ż¼ŻįŻÕŻ“ŻßŻõŻßŻ¶ŻßöĄ(sh©┤)ō■(j©┤)Äņę▓┐╔ęįÅ─Ż╚ŻßŻõŻ’Ż’ŻĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)╔Žūx╚ĪöĄ(sh©┤)ō■(j©┤)Ż¼═¼śėŻ¼ŻįŻÕŻ“ŻßŻõŻßŻ¶Żß║═Ż╚ŻßŻõŻ’Ż’ŻĖ„ūįĄ─Ė∙▒Šąįå¢Ņ}Č╝╬┤ĮŌøQĪŻ
ŻČ 蹊┐¼F(xi©żn)ĀŅ
ī”▓óąąöĄ(sh©┤)ō■(j©┤)ÄņüĒųvŻ¼ŲõūŅ┤¾å¢Ņ}į┌ė┌ėąŽ▐Ą─öUš╣─▄┴”║═┤²Ė─▀MĄ─▄ø╝■╝ē╚▌Õe─▄┴”Ż╗Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─ūŅ┤¾å¢Ņ}į┌ė┌ąį─▄Ż¼ė╚Ųõ╩Ū▀BĮė▓┘ū„Ą─ąį─▄Ż╗╗ņ║Ž╩Į╝▄śŗ(g©░u)Ą─ĻP(gu©Īn)µI╩ŪŻ¼╚ń║╬─▄▒M┐╔─▄ČÓĄž░č╣żū„═ŲŽ“║Ž▀mĄ─ł╠(zh©¬)ąąę²ŪµŻ©▓óąąöĄ(sh©┤)ō■(j©┤)Äņ╗“Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕŻ®Ż¼▒Š╣Ø(ji©”)ī”Į³─ĻüĒį┌▀@ą®å¢Ņ}╔ŽĄ─蹊┐ū÷ę╗Ęų╬÷║═Üw╝{ĪŻ
ŻČŻ«Ż▒ ▓óąąöĄ(sh©┤)ō■(j©┤)ÄņöUš╣ąį║═╚▌Õeąį蹊┐
╚A╩óŅD┤¾īW(xu©”)į┌╬─½IŻ█Ż▓Ż│Ż▌ųą╠ß│÷┴╦┐╔ęį╔·│╔Š▀éõ╚▌Õe─▄┴”Ą─▓óąął╠(zh©¬)ąąėŗäØā×(y©Łu)╗»Ų„Ż¼įōā×(y©Łu)╗»Ų„┐╔ęįę└┐┐▌ö╚ļĄ─▓óąął╠(zh©¬)ąąėŗäØĪóĖ„éĆ▓┘ū„Ę¹Ą─╚▌Õe▓▀┬į╝░▓ķįā╩¦öĪĄ─Ų┌═¹ųĄĄ╚Ż¼▌ö│÷ę╗éĆŠ▀éõ╚▌Õe─▄┴”Ą─▓óąął╠(zh©¬)ąąėŗäØŻ¼į┌įōėŗäØųąŻ¼├┐éĆ▓┘ū„Ę¹Č╝┐╔ęį▓╔╚Ī▓╗═¼Ą─╚▌Õe▓▀┬įŻ¼į┌╩¦öĪĢrāHųžą┬ł╠(zh©¬)ąąŲõūė▓┘ū„Ę¹Ż©į┌─│╣Ø(ji©”)³c╔Ž▀\ąąĄ─▓┘ū„Ę¹Ż®Ą─╚╬äš(w©┤)üĒ▒▄├Ōš¹éĆ▓ķįāĄ─ųžą┬ł╠(zh©¬)ąąĪŻ
Ż═Ż╔Żįė┌Ż▓Ż░Ż▒Ż░─ĻįO(sh©©)ėŗĄ─ŻŽŻ¾ŻŻ“ŻÕŻ∙ŽĄĮy(t©»ng)╗∙ė┌ŠS▒Ēį┌Ė„éĆ╣Ø(ji©”)³c╚½Å═(f©┤)ųŲĪó╩┬īŹ▒ĒÖMŽ“ŪąĘų▓ó╚▀ėÓéõĘ▌Ą─öĄ(sh©┤)ō■(j©┤)Ęų▓╝▓▀┬įŻ¼īóę╗ąŪą═▓ķįāäØĘų×ķ▒ŖČÓ¬Ü┴óūė▓ķįāŻ¼├┐éĆūė▓ķįāį┌ł╠(zh©¬)ąą╩¦öĪĢrČ╝┐╔ęįį┌ŲõéõĘ▌╣Ø(ji©”)³c╔Žųžą┬ł╠(zh©¬)ąąŻ¼Č°▓╗ė├ųžū÷š¹éĆ▓ķįāŻ¼╩╣Ą├öĄ(sh©┤)ō■(j©┤)é}Äņ▓ķįā½@Ą├ŅÉ╦ŲŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─╚▌Õe─▄┴”Ż¼öĄ(sh©┤)ō■(j©┤)é}ÄņöUš╣ąįĘĮ├µĄ─蹊┐▌^╔┘Ż¼ųąć°╚╦├±┤¾īW(xu©”)Ą─Ż╠ŻķŻŅŻÕŻßŻ“Ż─Ż┬įŁą═ī┘ė┌▀@ĘĮ├µĄ─蹊┐Ż¼įö╝ÜģóęŖŻĘŻ«Ż▒╣Ø(ji©”)ĪŻ
ŻČŻ«Ż▓Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕąį─▄ā×(y©Łu)╗»čąŠ┐
Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─ąį─▄ā×(y©Łu)╗»čąŠ┐╝»ųąė┌ī”ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─Ž╚▀M╝╝ąg(sh©┤)║═╠žąįĄ─ęŲų▓╔ŽĪŻ
ŻŲŻßŻŃŻÕŻŌŻ’Ż’Żļ║═ČĒ║źČĒų▌┴ó┤¾īW(xu©”)║Žū„Ż¼īóĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─╗ņ║Ž╩Į┤µā”─Żą═æ¬(y©®ng)ė├ė┌Ż╚ŻßŻõŻ’Ż’ŻŲĮ┼_Ż¼╠ß│÷┴╦ŻęŻ├ŻŲŻķŻņŻÕ┤µā”Ė±╩ĮĪŻ┼cų«▓╗═¼Ż¼╬─½IŻ█Ż▓ŻČŻ▌īó┴ą┤µā”╝╝ąg(sh©┤)ę²╚ļŻ╚ŻßŻõŻ’Ż’ŻŲĮ┼_Ż¼Ż╚ŻßŻõŻ’Ż’ŻŻ½Ż½ŽĄĮy(t©»ng)▀\ė├┴╦é„Įy(t©»ng)öĄ(sh©┤)ō■(j©┤)ÄņĄ─╦„ę²╝╝ąg(sh©┤)Ż¼▓ó═©▀^Ęųģ^(q©▒)öĄ(sh©┤)ō■(j©┤)▓óų├Ż©Ż├Ż’¬▓ŻąŻßŻ“Ż¶ŻķŻ¶ŻķŻ’ŻŅŻ®Ą─ĘĮ╩ĮüĒ╠ß╔²ąį─▄Ż¼╬─½IŻ█Ż▓ŻĖŻ▓Ż╣Ż▌╗∙ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕīŹ¼F(xi©żn)┴╦ęį┴„╦«ŠĆĘĮ╩Įį┌Ė„éĆ▓┘ū„Ę¹ķgé„▀föĄ(sh©┤)ō■(j©┤)Ż¼Å─Č°┐sČ╠┴╦╚╬äš(w©┤)ł╠(zh©¬)ąąĢrķgŻ╗į┌ŠĆŠ█╝»Ż©Ż’ŻŅŻņŻķŻŅŻÕŻßŻńŻńŻ“ŻÕŻńŻßŻ¶ŻķŻ’ŻŅŻ®Ą─▓┘ū„─Ż╩Į╩╣Ą├ė├æ¶┐╔ęįį┌▓ķįāł╠(zh©¬)ąą▀^│╠ųą┐┤ĄĮ▓┐Ęų▌^įńĘĄ╗žĄ─ĮY(ji©”)╣¹Ż¼ā╔š▀Ą─▓╗═¼ų«╠Äį┌ė┌Ū░š▀╚į╗∙ė┌Ż¾Ż’Ż“Ż¶¬▓ŻĒŻÕŻ“ŻńŻÕĘĮ╩ĮüĒīŹ¼F(xi©żn)┴„╦«ŠĆŻ¼ų╗╩Ūīó┼┼ą“Ą╚▓┘ū„═ŲŽ“┴╦Ż“ŻÕŻõŻ§ŻŃŻÕŻ“Ż¼▓┐ĘųŪķørŽ┬╚įĢ■│÷¼F(xi©żn)┴„╦«ŠĆ═ŻŅDĄ─ŪķørŻ╗Č°║¾š▀└¹ė├ŻĶŻßŻ¾ŻĶĘĮ╩ĮüĒĘų▓╝öĄ(sh©┤)ō■(j©┤)Ż¼─▄īŹ¼F(xi©żn)Ė³║├Ą─▓óąą┴„╦«ŠĆ▓┘ū„Ż¼╬─½IŻ█Ż│Ż░Ż▌╠ß│÷┴╦Ż═ŻęŻėŻĶŻßŻ“ŻÕ╝▄śŗ(g©░u)Ż¼ī”┼·┴┐▓ķįā▀Mąą▐D(zhu©Żn)ōQŻ¼īó┐╔╣▓ŽĒÆ▀├ĶĪó╣▓ŽĒŻ═ŻßŻ▌ö│÷ĮY(ji©”)╣¹Ą╚Ą─ę╗ĮM╚╬äš(w©┤)║Ž▓ó×ķę╗éĆŻ¼ęį╠ß╔²ąį─▄Ż¼ą┬╝ėŲ┬ć°┴ó┤¾īW(xu©”)ī”ė░ĒæŻ╚ŻßŻõŻ’Ż’Żąį─▄Ą─ę“╦žū÷┴╦╔Ņ╚ļĘų╬÷Ż¼▓ó╠ß│÷┴╦ŻĄĒŚėąą¦Ą─ā×(y©Łu)╗»╝╝ąg(sh©┤)Ż¼╩╣Ą├Ż╚ŻßŻõŻ’Ż’ŻĄ─ąį─▄╠ß╔²┴╦Į³Ż│▒ČŻ¼▒ŲĮ³ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─ąį─▄ĪŻ
Į³─ĻĄ─蹊┐¤ß³c╩Ū╗∙ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─▀BĮė▓┘ū„Ą─ąį─▄ā×(y©Łu)╗»Ż¼╬─½IŻ█Ż│Ż▒Ż▌ī”Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕŲĮ┼_Ą─ā╔▒Ē▀BĮė╦ŃĘ©ū÷┴╦┐éĮY(ji©”)Ż¼╠ß│÷┴╦Ż═ŻßŻČ╦▀BĮėĪóŻęŻÕŻõŻ§ŻŃŻÕČ╦▀BĮė╝░ÅV▓ź╩Į▀BĮėĄ╚╦ŃĘ©Ż¼╬─½IŻ█Ż│Ż▓Ż▌ī”Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ┐“╝▄▀Mąą┴╦öUš╣Ż¼į┌ŻęŻÕŻõŻ§ŻŃŻÕ▓Į¾E║¾╠Ē╝ė┴╦ę╗Ż═ŻÕŻ“ŻńŻÕ▓Į¾EüĒ═Ļ│╔▀BĮė▓┘ū„Ż¼╠ß│÷Ą─Ż═ŻßŻ¬▓ŻęŻÕŻõŻ§ŻŃŻÕ¬▓Ż═ŻÕŻ“ŻńŻÕ┐“╝▄┐╔ęį═¼Ģr╠Ä└Ēā╔éĆ«Éśŗ(g©░u)öĄ(sh©┤)ō■(j©┤)į┤Ą─öĄ(sh©┤)ō■(j©┤)Ż¼ī”ė┌ČÓ▒Ē▀BĮėŻ¼«öŪ░ų„┴„Ą─蹊┐╝»ųąė┌āH═©▀^ę╗éĆ╚╬äš(w©┤)üĒ═Ļ│╔▀BĮė▓┘ū„Ż¼╬─½I╠ß│÷┴╦ę╗ī”ČÓÅ═(f©┤)ųŲĄ─ĘĮĘ©Ż¼į┌Ż═ŻßŻļAČ╬ĮY(ji©”)╩°║¾Ż¼×ķ▒ŻūC▀BĮė▓┘ū„Ą─Šų▓┐ąįŻ¼į¬ĮMĢ■▒╗Å═(f©┤)ųŲĄĮČÓéĆ╣Ø(ji©”)³cŻ¼Ą½į┌╣Ø(ji©”)³cöĄ(sh©┤)║═öĄ(sh©┤)ō■(j©┤)┴┐į÷┤¾Ą─ŪķørŽ┬Ż¼Ģ■ĦüĒŻ╔Ż»ŻŽ┴┐╝░ŠW(w©Żng)Įj(lu©░)é„▌ö┴┐Ą─Š▐┤¾į÷ķLŻ¼Ż╠ŻņŻßŻĒŻß═©▀^ŅA(y©┤)┼┼ą“║═░┤▀BĮėī┘ąįäØĘųöĄ(sh©┤)ō■(j©┤)Ą─ĘĮ╩ĮüĒĮĄĄ═ąŪą═▀BĮėĄ─┤·ārŻ¼Ą½ę¬ĖČ│÷┐╔ė^Ą─ŅA(y©┤)╠Ä└Ē┤·ār║═┐šķg┤·ārŻ¼▓╗═¼ė┌ęį╔ŽĄ╚ųĄ▀BĮėā×(y©Łu)╗»Ż¼╬─½IŻ█Ż│ŻČŻ▌╠ß│÷┴╦ßśī”╚╬ęŌ▀BĮėŚl╝■Ą─ā×(y©Łu)╗»─Żą═Ż¼ęį╔Ž▀BĮėĘĮ╩ĮČ╝╩ŪŽ╚ł╠(zh©¬)ąą▀BĮėŻ¼╚╗║¾į┌▀BĮė║¾Ą─öĄ(sh©┤)ō■(j©┤)╔Žł╠(zh©¬)ąąŠ█╝»▓┘ū„Ż¼Č°ųąć°╚╦├±┤¾īW(xu©”)Ą─Ż─Ż§ŻĒŻŌŻ’ŽĄĮy(t©»ng)ģs▓╔ė├┴╦┴Ēę╗ĘNĖ³▀mæ¬(y©®ng)ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕŲĮ┼_Ą─╦╝┬ĘŻ║Ž╚ł╠(zh©¬)ąą▀^×VŠ█╝»▓┘ū„Ż¼į┘╗∙ė┌Š█╝»Ą─öĄ(sh©┤)ō■(j©┤)ł╠(zh©¬)ąą▀BĮėŻ¼įö╝Üģó┐╝ŻĘŻ«Ż▓╣Ø(ji©”)ĪŻ
ŻČŻ«Ż│Ż╚ŻßŻõŻ’Ż’ŻŻ─Ż┬Ą─Ė─▀M
Ż╚ŻßŻõŻ’Ż’ŻŻ─Ż┬ė┌Ż▓Ż░Ż▒Ż▒─Ļßśī”Ųõ╝▄śŗ(g©░u)╠ß│÷┴╦ā╔ĘN▀BĮėā×(y©Łu)╗»╝╝ąg(sh©┤)║═ā╔ĘNŠ█╝»ā×(y©Łu)╗»╝╝ąg(sh©┤)ĪŻ
ā╔ĘN▀BĮėā×(y©Łu)╗»Ą─║╦ą─╦╝ŽļČ╝╩Ū▒M┐╔─▄ĄžīóöĄ(sh©┤)ō■(j©┤)Ą─╠Ä└Ē═Ų╚ļöĄ(sh©┤)ō■(j©┤)Äņīėł╠(zh©¬)ąąŻ¼Ą┌Ż▒ĘNā×(y©Łu)╗»ĘĮ╩Į╩ŪĖ∙ō■(j©┤)▒Ē┼c▒Ēų«ķgĄ─▀BĮėĻP(gu©Īn)ŽĄŻ¼═©▀^öĄ(sh©┤)ō■(j©┤)ŅA(y©┤)ĘųĮŌŻ¼╩╣ģó┼c▀BĮėĄ─öĄ(sh©┤)ō■(j©┤)▒M┐╔─▄Ęų▓╝į┌═¼ę╗öĄ(sh©┤)ō■(j©┤)Äņā╚(n©©i)Ż©ģóššĘųĮŌĘ©Ż®Ż¼Å─Č°īŹ¼F(xi©żn)īó▀BĮė▓┘ū„Ž┬ē║▀MöĄ(sh©┤)ō■(j©┤)Äņā╚(n©©i)ł╠(zh©¬)ąąŻ¼įō╦ŃĘ©Ą─╚▒³c╩Ūæ¬(y©®ng)ė├ł÷Š░ėąŽ▐Ż¼ų╗▀mė├ė┌µ£╩Į▀BĮėŻ¼Ą┌Ż▓ĘN▀BĮėĘĮ╩Į╩Ūßśī”ÅV▓ź╩Į▀BĮėČ°įO(sh©©)ėŗĄ─Ż¼į┌ł╠(zh©¬)ąą▀BĮėŪ░Ż¼Ž╚į┌öĄ(sh©┤)ō■(j©┤)Äņā╚(n©©i)×ķ├┐Åłģó┼c▀BĮėĄ─ŠS▒ĒĮ©┴óę╗Åł┼RĢr▒ĒŻ¼╩╣Ą├▀BĮė▓┘ū„▒M┐╔─▄į┌öĄ(sh©┤)ō■(j©┤)Äņā╚(n©©i)ł╠(zh©¬)ąąŻ¼įō╦ŃĘ©Ą─╚▒³c╩Ū▌^ČÓĄ─ŠW(w©Żng)Įj(lu©░)é„▌ö║═┤┼▒PŻ╔Ż»ŻŽ▓┘ū„ĪŻ
ā╔ĘNŠ█╝»ā×(y©Łu)╗»╝╝ąg(sh©┤)Ęųäe╩Ū▀BĮė║¾Š█╝»║═▀BĮėŪ░Š█╝»Ż¼Ū░š▀╩Ūł╠(zh©¬)ąą═ĻŻęŻÕŻõŻ§ŻŃŻÕČ╦▀BĮė║¾Ż¼ų▒Įėī”Ę¹║ŽŚl╝■Ą─ėøõøł╠(zh©¬)ąąŠ█╝»▓┘ū„Ż╗║¾š▀╩Ūīó╦∙ėąöĄ(sh©┤)ō■(j©┤)Ž╚į┌öĄ(sh©┤)ō■(j©┤)Äņīėł╠(zh©¬)ąąŠ█╝»▓┘ū„Ż¼╚╗║¾╗∙ė┌Š█╝»öĄ(sh©┤)ō■(j©┤)ł╠(zh©¬)ąą▀BĮė▓┘ū„Ż¼▓óīó▓╗Ę¹║ŽŚl╝■Ą─Š█╝»öĄ(sh©┤)ō■(j©┤)ū÷£pĘ©▓┘ū„Ż¼įōĘĮ╩Į▀mė├Ą─Śl╝■ėąŽ▐Ż¼ų„ę¬ė├ė┌ģó┼c▀BĮė║═Š█╝»Ą─┴ąĄ─╗∙öĄ(sh©┤)ŽÓ│╦║¾ąĪė┌▒ĒėøõøöĄ(sh©┤)Ą─ŪķørĪŻ
┐éĄ─üĒ┐┤Ż¼Ż╚ŻßŻõŻ’Ż’ŻŻ─Ż┬Ą─ā×(y©Łu)╗»╝╝ąg(sh©┤)┤¾Č╝ŠųŽ▐ąį▌^ÅŖŻ¼ī”ė┌Å═(f©┤)ļsĄ─▀BĮė▓┘ū„Ż©╚ńŁh(hu©ón)ą╬▀BĮėĄ╚Ż®╚į▓╗─▄Ž┬═Ųų┴öĄ(sh©┤)ō■(j©┤)Äņīėł╠(zh©¬)ąąŻ¼▓ó╬┤Å─Ė∙▒Š╔ŽĮŌøQŲõąį─▄å¢Ņ}ĪŻ
ŻĘ Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ║═ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņ╝╝ąg(sh©┤)Ą─╚┌║Ž
ŠC╔Ž╦∙╩÷Ż¼«öŪ░蹊┐┤¾Č╝╝»ųąė┌╣”─▄╗“╠žąįĄ─ęŲų▓Ż¼╝┤Å─ę╗éĆŲĮ┼_īW(xu©”)┴Ģ(x©¬)ą┬Ą─╝╝ąg(sh©┤)Ż¼ĄĮ┴Ēę╗ŲĮ┼_ųžą┬īŹ¼F(xi©żn)║═╝»│╔Ż¼╬┤╔µ╝░ł╠(zh©¬)ąą║╦ą─Ż¼ę“┤╦ę▓ø]ėąÅ─Ė∙▒Š╔ŽĮŌøQ┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷å¢Ņ}Ż¼Ķbė┌┤╦Ż¼ųąć°╚╦├±┤¾īW(xu©”)Ė▀ąį─▄öĄ(sh©┤)ō■(j©┤)ÄņīŹ“×╩ęĄ─蹊┐ąĪĮM▓╔╚Ī┴╦┴Ēę╗ĘN╦╝┬ĘŻ║Å─öĄ(sh©┤)ō■(j©┤)Ą─ĮM┐Ś║═▓ķįāĄ─ł╠(zh©¬)ąąā╔éĆ║╦ą─īė┤╬╚ļ╩ųŻ¼╚┌║ŽĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņ║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕā╔ĘN╝╝ąg(sh©┤)Ż¼įO(sh©©)ėŗĖ▀ąį─▄Ą─┐╔öUš╣Ą─│ķŽ¾öĄ(sh©┤)ō■(j©┤)é}Äņ▓ķįā╠Ä└Ē┐“╝▄Ż¼įō┐“╝▄į┌ų¦│ųĖ▀Č╚┐╔öUš╣Ą─═¼ĢrŻ¼ėųŠ▀ėąĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─ąį─▄Ż¼╬ęéāłFĻĀćLįć▀^ā╔éĆ蹊┐ĘĮŽ“Ż║
Ż©Ż▒Ż®ĮĶĶbŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─╦╝ŽļŻ¼╩╣ŻŽŻ╠Ż┴Żą▓ķįāĄ─╠Ä└Ē─▄Ž±Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕę╗śėĖ▀Č╚┐╔öUš╣Ż©Ż╠ŻķŻŅŻÕŻßŻ“Ż─Ż┬įŁą═Ż®Ż╗
Ż©Ż▓Ż®└¹ė├ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─╝╝ąg(sh©┤)Ż¼╩╣Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕį┌╠Ä└ĒŻŽŻ╠Ż┴Żą▓ķįāĢrŻ¼▒ŲĮ³ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─ąį─▄Ż©Ż─Ż§ŻĒŻŌŻ’įŁą═Ż®ĪŻ
ŻĘŻ«Ż▒ Ż╠ŻķŻŅŻÕŻßŻ“Ż─Ż┬
Ż╠ŻķŻŅŻÕŻßŻ“Ż─Ż┬ó┘įŁą═ŽĄĮy(t©»ng)ø]ėąų▒Įė▓╔ė├╗∙ė┌▀BĮėĄ─ąŪą═─Żą═Ż©č®╗©─Żą═Ż®Ż¼Č°╩Ūī”Ųõ▀Mąą┴╦Ė─įņŻ¼įO(sh©©)ėŗ┴╦öUš╣ąįĖ³║├Ą─Īó╗∙ė┌Æ▀├ĶĄ─¤o▀BĮėč®╗©─Żą═Ż╩ŻŲŻėŻėŻ©Ż╩Ż’ŻķŻŅ¬▓ŻŲŻ“ŻÕŻÕŻėŻŅŻ’Ż„ŻµŻņŻßŻļŻÕŻėŻŃŻĶŻÕŻĒŻßŻ®Ż¼įō─Żą═Ą─įO(sh©©)ėŗĮĶĶb┴╦Ę║ĻP(gu©Īn)ŽĄ─Żą═Ą─╦╝ŽļŻ¼▓╔ė├īė┤╬ŠÄ┤a╝╝ąg(sh©┤)Ż█Ż┤Ż░Ż▌īóŠS▒Ēīė┤╬ą┼Žóē║┐s▀M╩┬īŹ▒ĒŻ¼╩╣Ą├╩┬īŹ▒Ē┐╔ęį¬Ü┴ół╠(zh©¬)ąąŠS▒Ē╔ŽĄ─ų^į~┼ąöÓĪóŠ█╝»Ą╚▓┘ū„Ż¼Å─Č°╩╣▀BĮėĄ─öĄ(sh©┤)ō■(j©┤)į┌┤¾ęÄ(gu©®)─ŻÖC╚║╔ŽīŹ¼F(xi©żn)Šų▓┐ąįŻ¼Ž¹│²┴╦▀BĮė▓┘ū„Ż¼łDŻ┤╩Ūę╗éĆąŪą═─Żą═║═¤o▀BĮėč®╗©─Żą═Ą─ī”æ¬(y©®ng)╩ŠęŌłDĪŻ
į┌ł╠(zh©¬)ąąīė┤╬╔ŽŻ¼Ż╠ŻķŻŅŻÕŻßŻ“Ż─Ż┬╬³╚Ī┴╦Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╠Ä└Ē─Ż╩ĮĄ─įO(sh©©)ėŗ╦╝ŽļŻ¼īóöĄ(sh©┤)ō■(j©┤)é}Äņ▓ķįāĄ─╠Ä└Ē│ķŽ¾×ķŻįŻ“ŻßŻŅŻ¾ŻµŻ’Ż“ŻĒĪóŻęŻÕŻõŻ§ŻŃŻÕĪóŻ═ŻÕŻ“ŻńŻÕŻ│éĆ▓┘ū„Ż©ŻįŻęŻ═ł╠(zh©¬)ąą─Żą═Ż®Ż║
Ż©Ż▒Ż®ŻįŻ“ŻßŻŅŻ¾ŻµŻ’Ż“ŻĒŻ¼ų„╣Ø(ji©”)³cī”▓ķįā▀MąąŅA(y©┤)╠Ä└ĒŻ¼īó▓ķįāųąū„ė├ė┌ŠS▒ĒĄ─▓┘ū„Ż©ų„ę¬╩Ūų^į~┼ąöÓŻ¼ŻńŻ“Ż’Ż§Ż¬▓ŻŌŻ∙Š█╝»▓┘ū„Ą╚Ż®▐D(zhu©Żn)ōQ×ķ╩┬īŹ▒Ē╔ŽĄ─▓┘ū„Ż╗
Ż©Ż▓Ż®ŻęŻÕŻõŻ§ŻŃŻÕŻ¼├┐éĆöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c▓󹹥žÆ▀├ĶĪóŠ█╝»▒ŠĄžöĄ(sh©┤)ō■(j©┤)Ż¼╚╗║¾īó╠Ä└ĒĮY(ji©”)╣¹ĘĄ╗žĮoų„╣Ø(ji©”)³cŻ╗
Ż©Ż│Ż®Ż═ŻÕŻ“ŻńŻÕŻ¼ų„╣Ø(ji©”)³cī”Ė„éĆöĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³cĘĄ╗žĄ─ĮY(ji©”)╣¹▀Mąą║Ž▓óŻ¼▓ół╠(zh©¬)ąą║¾└m(x©┤)Ą─▀^×VĪó┼┼ą“Ą╚▓┘ū„Ż¼╗∙ė┌ŻįŻęŻ═ł╠(zh©¬)ąą─Żą═Ż¼▓ķįā┐╔ęįäØĘų×ķ▒ŖČÓ¬Ü┴óĄ─ūė╚╬äš(w©┤)į┌┤¾ęÄ(gu©®)─ŻÖC╚║╔Ž▓óąął╠(zh©¬)ąąŻ¼ł╠(zh©¬)ąą▀^│╠ųąŻ¼╚╬║╬╩¦öĪūė╚╬äš(w©┤)Č╝┐╔ęįį┌ŲõéõĘ▌╣Ø(ji©”)³cųžą┬ł╠(zh©¬)ąąŻ¼Å─Č°½@Ą├▌^║├Ą─╚▌Õe─▄┴”ĪŻŻ╠ŻķŻŅŻÕŻßŻ“Ż─Ż┬Ą─ł╠(zh©¬)ąą┤·ārų„ę¬╚ĪøQė┌ī”╩┬īŹ▒ĒĄ─ŻęŻÕŻõŻ§ŻŃŻÕŻ©ų„ę¬╩ŪÆ▀├ĶŻ®▓┘ū„Ż¼ę“┤╦Ż¼Ż╠ŻķŻŅŻÕŻßŻ“Ż─Ż┬┐╔ęį½@Ą├Į³║§ŠĆąįĄ─┤¾ęÄ(gu©®)─Ż┐╔öUš╣─▄┴”ĪŻ
īŹ“×▒Ē├„Ż¼Ųõąį─▄▒╚Ż╚ŻßŻõŻ’Ż’ŻŻ─Ż┬ų┴╔┘Ė▀│÷ę╗éĆöĄ(sh©┤)┴┐╝ēĪŻ
Ż╠ŻķŻŅŻÕŻßŻ“Ż─Ż┬Ą─öUš╣─▄┴”Īó╚▌Õe─▄┴”║═Ė▀ąį─▄į┌ė┌ŲõŪ╔├ŅĄžĮY(ji©”)║Ž┴╦ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņ╝╝ąg(sh©┤)Ż©īė┤╬ŠÄ┤a╝╝ąg(sh©┤)ĪóĘ║ĻP(gu©Īn)ŽĄ─Ż╩ĮŻ®║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╠Ä└Ē─Ż╩ĮĄ─įO(sh©©)ėŗ╦╝ŽļŻ¼ė╔┤╦Ż¼┐╔ęį┐┤│÷Ż¼ĮY(ji©”)║ŽĘĮ╩ĮĄ─▓╗═¼┐╔ęįī¦(d©Żo)ų┬ŽĄĮy(t©»ng)─▄┴”Ą─Š▐┤¾▓Ņ«ÉĪŻ
ŻĘ.Ż▓Ż─Ż§ŻĒŻŌŻ’
Ż─Ż§ŻĒŻŌŻ’Ą─║╦ą─╦╝Žļ╩ŪĖ∙ō■(j©┤)Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─“▀^×VŻŁŻŠŠ█╝»”Ą─╠Ä└Ē─Ż╩ĮŻ¼ī”ŻŽŻ╠Ż┴Żą▓ķįāĄ─╠Ä└Ē▀MąąĖ─įņŻ¼╩╣Ųõ▀mæ¬(y©®ng)ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ┐“╝▄Ż¼Ż─Ż§ŻĒŻŌŻ’▓╔ė├┴╦ŅÉ╦Ųė┌Ż╠ŻķŻŅŻÕŻßŻ“Ż─Ż┬Ą─öĄ(sh©┤)ō■(j©┤)ĮM┐Ś─Ż╩Į———└¹ė├īė┤╬ŠÄ┤a╝╝ąg(sh©┤)īóŠS▒Ēą┼Žóē║┐s▀M╩┬īŹ▒ĒŻ¼ģ^(q©▒)äeį┌ė┌Ż─Ż§ŻĒŻŌŻ’▓╔ė├┴╦Ė³╝ėėąą¦Ą─ŠÄ┤aĘĮ╩ĮŻ¼▓óßśī”Ż╚ŻßŻõŻ’Ż’ŻĘų▓╝╩Į╬─╝■ŽĄĮy(t©»ng)Ą─╠ž³cī”öĄ(sh©┤)ō■(j©┤)Ą─┤µā”▀Mąą┴╦ā×(y©Łu)╗»ĪŻ
į┌ł╠(zh©¬)ąąīė┤╬╔ŽŻ¼Ż─Ż§ŻĒŻŌŻ’ī”Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ┐“╝▄▀Mąą┴╦öUš╣Ż¼įO(sh©©)ėŗ┴╦ą┬Ą─ŻŽŻ╠Ż┴Żą▓ķįā╠Ä└Ē┐“╝▄———ŻįŻ═ŻęŻąŻ©ŻįŻ“ŻßŻŅŻ¾ŻµŻ’Ż“ŻĒŻŁŻŠŻ═ŻßŻŻŁŻŠŻęŻÕŻõŻ§ŻŃŻÕŻŁŻŠŻąŻ’Ż¾Ż¶ŻŻ“Ż’¬▓ŻŃŻÕŻ¾Ż¾Ż®╠Ä└Ē┐“╝▄Ż©╚ńłDŻĄ╦∙╩ŠŻ®Ż¼į┌įō┐“╝▄ųąŻ¼ų„╣Ø(ji©”)³c╩ūŽ╚ī”▓ķįā▀Mąą▐D(zhu©Żn)ōQŻ¼╔·│╔ę╗éĆŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╚╬äš(w©┤)üĒł╠(zh©¬)ąą▓ķįāŻ¼įō╚╬äš(w©┤)į┌Ż═ŻßŻļAČ╬ęį┴„╦«ŠĆĘĮ╩ĮÆ▀├ĶĪóŠ█╝»▒ŠĄžöĄ(sh©┤)ō■(j©┤)Ż¼▓óų╗īó▒ŠĄžĄ─Š█╝»öĄ(sh©┤)ō■(j©┤)é„ų┴ŻęŻÕ¬▓ŻõŻ§ŻŃŻÕļAČ╬Ż¼üĒ▀MąąöĄ(sh©┤)ō■(j©┤)Ą─║Ž▓ó╝░Š█╝»Īó┼┼ą“Ą╚▓┘ū„Ż¼į┌ŻąŻ’Ż¾Ż¶ŻŻ“Ż’ŻŃŻÕŻ¾Ż¾ļAČ╬Ż¼ų„╣Ø(ji©”)³cį┌öĄ(sh©┤)ō■(j©┤)╣Ø(ji©”)³c╔Žé„Ą─Š█╝»öĄ(sh©┤)ō■(j©┤)ų«╔Žł╠(zh©¬)ąą▀BĮė▓┘ū„Ż¼īŹ“×▒Ē├„Ż¼Ż─Ż§ŻĒŻŌŻ’ąį─▄▀h│¼Ż╚ŻßŻõŻ’Ż’Ż║═Ż╚ŻßŻõŻ’Ż’ŻŻ─Ż┬ĪŻ
ė╔┤╦╬ęéā┐╔ęį┐┤│÷Ż¼Å═(f©┤)ļsĄ─ŻŽŻ╠Ż┴Żą▓ķįāį┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ┐“╝▄Ž┬ę▓┐╔ęį½@Ą├ĮėĮ³╔§ų┴│¼įĮĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņĄ─ąį─▄Ż¼ŲõĻP(gu©Īn)µIį┌ė┌╚ń║╬ėąą¦ĄžĮY(ji©”)║ŽĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņ║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕā╔ĘN╝╝ąg(sh©┤)Ż¼āHāH═Ż┴¶ė┌▒ĒīėĄ─ęŲų▓║═╝»│╔╩ŪļyęįÅ─Ė∙▒Š╔ŽĮŌøQ┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷å¢Ņ}Ą─Ż¼╬ęéāį┌╬─½IŻ█Ż┤Ż▒Ż▌Ą─蹊┐ųąę▓š╣╩Š┴╦╚ń║╬╗∙ė┌▀@ĘNą┬Ą─öĄ(sh©┤)ō■(j©┤)ĮM┐ŚĘĮ╩ĮüĒīŹ¼F(xi©żn)Å═(f©┤)ļsĘų╬÷▓┘ū„———░┘Ęų╬╗öĄ(sh©┤)Ą─Ė▀ą¦ėŗ╦Ńå¢Ņ}ĪŻ
Ż╠ŻķŻŅŻÕŻßŻ“Ż─Ż┬║═Ż─Ż§ŻĒŻŌŻ’ļm╚╗╗∙▒Š┐╔ęį▀_ĄĮŅA(y©┤)Ų┌Ą─įO(sh©©)ėŗ─┐ś╦Ż¼Ą½ā╔š▀Č╝ąĶę¬ī”öĄ(sh©┤)ō■(j©┤)▀MąąŅA(y©┤)╠Ä└ĒŻ¼ŲõŅA(y©┤)╠Ä└Ē┤·ār╩ŪŲš═©╝ė▌dĢrķgĄ─ŻĘ▒Čū¾ėęŻ¼ę“┤╦Ųõæ¬(y©®ng)ī”ūā╗»Ą──▄┴”▀Ć▌^╚§Ż¼▀@╩Ū╬ęéā╬┤üĒĄ─╣żū„ā╚(n©©i)╚▌ų«ę╗ĪŻ
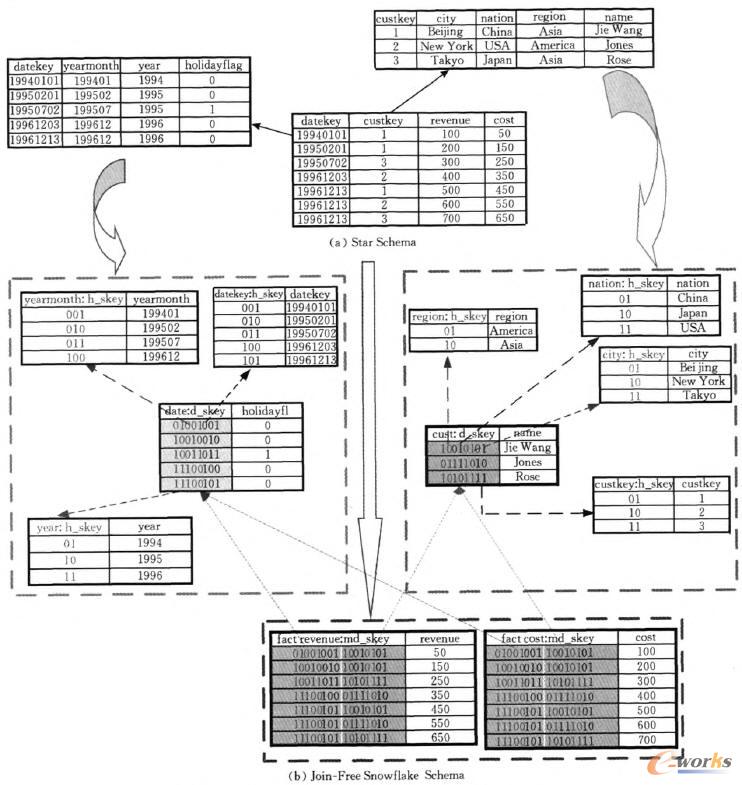
łDŻ┤ ī”▒╚Ż║ę╗éĆĄõą═ąŪą═─Żą═┼cŲõī”æ¬(y©®ng)Ą─¤o▀BĮėč®╗©─Żą═
ŻĖ 蹊┐š╣═¹
«öŪ░Ż│éĆĘĮŽ“Ą─蹊┐Č╝▓╗─▄═Ļ├└ĄžĮŌøQ┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷å¢Ņ}Ż¼ę▓Š═ęŌ╬Čų°├┐éĆĘĮŽ“Č╝ėąśOŠ▀╠¶æ(zh©żn)ąįĄ─╣żū„Ą╚┤²ų°╬ęéāĪŻ
ī”▓óąąöĄ(sh©┤)ō■(j©┤)ÄņüĒšfŻ¼ŲõöUš╣ąįĮ³─Ļļmėą▌^┤¾Ė─╔ŲŻ©╚ńŻŪŻ“ŻÕŻÕŻŅŻŻņŻ§ŻĒ║═Ż┴Ż¾Ż¶ŻÕŻ“Ż─ŻßŻ¶ŻßČ╝╩Ū├µŽ“ŻąŻ┬╝ēöĄ(sh©┤)ō■(j©┤)ęÄ(gu©®)─ŻįO(sh©©)ėŗķ_░l(f©Ī)Ą─Ż®Ż¼Ą½ŠÓļx┤¾öĄ(sh©┤)ō■(j©┤)Ą─Ęų╬÷ąĶŪ¾╚įėą▌^┤¾▓ŅŠÓŻ¼ę“┤╦Ż¼╚ń║╬Ė─╔Ų▓óąąöĄ(sh©┤)ō■(j©┤)ÄņĄ─öUš╣─▄┴”╩Ūę╗ĒŚĘŪ│Żėą╠¶æ(zh©żn)Ą─╣żū„Ż¼įōĒŚčąŠ┐īó═¼Ģr╔µ╝░öĄ(sh©┤)ō■(j©┤)ę╗ų┬ąįģf(xi©”)ūhĪó╚▌ÕeąįĪóąį─▄Ą╚öĄ(sh©┤)ō■(j©┤)ÄņŅI(l©½ng)ė“Ą─ųTČÓĘĮ├µĪŻ
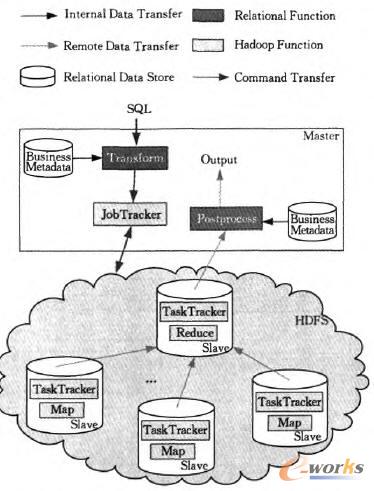
łDŻĄ Ż─Ż§ŻĒŻŌŻ’╝▄śŗ(g©░u)Ż©╔Ņ╗ę╔½▓┐Ęų╩Ūą┬į÷─ŻēKŻ¼╩ŻėÓ▓┐Ęų╩ŪŻ╚ŻßŻõŻ’Ż’ŻūįĦ─ŻēKŻ®
╗ņ║Ž╩Į╝▄śŗ(g©░u)ĘĮ░Ė┐╔ęįÅ═(f©┤)ė├ęčėą│╔╣¹Ż¼ķ_░l(f©Ī)┴┐▌^ąĪŻ¼Ą½ų╗╩Ū║åå╬Ą─╣”─▄╝»│╔╦Ų║§▓ó▓╗─▄ėąą¦ĮŌøQ┤¾öĄ(sh©┤)ō■(j©┤)Ą─Ęų╬÷å¢Ņ}Ż¼ę“┤╦įōĘĮŽ“▀ĆąĶę¬Ė³╝ė╔Ņ╚ļĄ─蹊┐╣żū„Ż¼▒╚╚ńÅ─öĄ(sh©┤)ō■(j©┤)─Żą═╝░▓ķįā╠Ä└Ē─Ż╩Į╔Ž▀MąąčąŠ┐Ż¼╩╣ā╔š▀─▄▌^ūį╚╗ĄžĮY(ji©”)║ŽŲüĒŻ¼▀@īó╩Ūę╗ĒŚĘŪ│ŻėąęŌ┴xĄ─╣żū„Ż¼ųąć°╚╦├±┤¾īW(xu©”)Ą─Ż─Ż§ŻĒŻŌŻ’ŽĄĮy(t©»ng)╝┤╩Ūį┌╔ŅīėĮY(ji©”)║ŽĘĮŽ“╔Ž┼¼┴”Ą─ę╗éĆ└²ūėĪŻ
ŽÓ▒╚ė┌Ū░ā╔š▀Ż¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─ąį─▄ā×(y©Łu)╗»▀Mš╣čĖ╦┘Ż¼Ųõąį─▄š²ų▓Į▒ŲĮ³ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)ÄņŻ¼įōĘĮŽ“Ą─蹊┐ėųĘų×ķā╔éĆĘĮŽ“Ż║└ĒšōĮńé╚(c©©)ųžė┌└¹ė├ĻP(gu©Īn)ŽĄöĄ(sh©┤)ō■(j©┤)Äņ╝╝ąg(sh©┤)╝░└ĒšōĖ─╔ŲŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─ąį─▄Ż╗╣żśI(y©©)Įńé╚(c©©)ųžė┌╗∙ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕŲĮ┼_ķ_░l(f©Ī)Ė▀ą¦Ą─æ¬(y©®ng)ė├▄ø╝■Ż¼ßśī”öĄ(sh©┤)ō■(j©┤)é}ÄņŅI(l©½ng)ė“Ż¼╬ęéāšJ×ķ╚ńŽ┬ÄūéĆ蹊┐ĘĮŽ“▒╚▌^ųžę¬Ż¼Ūę─┐Ū░蹊┐▀Ć▌^╔┘╔µ╝░Ż║
Ż©Ż▒Ż®ČÓŠSöĄ(sh©┤)ō■(j©┤)Ą─ŅA(y©┤)ėŗ╦ŃŻ¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĖ³ČÓßśī”Ą─╩Ūę╗┤╬ąįĘų╬÷▓┘ū„Ż¼┤¾öĄ(sh©┤)ō■(j©┤)╔ŽĄ─Ęų╬÷▓┘ū„ļm╚╗ļyęįŅA(y©┤)£yŻ¼Ą½é„Įy(t©»ng)Ą─Ęų╬÷Ż¼╚ń╗∙ė┌ł¾▒Ē║═ČÓŠSöĄ(sh©┤)ō■(j©┤)Ą─Ęų╬÷╚įš╝ČÓöĄ(sh©┤)Ż¼ę“┤╦Ż¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕŲĮ┼_ę▓┐╔ęį└¹ė├ŅA(y©┤)ėŗ╦ŃĄ╚╩ųČ╬╝ė┐ņöĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─╦┘Č╚Ż¼╗∙ė┌┤µā”┐šķgĄ─┐╝æ]Ż©┐╔ęįŽļŽ¾Ż¼į┌▒¼š©öĄ(sh©┤)ō■(j©┤)ų«╔Žėŗ╦ŃöĄ(sh©┤)ō■(j©┤)┴óĘĮ¾wąĶę¬ĖČ│÷░║┘FĄ─┤µā”┐šķg┤·ārŻ®Ż¼Ż═ŻŽŻ╠Ż┴Żą╩Ū▓╗┐╔╚ĪĄ─Ż¼╗ņ║Ž╩ĮŻŽŻ╠Ż┴ŻąŻ©Ż╚ŻŽŻ╠Ż┴ŻąŻ®æ¬(y©®ng)įō╩ŪŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕŲĮ┼_Ą─ā×(y©Łu)▀xŻŽŻ╠Ż┴ŻąīŹ¼F(xi©żn)ĘĮ░ĖŻ¼Š▀¾w蹊┐╚ńŻ║ó┘╗∙ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ┐“╝▄Ą─Ė▀ą¦Ż├Ż§ŻŌŻÕėŗ╦Ń╦ŃĘ©Ż╗ó┌╬’╗»ęĢłDĄ─▀xō±å¢Ņ}Ż¼╝┤╬’╗»──ą®öĄ(sh©┤)ō■(j©┤)Ż╗ó█▓╗═¼Ęų╬÷▓┘ū„Ą─╬’╗»╩ųČ╬Ż©▒╚╚ńŅA(y©┤)£yĘų╬÷▓┘ū„Ą─╬’╗»Ż®╝░╚ń║╬╗∙ė┌╬’╗»Ą─öĄ(sh©┤)ō■(j©┤)▀MąąÅ═(f©┤)ļsĘų╬÷▓┘ū„Ż©╚ńöĄ(sh©┤)ō■(j©┤)įLå¢┬ĘÅĮĄ─▀xō±å¢Ņ}Ż®ĪŻ
Ż©Ż▓Ż®Ė„ĘNĘų╬÷▓┘ū„Ą─▓óąą╗»īŹ¼F(xi©żn)Ż¼┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷ąĶę¬Ė▀ą¦Ą─Å═(f©┤)ļsĮy(t©»ng)ėŗĘų╬÷╣”─▄Ą─ų¦│ųŻ¼Ż╔Ż┬Ż═īóķ_į┤Įy(t©»ng)ėŗĘų╬÷▄ø╝■Żę╝»│╔▀MŻ╚ŻßŻõŻ’Ż’ŻŲĮ┼_Ż¼į÷ÅŖ┴╦Ż╚ŻßŻõŻ’Ż’ŻĄ─Įy(t©»ng)ėŗĘų╬÷╣”─▄Ż¼Ą½Ė³Š▀╠¶æ(zh©żn)ąįĄ─å¢Ņ}╩ŪŻ¼╚ń║╬╗∙ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ┐“╝▄įO(sh©©)ėŗ┐╔▓óąą╗»Ą─ĪóĖ▀ą¦Ą─Ęų╬÷╦ŃĘ©Ż¼ė╚ŲõąĶę¬ÅŖš{(di©żo)Ą─╩ŪŻ¼Ķbė┌ęŲäėöĄ(sh©┤)ō■(j©┤)Ą─Š▐┤¾┤·ārŻ¼▀@ą®╦ŃĘ©æ¬(y©®ng)╗∙ė┌ęŲäėėŗ╦ŃĄ─ĘĮ╩ĮüĒīŹ¼F(xi©żn)ĪŻ
Ż©Ż│Ż®▓ķįā╣▓ŽĒŻ¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ▓╔ė├▓Į▓Į╬’╗»Ą─╠Ä└ĒĘĮ╩ĮŻ¼ī¦(d©Żo)ų┬ŲõŻ╔Ż»ŻŽ┤·ār╝░ŠW(w©Żng)Įj(lu©░)é„▌ö┤·ār▌^Ė▀Ż¼ę╗ĘNėąą¦Ą─ĮĄĄ═įō┤·ārĄ─ĘĮ╩Į╩Ūį┌ČÓéĆ▓ķįāķg╣▓ŽĒ╬’╗»Ą─ųąķgĮY(ji©”)╣¹Ż¼╔§ų┴įŁ╩╝öĄ(sh©┤)ō■(j©┤)Ż¼ęįĘųöé┤·ār▓ó▒▄├ŌųžÅ═(f©┤)ėŗ╦ŃŻ¼ę“┤╦╚ń║╬į┌ČÓ▓ķįāķg╣▓ŽĒųąķgĮY(ji©”)╣¹īó╩Ūę╗ĒŚĘŪ│ŻėąīŹļHæ¬(y©®ng)ė├ārųĄĄ─蹊┐ĪŻ
Ż©Ż┤Ż®ė├æ¶Įė┐┌Ż¼╚ń║╬▌^║├ĄžīŹ¼F(xi©żn)öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─š╣╩Š║═▓┘ū„Ż¼ė╚Ųõ╩ŪÅ═(f©┤)ļsĘų╬÷▓┘ū„Ą─ų▒ė^š╣╩ŠĪŻ
Ż©ŻĄŻ®Ż╚ŻßŻõŻ’Ż’Ż┐╔┐┐ąį蹊┐Ż¼«öŪ░Ż╚ŻßŻõŻ’Ż’Ż▓╔ė├ų„Å─ĮY(ji©”)śŗ(g©░u)Ż¼ė╔┤╦øQČ©┴╦ų„╣Ø(ji©”)³cę╗Ą®╩¦ą¦Ż¼īóĢ■│÷¼F(xi©żn)š¹éĆŽĄĮy(t©»ng)╩¦ą¦Ą─Šų├µŻ¼ę“┤╦Ż¼╚ń║╬į┌▓╗ė░ĒæŻ╚ŻßŻõŻ’Ż’Ż¼F(xi©żn)ėąīŹ¼F(xi©żn)Ą─Ū░╠ߎ┬Ż¼╠ßĖ▀ų„╣Ø(ji©”)³cĄ─┐╔┐┐ąįŻ¼īó╩Ūę╗ĒŚŪąīŹĄ─蹊┐ĪŻ
Ż©ŻČŻ®öĄ(sh©┤)ō■(j©┤)ē║┐sŻ¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ─ł╠(zh©¬)ąą─Żą═øQČ©┴╦Ųõąį─▄╚ĪøQė┌Ż╔Ż»ŻŽ║═ŠW(w©Żng)Įj(lu©░)é„▌ö┤·ārŻ¼╬─½IŻ█Ż▒Ż▒Ż▌į┌▒╚▌^▓óąąöĄ(sh©┤)ō■(j©┤)Äņ║═Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╗∙ė┌ē║┐söĄ(sh©┤)ō■(j©┤)Ą─ąį─▄ĢrŻ¼░l(f©Ī)¼F(xi©żn)ē║┐s╝╝ąg(sh©┤)▓óø]ėąĖ─╔ŲŻ╚ŻßŻõŻ’Ż’ŻĄ─ąį─▄ó┘Ż¼Ą½īŹļHŪķør╩ŪŻ¼ē║┐s▓╗āH┐╔ęį╣Ø(ji©”)╩Ī┐šķgŻ¼╣Ø(ji©”)╩ĪŻ╔Ż»ŻŽ╝░ŠW(w©Żng)Įj(lu©░)ĦīÆŻ¼▀Ć┐╔ęį└¹ė├«öŪ░Ż├ŻąŻšĄ─ČÓ║╦▓óąąėŗ╦Ń─▄┴”Ż¼ŲĮ║ŌŻ╔Ż»ŻŽ║═Ż├ŻąŻšĄ─╠Ä└Ē─▄┴”Ż¼Å─Č°╠ßĖ▀ąį─▄Ż¼▒╚╚ń▓óąąöĄ(sh©┤)ō■(j©┤)Äņ└¹ė├öĄ(sh©┤)ō■(j©┤)ē║┐s║¾Ż¼ąį─▄═∙═∙┐╔ęį┤¾Ę∙╠ß╔²Ż¼┤╦║¾Ż¼╬─½IŻ█Ż▓ŻĄĪóŻ▓ŻČŻ▌Ą─蹊┐│╔╣”Ąž└¹ė├ē║┐s╝╝ąg(sh©┤)╠ß╔²┴╦Ż╚ŻßŻõŻ’Ż’ŻĄ─ąį─▄Ż¼Ą½▀@ą®čąŠ┐Č╝╗∙ė┌Ė„ūįĄ─┤µā”─Żą═Ż¼Č°ĘŪŻ╚ŻßŻõŻ’Ż’ŻĄ──¼šJ┤µā”─Ż╩ĮŻ©ąą┤µ─Żą═Ż®Ż¼ę“┤╦Ż¼Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╔ŽĄ─ē║┐s╩Ūę╗éĆ╔ą┤²čąŠ┐Ą─ųžę¬å¢Ņ}ĪŻ
Ż©ŻĘŻ®ČÓŠS╦„ę²čąŠ┐Ż¼╚ń║╬╗∙ė┌Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ┐“╝▄īŹ¼F(xi©żn)ČÓŠS╦„ę²Ż¼╝ė┐ņČÓŠSöĄ(sh©┤)ō■(j©┤)Ą─Öz╦„╦┘Č╚ĪŻ
«ö╚╗Ż¼╚įėąįSČÓŲõ╦³čąŠ┐╣żū„Ż¼▒╚╚ń╗∙ė┌Ż╚ŻßŻõŻ’Ż’ŻĄ─īŹĢröĄ(sh©┤)ō■(j©┤)Ęų╬÷ĪóÅŚąį蹊┐ĪóöĄ(sh©┤)ō■(j©┤)ę╗ų┬ąį蹊┐Ą╚Ż¼Č╝╩ŪĘŪ│Żėą╠¶æ(zh©żn)║═ęŌ┴xĄ─蹊┐Ż¼Ž▐ė┌Ų¬Ę∙╬ęéā▓╗į┘┘ś╩÷ĪŻ
Ż╣ ┐éĮY(ji©”)
▒Š╬─ī”┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ą─ų„┴„īŹ¼F(xi©żn)ŲĮ┼_Ż©▓óąąöĄ(sh©┤)ō■(j©┤)ÄņĪóŻ═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕ╝░ā╔š▀Ą─╗ņ║Ž╝▄śŗ(g©░u)Ż®▀Mąą┴╦įuārĪóÜw╝{┼cī”▒╚Ęų╬÷Ż¼ĮķĮB┴╦ųąć°╚╦├±┤¾īW(xu©”)į┌┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷ĘĮ├µĄ─蹊┐Ż¼▓óī”«öŪ░Ą─蹊┐▀Mąą┴╦Üw╝{Ż¼Å─╬─ųą┐╔ęį┐┤│÷Ż¼├┐ĘNĘų╬÷ŲĮ┼_Č╝▓╗╩Ū═Ļ├└Ą─Ż¼į┌┤¾öĄ(sh©┤)ō■(j©┤)├µŪ░Ż¼Č╝ėą║▄ķLĄ─┬Ęę¬ū▀Ż¼┤¾öĄ(sh©┤)ō■(j©┤)Ęų╬÷Ų╚╩╣╬ęéāĘ┤╦╝é„Įy(t©»ng)Ą─öĄ(sh©┤)ō■(j©┤)é}Äņ╝▄śŗ(g©░u)Ż¼╠ōą─ĄžčąŠ┐Ż═ŻßŻŻęŻÕŻõŻ§ŻŃŻÕĄ╚ą┬╔·ŲĮ┼_Ż¼ęįšŠį┌Ė³Ė▀Ą─īė┤╬üĒ╦╝┐╝å¢Ņ}Ż¼Å─Č°šęĄĮ▀mæ¬(y©®ng)Ģr┤·ąĶŪ¾Ą─öĄ(sh©┤)ō■(j©┤)é}Äņ╝▄śŗ(g©░u)ĪŻ
║╦ą─ĻP(gu©Īn)ūóŻ║═ž▓ĮERPŽĄĮy(t©»ng)ŲĮ┼_╩ŪĖ▓╔w┴╦▒ŖČÓĄ─śI(y©©)äš(w©┤)ŅI(l©½ng)ė“ĪóąąśI(y©©)æ¬(y©®ng)ė├Ż¼╠N║Ł┴╦žSĖ╗Ą─ERP╣▄└Ē╦╝ŽļŻ¼╝»│╔┴╦ERP▄ø╝■śI(y©©)äš(w©┤)╣▄└Ē└Ē─ŅŻ¼╣”─▄╔µ╝░╣®æ¬(y©®ng)µ£Īó│╔▒ŠĪóųŲįņĪóCRMĪóHRĄ╚▒ŖČÓśI(y©©)äš(w©┤)ŅI(l©½ng)ė“Ą─╣▄└ĒŻ¼╚½├µ║Ł╔w┴╦Ų¾śI(y©©)ĻP(gu©Īn)ūóERP╣▄└ĒŽĄĮy(t©»ng)Ą─║╦ą─ŅI(l©½ng)ė“Ż¼╩Ū▒ŖČÓųąąĪŲ¾śI(y©©)ą┼Žó╗»Į©įO(sh©©)╩ū▀xĄ─ERP╣▄└Ē▄ø╝■ą┼┘ćŲĘ┼ŲĪŻ
▐D(zhu©Żn)▌dšłūó├„│÷╠ÄŻ║═ž▓ĮERP┘YėŹŠW(w©Żng)http://m.hanmeixuan.com/
▒Š╬─ś╦Ņ}Ż║╝▄śŗ(g©░u)┤¾öĄ(sh©┤)ō■(j©┤)Ż║╠¶æ(zh©żn)Īó¼F(xi©żn)ĀŅ┼cš╣═¹(Ž┬)
▒Š╬─ŠW(w©Żng)ųĘŻ║http://m.hanmeixuan.com/html/support/1112158845.html



▀xą═ųąą─")
¾w“×ųąą─")
«a(ch©Żn)ŲĘ┘Å┘I")
æ(zh©żn)┬į║Žū„")